Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Xu, Kelvin and Ba, Jimmy and Kiros, Ryan and Cho, Kyunghyun and Courville, Aaron C. and Salakhutdinov, Ruslan and Zemel, Richard S. and Bengio, Yoshua
International Conference on Machine Learning - 2015 via Local Bibsonomy
Keywords: dblp
Xu, Kelvin and Ba, Jimmy and Kiros, Ryan and Cho, Kyunghyun and Courville, Aaron C. and Salakhutdinov, Ruslan and Zemel, Richard S. and Bengio, Yoshua
International Conference on Machine Learning - 2015 via Local Bibsonomy
Keywords: dblp













[link]
# Summary The authors present a way to generate captions describing the content of images using attention-based mechanisms. They present two ways of training the network, one via standard backpropagation techniques and another using stochastic processes. They also show how their model can selectively "focus" on the relevant parts of an image to generate appropriate captions, as shown in the classic example of the famous woman throwing a frisbee. Finally, they validate their model on Flicker8k, Flicker30k and MSCOCO.  # Model At a very high level, the model takes as input an image I and returns a caption generated from a pre-defined vocabulary:  A high-level overview of the model is presented in Figure 1: 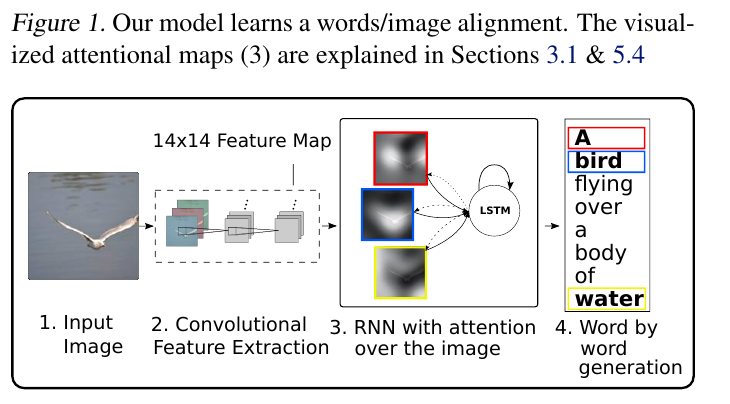 ## Visual extractor A CNN is used to extract features from the image. The authors experimented with VGG-19 pretrained on ImageNet and not finetuned. They use the features from the last convolutional layer as their representations. Starting with images of 224x224, the last CNN feature map has shape 14x14x512, which they flatten along width and height to obtain a vector representation of 196x512. These 512 vectors are used as inputs to the language model. ## Sentence generation An LSTM network is used to generate a sequence of words