Conditional Image Generation with PixelCNN Decoders
Aaron van den Oord and Nal Kalchbrenner and Oriol Vinyals and Lasse Espeholt and Alex Graves and Koray Kavukcuoglu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2016/06/16 (7 years ago)
Abstract: This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.
more
less
Aaron van den Oord and Nal Kalchbrenner and Oriol Vinyals and Lasse Espeholt and Alex Graves and Koray Kavukcuoglu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2016/06/16 (7 years ago)
Abstract: This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.













[link]
* PixelRNN
* PixelRNNs generate new images pixel by pixel (and row by row) via LSTMs (or other RNNs).
* Each pixel is therefore conditioned on the previously generated pixels.
* Training of PixelRNNs is slow due to the RNN-architecture (hard to parallelize).
* Previously PixelCNNs have been suggested, which use masked convolutions during training (instead of RNNs), but their image quality was worse.
* They suggest changes to PixelCNNs that improve the quality of the generated images (while still keeping them faster than RNNs).
### How
* PixelRNNs split up the distribution `p(image)` into many conditional probabilities, one per pixel, each conditioned on all previous pixels: `p(image) = <product> p(pixel i | pixel 1, pixel 2, ..., pixel i-1)`.
* PixelCNNs implement that using convolutions, which are faster to train than RNNs.
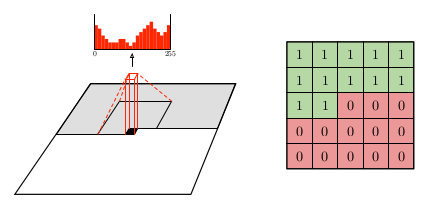
* These convolutions uses masked filters, i.e. the center weight and also all weights right and/or below the center pixel are `0` (because they are current/future values and we only want to condition on the past).
* In most generative models, several layers are stacked, ultimately ending in three float values per pixel (RGB images, one value for grayscale images). PixelRNNs (including this implementation) traditionally end in a softmax over 255 values per pixel and channel (so `3*255` per RGB pixel).
* The following image shows the application of such a convolution with the softmax output (left) and the mask for a filter (right):
* 
* Blind spot
* Using the mask on each convolutional filter effectively converts them into non-squared shapes (the green values in the image).
* Advantage: Using such non-squared convolutions prevents future values from leaking into present values.
* Disadvantage: Using such non-squared convolutions creates blind spots, i.e. for each pixel, some past values (diagonally top-right from it) cannot influence the value of that pixel.
* 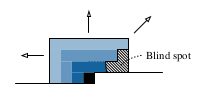
* They combine horizontal (1xN) and vertical (Nx1) convolutions to prevent that.
* Gated convolutions
* PixelRNNs via LSTMs so far created visually better images than PixelCNNs.
* They assume that one advantage of LSTMs is, that they (also) have multiplicative gates, while stacked convolutional layers only operate with summations.
* They alleviate that problem by adding gates to their convolutions:
* Equation: `output image = tanh(weights_1 * image) <element-wise product> sigmoid(weights_2 * image)`
* `*` is the convolutional operator.
* `tanh(weights_1 * image)` is a classical convolution with tanh activation function.
* `sigmoid(weights_2 * image)` are the gate values (0 = gate closed, 1 = gate open).
* `weights_1` and `weights_2` are learned.
* Conditional PixelCNNs
* When generating images, they do not only want to condition the previous values, but also on a laten vector `h` that describes the image to generate.
* The new image distribution becomes: `p(image) = <product> p(pixel i | pixel 1, pixel 2, ..., pixel i-1, h)`.
* To implement that, they simply modify the previously mentioned gated convolution, adding `h` to it:
* Equation: `output image = tanh(weights_1 * image + weights_2 . h) <element-wise product> sigmoid(weights_3 * image + weights_4 . h)`
* `.` denotes here the matrix-vector multiplication.
* PixelCNN Autoencoder
* The decoder in a standard autoencoder can be replaced by a PixelCNN, creating a PixelCNN-Autoencoder.
### Results
* They achieve similar NLL-results as PixelRNN on CIFAR-10 and ImageNet, while training about twice as fast.
* Here, "fast" means that they used 32 GPUs for 60 hours.
* Using Conditional PixelCNNs on ImageNet (i.e. adding class information to each convolution) did not improve the NLL-score, but it did improve the image quality.
* 
* They use a different neural network to create embeddings of human faces. Then they generate new faces based on these embeddings via PixelCNN.
* 
* Their PixelCNN-Autoencoder generates significantly sharper (i.e. less blurry) images than a "normal" autoencoder.

Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
