 Tiago Vinhoza
Tiago Vinhoza

sciscore: 2.5
Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp













[link]
#### Goal:
+ Reformulate neural network architecture to address the degratation problem due to the very large number of layers.
#### Motivation:
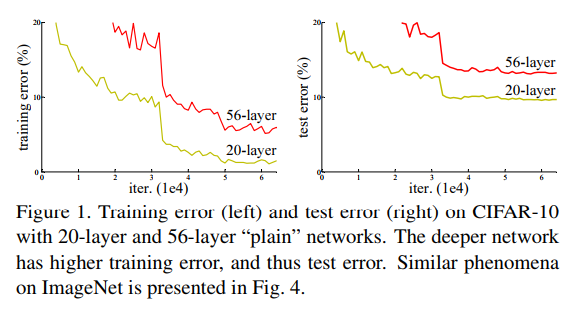
+ Degradation problem:
+ Increasing the depth of the network: accuracy gets saturated and then starts degrading.
+ As number of layers increase: higher training error.
+ In theory, such problem should not occur. Given a neural network, one can add new layers with identity mappings. In reality, optimization algorithms probably have difficulties to find (in feasible time)these solutions.
#### Residual Block:
+ Layers are reformulated as learning residual functions with reference to the layer inputs.

+ Residual Mapping.
+ Neural networks with shortcut connections to perform identity mappings.
+ Identity shortcut connections do no add extra parameters or complexity to the network.
+ The problem can be seen as follows. Given the activation of layer L of a neural net, a[L], one can write the activation at layer L+2 as follows.
a[L+2] = ReLu(W[L+2] * a[L+1] + b[L+2] + a[L])
where W[L+2] is the weight matrix and b[L+2] is the bias vector at layer L+2.
+ The problem of learning an identity mapping is easier in this case, if weight decay is applied, W[L+2] goes to zero, as well as b[L+2]. The activation function at layer a[L+2] = ReLu(a[L]) = a[L].
+ One should take take to match the dimensions. A linear projection of the previous activation function could be used before the sum.
#### Datasets:
+ For the image classification task, two datasets were used: ImageNet and CIFAR-10
|ImageNet|CIFAR-10
----|-----|-----
Training images | 1.2M | 50K
Validation images| 50K | (*)
Testing images | 100K | 10K
Number of classes | 1000 | 10
(*) in the experiments with CIFAR-10, the training images are split into 45K/5K training/validation sets.
#### Experiments and Results
**ImageNet Dataset**
+ Input images:
+ Scale jittering as in [Simonyan2015](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/Very_Deep_Convolutional_Networks_for_Large_Scale_Image_Recognition.md). Image is resized with shorter size sampled to be in between [256, 480].
+ 224x224 crop from image is used.