from a fixed vocabulary of size L. As input, a weighted sum based on attention values of the vectors of the flattened image features is used. The previous word is also fed as input to the LSTM. The hidden layer from the previous timestep as well as the layers from the CNN a_i are fed through an MLP + softmax layer and used to generate attention values for each flattened image feature vector that sum to one. 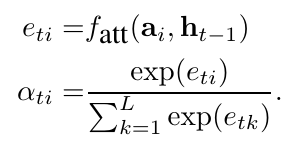  The authors propose two ways to compute phi, i.e. the attention, which they refer to as "soft attention" and "hard attention". These will be covered in a later section. The output of the LSTM, z, is then fed to a deep network to generate the next word. This is detailed in the following figure. 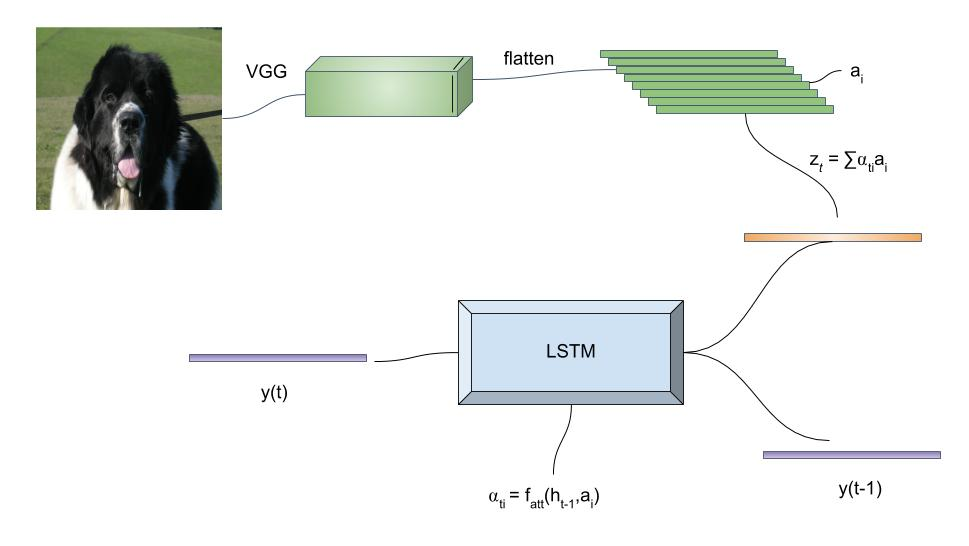 ## Attention The paper proposes two methods of attention, a "soft" attention and a "hard" attention. ### Soft attention Soft attention is the most intuitive one and is relatively straight forward. In order to compute the vector representing the image as input to the LSTM, **z**, the expectation of the context vector is computed by using a weighted average scheme: 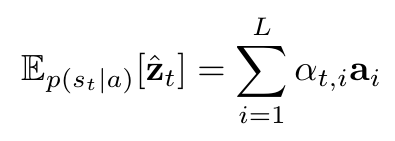 where alpha are the attention weights and a_i are the vectors of the feature representation. To ensure that all image features are used somewhat equally, a regularization term is added to the loss function: 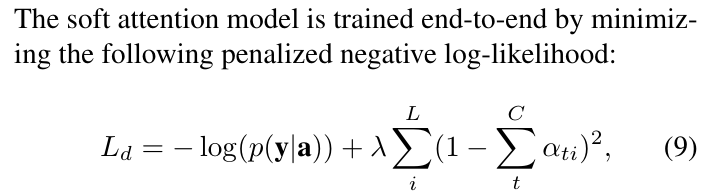 This ensures that the image feature vectors over time sum to 1 as closely as possible and that no part of the image is ignored. ### Hard attention The authors propose an alternative method to calculate attention. Each attention parameter is treated as an intermediate latent variables that can be represented in one-hot encoding, i.e. on or off. To do so, they use a multinoulli distribution