Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp













[link]
* Deep plain/ordinary networks usually perform better than shallow networks.
* However, when they get too deep their performance on the *training* set decreases. That should never happen and is a shortcoming of current optimizers.
* If the "good" insights of the early layers could be transferred through the network unaltered, while changing/improving the "bad" insights, that effect might disappear.
### What residual architectures are
* Residual architectures use identity functions to transfer results from previous layers unaltered.
* They change these previous results based on results from convolutional layers.
* So while a plain network might do something like `output = convolution(image)`, a residual network will do `output = image + convolution(image)`.
* If the convolution resorts to just doing nothing, that will make the result a lot worse in the plain network, but not alter it at all in the residual network.
* So in the residual network, the convolution can focus fully on learning what positive changes it has to perform, while in the plain network it *first* has to learn the identity function and then what positive changes it can perform.
### How it works
* Residual architectures can be implemented in most frameworks. You only need something like a split layer and an element-wise addition.
* Use one branch with an identity function and one with 2 or more convolutions (1 is also possible, but seems to perform poorly). Merge them with the element-wise addition.
* Rough example block (for a 64x32x32 input):
https://i.imgur.com/NJVb9hj.png
* An example block when you have to change the dimensionality (e.g. here from 64x32x32 to 128x32x32):
https://i.imgur.com/9NXvTjI.png
* The authors seem to prefer using either two 3x3 convolutions or the chain of 1x1 then 3x3 then 1x1. They use the latter one for their very deep networks.
* The authors also tested:
* To use 1x1 convolutions instead of identity functions everywhere. Performed a bit better than using 1x1 only for dimensionality changes. However, also computation and memory demands.
* To use zero-padding for dimensionality changes (no 1x1 convs, just fill the additional dimensions with zeros). Performed only a bit worse than 1x1 convs and a lot better than plain network architectures.
* Pooling can be used as in plain networks. No special architectures are necessary.
* Batch normalization can be used as usually (before nonlinearities).
### Results
* Residual networks seem to perform generally better than similarly sized plain networks.
* They seem to be able to achieve similar results with less computation.
* They enable well-trainable very deep architectures with up to 1000 layers and more.
* The activations of the residual layers are low compared to plain networks. That indicates that the residual networks indeed only learn to make "good" changes and default to "if in doubt, change nothing".
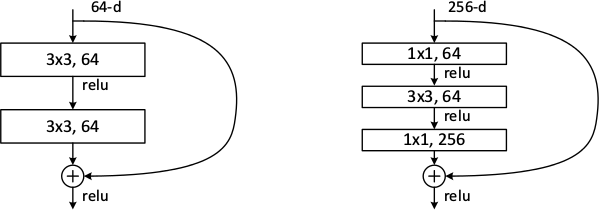
*Examples of basic building blocks (other architectures are possible). The paper doesn't discuss the placement of the ReLU (after add instead of after the layer).*
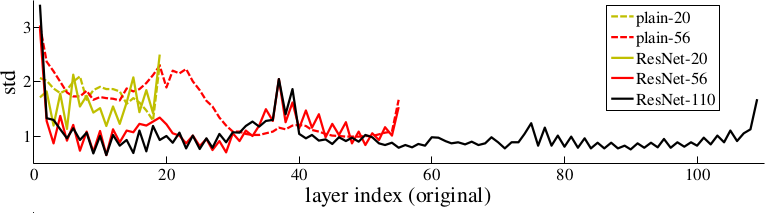
*Activations of layers (after batch normalization, before nonlinearity) throughout the network for plain and residual nets. Residual networks have on average lower activations.*
-------------------------
### Rough chapter-wise notes
* (1) Introduction
* In classical architectures, adding more layers can cause the network to perform worse on the training set.
* That shouldn't be the case. (E.g. a shallower could be trained and then get a few layers of identity functions on top of it to create a deep network.)
* To combat that problem, they stack residual layers.
* A residual layer is an identity function and can learn to add something on top of that.
* So if `x` is an input image and `f(x)` is a convolution, they do something like `x + f(x)` or even `x + f(f(x))`.
* The classical architecture would be more like `f(f(f(f(x))))`.
* Residual architectures can be easily implemented in existing frameworks using skip connections with identity functions (split + merge).
* Residual architecture outperformed other in ILSVRC 2015 and COCO 2015.
* (3) Deep Residual Learning
* If some layers have to fit a function `H(x)` then they should also be able to fit `H(x) - x` (change between `x` and `H(x)`).
* The latter case might be easier to learn than the former one.
* The basic structure of a residual block is `y = x + F(x, W)`, where `x` is the input image, `y` is the output image (`x + change`) and `F(x, W)` is the residual subnetwork that estimates a good change of `x` (W are the subnetwork's weights).
* `x` and `F(x, W)` are added using element-wise addition.
* `x` and the output of `F(x, W)` must be have equal dimensions (channels, height, width).
* If different dimensions are required (mainly change in number of channels) a linear projection `V` is applied to `x`: `y = F(x, W) + Vx`. They use a 1x1 convolution for `V` (without nonlinearity?).
* `F(x, W)` subnetworks can contain any number of layer. They suggest 2+ convolutions. Using only 1 layer seems to be useless.
* They run some tests on a network with 34 layers and compare to a 34 layer network without residual blocks and with VGG (19 layers).
* They say that their architecture requires only 18% of the FLOPs of VGG. (Though a lot of that probably comes from VGG's 2x4096 fully connected layers? They don't use any fully connected layers, only convolutions.)
* A critical part is the change in dimensionality (e.g. from 64 kernels to 128). They test (A) adding the new dimensions empty (padding), (B) using the mentioned linear projection with 1x1 convolutions and (C) using the same linear projection, but on all residual blocks (not only for dimensionality changes).
* (A) doesn't add parameters, (B) does (i.e. breaks the pattern of using identity functions).
* They use batch normalization before each nonlinearity.
* Optimizer is SGD.
* They don't use dropout.
* (4) Experiments
* When testing on ImageNet an 18 layer plain (i.e. not residual) network has lower training set error than a deep 34 layer plain network.
* They argue that this effect does probably not come from vanishing gradients, because they (a) checked the gradient norms and they looked healthy and (b) use batch normaliaztion.
* They guess that deep plain networks might have exponentially low convergence rates.
* For the residual architectures its the other way round. Stacking more layers improves the results.
* The residual networks also perform better (in error %) than plain networks with the same number of parameters and layers. (Both for training and validation set.)
* Regarding the previously mentioned handling of dimensionality changes:
* (A) Pad new dimensions: Performs worst. (Still far better than plain network though.)
* (B) Linear projections for dimensionality changes: Performs better than A.
* (C) Linear projections for all residual blocks: Performs better than B. (Authors think that's due to introducing new parameters.)
* They also test on very deep residual networks with 50 to 152 layers.
* For these deep networks their residual block has the form `1x1 conv -> 3x3 conv -> 1x1 conv` (i.e. dimensionality reduction, convolution, dimensionality increase).
* These deeper networks perform significantly better.
* In further tests on CIFAR-10 they can observe that the activations of the convolutions in residual networks are lower than in plain networks.
* So the residual networks default to doing nothing and only change (activate) when something needs to be changed.
* They test a network with 1202 layers. It is still easily optimizable, but overfits the training set.
* They also test on COCO and get significantly better results than a Faster-R-CNN+VGG implementation.

Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