+ Data augmentation following [Krizhevsky2012](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/ImageNet_Classification_with_Deep_Convolutional_Neural_Networks.md) methodology: image flips, change RGB levels.
+ Training
+ Weight initialization: follows previous work by the authors.
+ Gradient descent with batch normalization, weight decay = 0.0001, momentum = 0.9
+ Mini-batch size = 256
+ Learning rate starts at 0.1 and is divided by 10 when accuracy stop increasing at the validation set.
+ Dropout is not employed
+ Testing
+ Multi-crop procedure from [Krizhevsky2012](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/ImageNet_Classification_with_Deep_Convolutional_Neural_Networks.md) is employed: 10 crops.
+ Fully connected layers are converted into convolutional layers.
+ Average of scores at multiple scales is employed. Testing scales used: {224, 256, 384, 480, 640}.
+ Configurations tested on ImageNet dataset
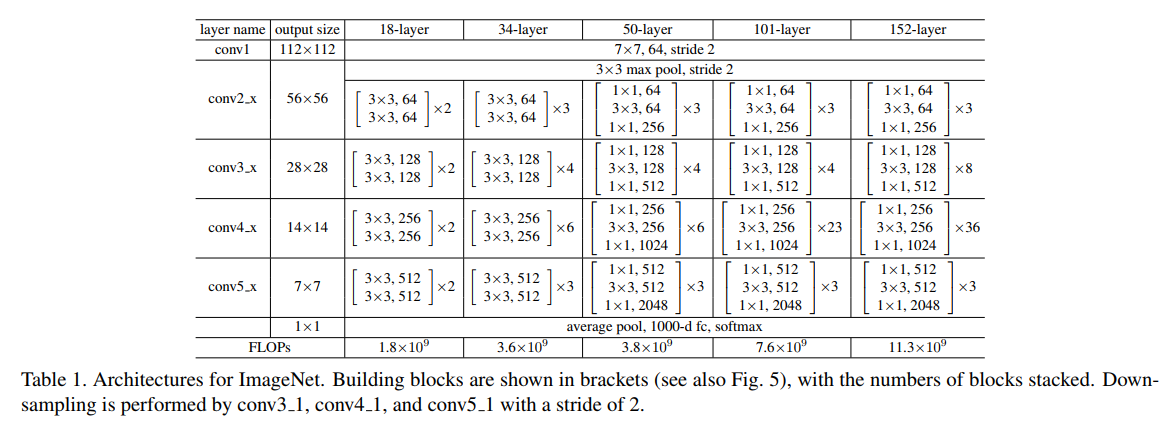
+ Single Model Results (validation set):
Architecture | top-1 error (%) | top-5 error (%)
----|:-----:|:-----:
VGG (ILSVRC'14) | - | 8.43
GoogLeNet (ILSVRC'14) |- | 7.89
VGG (v5) | 24.4 | 7.1
PReLU-net | 21.59 | 5.71
BN-inception | 21.99 | 5.81
ResNet-34 B (projections + identitites) | 21.84 | 5.71
ResNet-34 (projections) | 21.53 | 5.60
ResNet-50 | 20.74 | 5.25
ResNet-101| 19.87 | 4.60
ResNet-152 | **19.38** | **4.49**
+ Ensemble Models Results (test set):
Architecture | top-5 error (%)
----|:-----:|
VGG (ILSVRC'14) | 7.32
GoogLeNet (ILSVRC'14) | 6.66
VGG (v5) | 6.8
PReLU-net | 4.94
BN-Inception | 4.82
ResNet (ILSVRC'15) | **3.57**
**CIFAR-10 Dataset**
+ Input images:
+ Inputs: 32x32 images
+ Configurations tested on this dataset:
output map size | 32x32 | 16x16 | 8x8
----------------|-------|-------|----
num. layers | 1+2n | 2n | 2n
num. filters | 16 | 32 | 64
+ Shortcuts connected to pairs of 3x3 layers (3n shortcuts)
+ Training
+ Weight initialization: follows previous work by the authors.
+ Gradient descent with batch normalization, weight decay = 0.0001, momentum = 0.9
+ Mini-batch size = 128, 2 GPUs.
+ Learning rate starts at 0.1 and is divided by 10 at 32k and 48k iterations. Stopped at 64k iterations.
+ Dropout is not employed
+ Testing
+ Single 32x32 image
+ Results
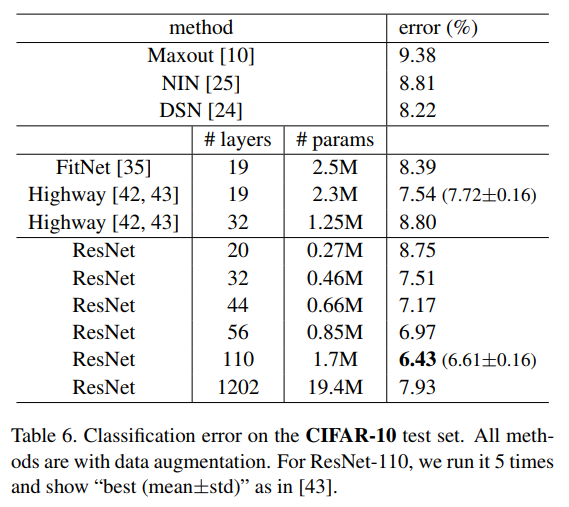
 |

Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, Karen and Zisserman, Andrew
- 2014 via Local Bibsonomy
Keywords: deep-learning, VGG
Simonyan, Karen and Zisserman, Andrew
- 2014 via Local Bibsonomy
Keywords: deep-learning, VGG
|
[link]
#### Goal:
+ Train deep convolutional neural networks with small convolutional filters to classify images into 1000 different categories.
#### Dataset
+ ImageNet Large-Scale Visual Recognition Challenge (ILSVRC): subset of ImageNet
+ 1.2 million training images, 50000 validation images, 150000 test images.
+ 1000 categories.
#### Architecture:
+ Convolutional layers followed by fully-connected layers and 1000-way softmax at the output.

+ Convolutional Layers
+ Convolutional filter: 3x3, stride = 1.
+ 'Same' convolution, padding = 1.
+ Width of convolutional layers start at 64 and increases by a factor of 2 after max-pooling until reaching 512.
+ Max Pooling: 2x2 window, stride = 2
+ Activation function: ReLU
+ Number of parameters:

#### Discussion:
+ A stack of three 3x3 convolutional layers (without max-pooling in between) is equivalent to a 7x7 convolutional layer. Why is it better?
+ Three non-linearities instead of just one.
+ Reduced number of parameters. A n x n convolutional layer with C channels has (nC)^2 parameters.
Architecture |n | C | # of parameters
------|-------|----|---
1-layer CNN | 7 | 64 | 49*4096 = 200704
3-layer CNN | 3 | 64 | 9*4096 = 36864
+ The 1x1 convolution layers from configuration C aimed to increase the non-linearity of the decision function without affecting the the receptive fields of the convolutional layers.
#### Methodology:
+ Training
+ Optimize the multinomial logistic regression cost function.
+ Gradient descent.
+ Mini batch size = 256, Momentum = 0.9, Weight decay = 0.0005
+ Initial learing rate: 0.01
+ Divided by 10 when the validation set accuracy stopped improving.
+ Decreased 3 times. Learning stopped after 370K iterations (74 epochs).
+ Weight initialization:
+ Configuration A was trained with random initialization of weights.
+ For the other configurations, the first convolutional nets and the fully connected nets were initialized using weights from configuration A. The other layers were randomly initialized.
+ Random initialization: weights are sampled from a zero-mean normal distribution with 0.01 variance. Biases are initialized wirh zero.
+ Reduce Overfitting:
+ Data Augmentation: followed [Krizhevsky2012](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/ImageNet_Classification_with_Deep_Convolutional_Neural_Networks.md) principles with random flippings and changes in RGB levels.
+ Dropout regularization for the first two fully-connected layers - p(keep) = 0.5
+ Image Resolution:
+ Models were trained at two fixed scales S=256 and S=384.
+ Multi-scale training (randomly sampling S): minimum=256, maximum=512.
+ Can be seen as training set augmentation by scale jittering.
+ At test time, test scale Q is not necessarily equal to training scale S.
#### Results
+ Implementation derived from C++ Caffe toolbox.
+ Training and evaluation on multiple GPUs (no information regarding training time).
+ Single scale evaluation:
+ Fixed training scale: Q=S.
+ Jittered training scale: Q=0.5(S_min + S_max).
+ Local Response Normalization did not improved results.
Configuration | S | Q | top-1 error (%) | top-5 error (%)
