Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford and Luke Metz and Soumith Chintala
arXiv e-Print archive - 2015 via Local arXiv
Keywords: cs.LG, cs.CV
First published: 2015/11/19 (8 years ago)
Abstract: In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations.
more
less
Alec Radford and Luke Metz and Soumith Chintala
arXiv e-Print archive - 2015 via Local arXiv
Keywords: cs.LG, cs.CV
First published: 2015/11/19 (8 years ago)
Abstract: In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations.













[link]
* DCGANs are just a different architecture of GANs.
* In GANs a Generator network (G) generates images. A discriminator network (D) learns to differentiate between real images from the training set and images generated by G.
* DCGANs basically convert the laplacian pyramid technique (many pairs of G and D to progressively upscale an image) to a single pair of G and D.
### How
* Their D: Convolutional networks. No linear layers. No pooling, instead strided layers. LeakyReLUs.
* Their G: Starts with 100d noise vector. Generates with linear layers 1024x4x4 values. Then uses fractionally strided convolutions (move by 0.5 per step) to upscale to 512x8x8. This is continued till Cx32x32 or Cx64x64. The last layer is a convolution to 3x32x32/3x64x64 (Tanh activation).
* The fractionally strided convolutions do basically the same as the progressive upscaling in the laplacian pyramid. So it's basically one laplacian pyramid in a single network and all upscalers are trained jointly leading to higher quality images.
* They use Adam as their optimizer. To decrease instability issues they decreased the learning rate to 0.0002 (from 0.001) and the momentum/beta1 to 0.5 (from 0.9).
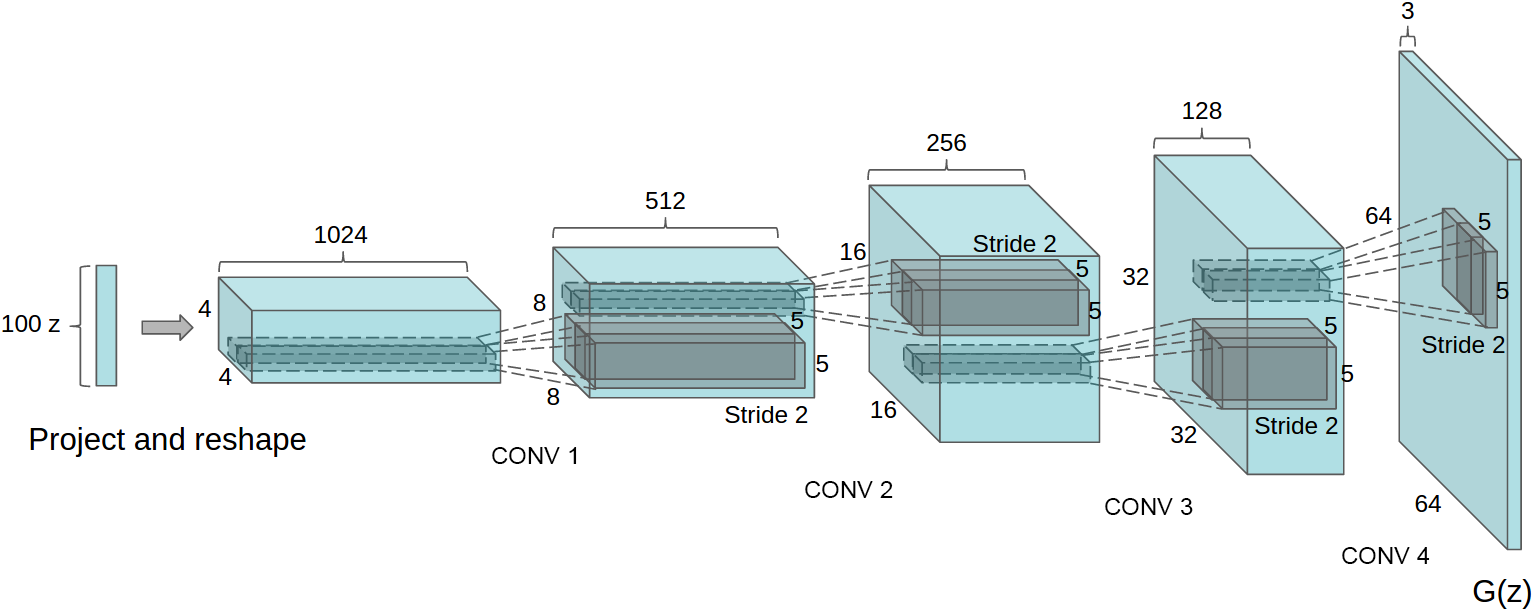
*Architecture of G using fractionally strided convolutions to progressively upscale the image.*
### Results
* High quality images. Still with distortions and errors, but at first glance they look realistic.