parametrized by alpha, the softmax output of f_att. They show how they can approximate the gradient using monte-carlo methods: 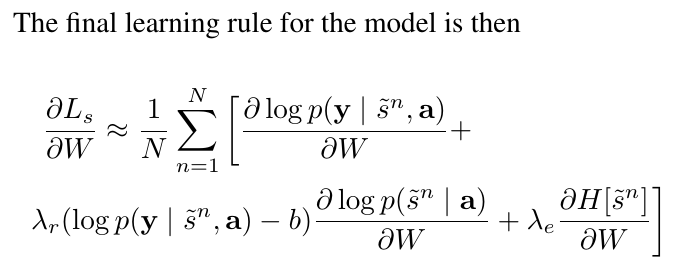 Refer to the paper for more mathemagical details. Finally, they use soft attention with probability 0.5 when using hard attention. ## Visualizing features One of the contributions of this work is showing what the network is "attending" to. To do so, the authors use the final layer of VGG-19, which consists of 14x14x512 features, upsample the resulting filters to the original image size of 224x224 and use a Gaussian blur to recreate the receptive field. ## Results The authors evaluate their methods on 3 caption datasets, i.e. Flicker8k, Flicker30k and MSCOCO. For all our experiments, they used a fixed vocabulary size of 10,000. They report both BLEU and METEOR scores on the task. As can be seen in the following figure, both the soft and hard attention mechanisms beat all state of the art methods at the time of publishing. Hard attention outperformed soft attention most of the time. 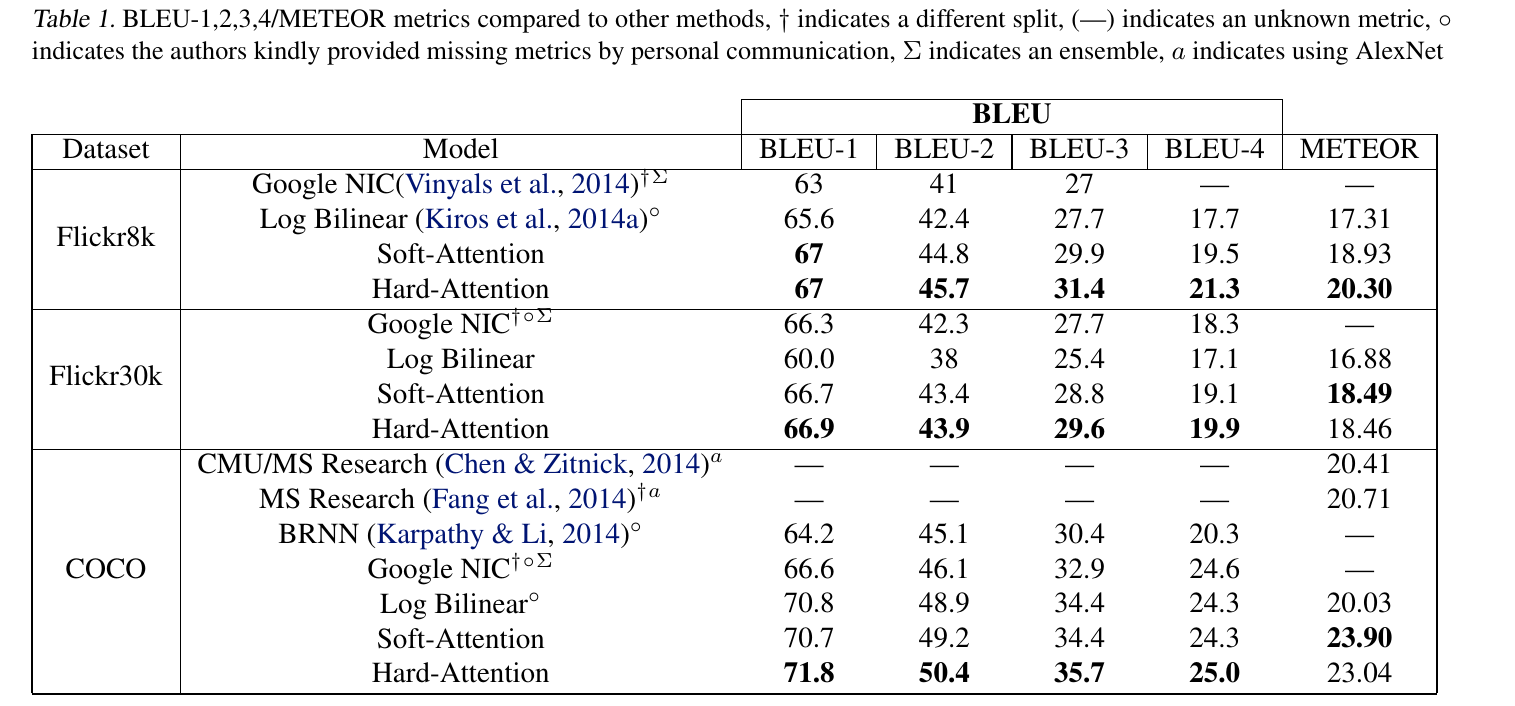 # Comments Cool paper which lead the way in terms of combining text and images and using attention mechanisms. They show an interesting way to visualize what the network is attending to, although it was not clear to me why they should expect the final layer of the CNN to be showing that in the first place since they did not finetune on the datasets they were training on. I would expect that to mean that their method would work best on datasets most "similar" to ImageNet. Their hard attention mechanism seems a lot more complicated than the soft attention mechanism and it isn't always clear that it is much better other than it offers a stronger regularization and a type of dropout. 
Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