:--------------:|:---:|---|:-----------------:|:---------------:
A | 256 | 256 | 29.6 | 10.4
A-LRN | 256 | 256 | 29.7 | 10.5
B | 256 | 256 | 28.7 | 9.9
C | 256 | 256 | 28.1 | 9.4
| 384 | 384 | 28.1 | 9.3
| [256;512] | 384 | 27.3 | 8.8
D | 256 | 256 | 27.0 | 8.8
| 384 | 384 | 26.8 | 8.7
| [256;512] | 384 | 25.6 | 8.1
E | 256 | 256 | 27.3 | 9.0
| 384 | 384 | 26.9 | 8.7
| [256;512] | 384 | **25.5** | **8.0**
+ Multi-scale evaluation:
+ Fixed training scale: Q={S-32,S,S+32}.
+ Jittered training scale: Q={S_min, 0.5(S_min + S_max), S_max}.
Configuration | S | Q | top-1 error (%) | top-5 error (%)
:--------------:|:---:|---|:-----------------:|:---------------:
B | 256 | 224,256,288 | 28.2 | 9.6
C | 256 | 224,256,288 | 27.7 | 9.2
| 384 | 352,384,416 | 27.8 | 9.2
| [256;512] | 256,384,512 | 26.3 | 8.2
D | 256 | 224,256,288 | 26.6 | 8.6
| 384 | 352,384,416 | 26.5 | 8.6
| [256;512] | 256,384,512 | **24.8** | **7.5**
E | 256 | 224,256,288 | 26.9 | 8.7
| 384 | 352,384,416 | 26.7 | 8.6
| [256;512] | 256,384,512 | **24.8** | **7.5**
+ Dense versus multi-crop evaluation
+ Dense evaluation: fully connected layers are converted to convolutional layers at test time. Scores are obtained for full uncropped image and its flipped version and then averaged.
+ Multi-crop evaluation: average of scores obtained by passing multiple crops of the test image through the convolutional network.
+ Combination of multi-crop and dense has best results: probably due to different treatment of convolution boundary conditions.
Configuration | Method | top-1 error (%) | top-5 error (%)
:--------------:|:---:|:-----------------:|:---------------:
D | dense | 24.8 | 7.5
| multi-crop | 24.6 | 7.5
| multi-crop & dense | **24.4** | **7.2**
E | dense | 24.8 | 7.5
| multi-crop | 24.6 | 7.4
| multi-crop & dense | **24.4** | **7.1**
+ Comparison with State of the art solutions:
+ VGG (2 nets) = ensemble of 2 models trained using configurations D and E.
+ VGG (7 nets) = ensemble of 7 models different models trained using configurations C, D, E.

|
Imagenet classification with deep convolutional neural networks
Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E
Neural Information Processing Systems Conference - 2012 via Local Bibsonomy
Keywords: image, imagenet, thema:deepwalk, classification
Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E
Neural Information Processing Systems Conference - 2012 via Local Bibsonomy
Keywords: image, imagenet, thema:deepwalk, classification
|
[link]
#### Goal:
+ Train a deep convolutional neural network to classify 1.2 million images into 1000 different categories.
#### Convolutional Neural Networks:
+ Make strong and correct assumptions about the nature of the images (stationarity, pixel dependencies).
+ Much fewer connections and parameters: easier to train than fully connected neural networks.
#### Dataset
+ ImageNet: 15 million labeled high-resolution images from 22000 categories. Labeled manually using Amazon Mechanical Turk.
+ ImageNet Large-Scale Visual Recognition Challenge (ILSVRC): subset of ImageNet
+ 1.2 million training images, 50000 validation images, 150000 test images.
+ 1000 categories
+ Variable resolution images:
+ Images downsampled to a fixed resolution of 256 x 256.
#### Architecture:
+ 8 layers: 5 convolutional and 3 fully-connected, 1000-way softmax at the output.