* Smooth interpolations between generated images are possible (by interpolating between the noise vectors and feeding these interpolations into G).
* The features extracted by D seem to have some potential for unsupervised learning.
* There seems to be some potential for vector arithmetics (using the initial noise vectors) similar to the vector arithmetics with wordvectors. E.g. to generate mean with sunglasses via `vector(men) + vector(sunglasses)`.
")
*Generated images, bedrooms.*
")
*Generated images, faces.*
### Rough chapter-wise notes
* Introduction
* For unsupervised learning, they propose to use to train a GAN and then reuse the weights of D.
* GANs have traditionally been hard to train.
* Approach and model architecture
* They use for D an convnet without linear layers, withput pooling layers (only strides), LeakyReLUs and Batch Normalization.
* They use for G ReLUs (hidden layers) and Tanh (output).
* Details of adversarial training
* They trained on LSUN, Imagenet-1k and a custom dataset of faces.
* Minibatch size was 128.
* LeakyReLU alpha 0.2.
* They used Adam with a learning rate of 0.0002 and momentum of 0.5.
* They note that a higher momentum lead to oscillations.
* LSUN
* 3M images of bedrooms.
* They use an autoencoder based technique to filter out 0.25M near duplicate images.
* Faces
* They downloaded 3M images of 10k people.
* They extracted 350k faces with OpenCV.
* Empirical validation of DCGANs capabilities
* Classifying CIFAR-10 GANs as a feature extractor
* They train a pair of G and D on Imagenet-1k.
* D's top layer has `512*4*4` features.
* They train an SVM on these features to classify the images of CIFAR-10.
* They achieve a score of 82.8%, better than unsupervised K-Means based methods, but worse than Exemplar CNNs.
* Classifying SVHN digits using GANs as a feature extractor
* They reuse the same pipeline (D trained on CIFAR-10, SVM) for the StreetView House Numbers dataset.
* They use 1000 SVHN images (with the features from D) to train the SVM.
* They achieve 22.48% test error.
* Investigating and visualizing the internals of the networks
* Walking in the latent space
* The performs walks in the latent space (= interpolate between input noise vectors and generate several images for the interpolation).
* They argue that this might be a good way to detect overfitting/memorizations as those might lead to very sudden (not smooth) transitions.
* Visualizing the discriminator features
* They use guided backpropagation to visualize what the feature maps in D have learned (i.e. to which images they react).
* They can show that their LSUN-bedroom GAN seems to have learned in an unsupervised way what beds and windows look like.
* Forgetting to draw certain objects
* They manually annotated the locations of objects in some generated bedroom images.
* Based on these annotations they estimated which feature maps were mostly responsible for generating the objects.
* They deactivated these feature maps and regenerated the images.
* That decreased the appearance of these objects. It's however not as easy as one feature map deactivation leading to one object disappearing. They deactivated quite a lot of feature maps (200) and they objects were often still quite visible or replaced by artefacts/errors.
* Vector arithmetic on face samples
* Wordvectors can be used to perform semantic arithmetic (e.g. `king - man + woman = queen`).
* The unsupervised representations seem to be useable in a similar fashion.
* E.g. they generated images via G. They then picked several images that showed men with glasses and averaged these image's noise vectors. They did with same with men without glasses and women without glasses. Then they performed on these vectors `men with glasses - mean without glasses + women without glasses` to get `woman with glasses

Your comment:
|

|
[link]
# Deep Convolutional Generative Adversarial Nets
## Introduction
* The paper presents Deep Convolutional Generative Adversarial Nets (DCGAN) - a topologically constrained variant of conditional GAN.
* [Link to the paper](https://arxiv.org/abs/1511.06434)
## Benefits
* Stable to train
* Very useful to learn unsupervised image representations.
## Model
* GANs difficult to scale using CNNs.
* Paper proposes following changes to GANs:
* Replace any pooling layers with strided convolutions (for discriminator) and fractional strided convolutions (for generators).
* Remove fully connected hidden layers.
* Use batch normalisation in both generator (all layers except output layer) and discriminator (all layers except input layer).
* Use LeakyReLU in all layers of the discriminator.
* Use ReLU activation in all layers of the generator (except output layer which uses Tanh).
## Datasets
* Large-Scale Scene Understanding.
* Imagenet-1K.
* Faces dataset.
## Hyperparameters
* Minibatch SGD with minibatch size of 128.
* Weights initialized with 0 centered Normal distribution with standard deviation = 0.02
* Adam Optimizer
* Slope of leak = 0.2 for LeakyReLU.
* Learning rate = 0.0002, β1 = 0.5
## Observations
* Large-Scale Scene Understanding data
* Demonstrates that model scales with more data and higher resolution generation.
* Even though it is unlikely that model would have memorized images (due to low learning rate of minibatch SGD).
* Classifying CIFAR-10 dataset
* Features
* Train in Imagenet-1K and test on CIFAR-10.
* Max pool discriminator's convolutional features (from all layers) to get 4x4 spatial grids.
* Flatten and concatenate to get a 28672-dimensional vector.
* Linear L2-SVM classifier trained over the feature vector.
* 82.8% accuracy, outperforms K-means (80.6%)
* Street View House Number Classifier
* Similar pipeline as CIFAR-10
* 22.48% test error.
* The paper contains many examples of images generated by final and intermediate layers of the network.
* Images in the latent space do not show sharp transitions indicating that network did not memorize images.
* DCGAN can learn an interesting hierarchy of features.
* Networks seems to have some success in disentangling image representation from object representation.
* Vector arithmetic can be performed on the Z vectors corresponding to the face samples to get results like `smiling woman - normal woman + normal man = smiling man` visually.
Your comment:
You must log in before you can post this comment!
|


|
[link]
_Objective:_ Propose a more stable set of architectures for training GAN and show that they learn good representations of images for supervised learning and generative modeling. _Dataset:_ [LSUN](http://www.yf.io/p/lsun) and [ImageNet 1k](www.image-net.org/). ## Architecture: Below are the guidelines for making DCGANs. [](https://cloud.githubusercontent.com/assets/17261080/25329644/f3885f7c-28dc-11e7-8895-051124c8ff6c.png) And here is a sample network: [](https://cloud.githubusercontent.com/assets/17261080/25329634/e9c14abc-28dc-11e7-8bed-068f7f7bc78d.png) A tensorflow implementation can be found [here](https://github.com/carpedm20/DCGAN-tensorflow) along with an [online demo](https://carpedm20.github.io/faces/). ## Results: Quite interesting especially concerning the structure learned in the Z-space and how this can be used for interpolation or object removal, see the example that is shown everywhere: [](https://cloud.githubusercontent.com/assets/17261080/25330458/080b6b4e-28e0-11e7-9ab6-ce58ef5b5562.png) Nonetheless the network is still generating small images (32x32).
Your comment:
You must log in before you can post this comment!
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