**Methodology**
+ ReLU activation function: train several times faster than tanh units.
+ Faster learning had influence on the performance of large models trained on large datasets
+ Training on Multiple GPUs
+ Local Response Normalization
+ mimics a form of lateral inhibition found on real neurons.
+ applied after ReLU in the 1st and 2nd convolutional layers.
+ improves top-1 and top-5 error rates by 1.4% and 1.2%
+ Overlapping pooling
+ Neighborhood z = 3 and stride s = 2.
+ Max-pooling employed in the 1st and 2nd convolutional layers (after response normalization) and as well as after the 5th convolutinal layer.
+ Reducing Overfitting
+ Data Augmentation
+ Generate image translations and horizontal reflections.
+ Alter the intensities of RGB channels.
+ Dropout
+ Used in the first two fully-connected layers - p(keep) = 0.5
+ Learning
+ Stochastic Gradient Descent, batch size = 128, momentum = 0.9, weight decay = 0.0005
+ Weights initialized from Gaussian distribution with mean = 0 and standard deviation = 0.01
+ Bias in 2nd, 4th, and 5th convolutional layers initialized as 1. This accelerated learning as the ReLU was fed with positive inputs from the start.
+ Bias in remaining layers initialized as zeros.
+ Learning rate ($\epsilon$)
+ Equal for all layers
+ Adjusted manually (divided by 10 when validation error stopped decreasing).
+ Initialized at 0.01 and reduced 3 times during training.

+ Trained during 90 epochs (5-6 days on two NVIDIA GTX 580 3GB GPUs).
#### Results
+ Results on ILSVRC-2010 images
+ Baselines: sparse coding and Fisher vectors
Model | Top-1 | Top-5
------|-------|-------
Sparse Coding | 47.1% | 28.2%
SIFT + FVs | 45.7% | 25.7%
CNN | 37.5% | 17.0%
+ Results on ILSVRC-2012
Model | Top-1 (val) | Top-5 (val) | Top-5 (test)
------|-------|-------|-------
Sparse Coding | -- | -- | 26.2%
1 CNN | 40.7% | 18.2% | --
5 CNNs | 38.1% | 16.4% | 16.4%
1 CNN* | 39.0% | 16.6% | --
7 CNNs* | 36.7% | 15.4% | 15.3%
CNN* are convolutional neural networks pretrained on ImageNet 2011 Fall release and fine-tuned on ILSVRC-2012 training data.
+ Qualitative assessment
+ Convolutional kernels showed *specialization*

+ Most of top-5 labels were reasonable
+ Image similarity based on the feature activations induced at the last fully connected layer:

#### Caveat:
+ Most of the choices made in the paper were based on experimental results. There is not too much theory behind.
|
Learning to Diagnose with LSTM Recurrent Neural Networks
Lipton, Zachary Chase and Kale, David C. and Elkan, Charles and Wetzel, Randall C.
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
Lipton, Zachary Chase and Kale, David C. and Elkan, Charles and Wetzel, Randall C.
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Goal
+ Predict 128 diagnoses for intensive pediatric care patients.
#### Dataset:
+ Children's Hospital LA.
+ Episode is a multivariate time series that describes the stay of one patient in the intensive care unit.
Dataset properties | Value
---------|----------
Number of episodes | 10,401
Duration of episodes | From 12h to several months
Time series variables | Systolic blood pressure, Diastolic blood pressure, Peripheral capillary refill rate, End tidal CO2, Fraction of inspired O2, Glasgow coma scale, Blood glucose, Heart rate, pH, Respiratory rate, Blood O2 Saturation, Body temperature, Urine output.
+ Resampling and missing values:
+ Irregularly sampled time-series that is resampled to an hourly rate.
+ Mean measurement within each hour window is taken.
+ Forward- and back-filling are used to fill gaps created by the resampling.
+ When variable time series is missing entirely: imputation with a clinically *normal* value defined by domain experts.
+ This paper is followed by [Modeling Missing Data in Clinical Time Series with RNNs](http://www.shortscience.org/paper?bibtexKey=journals/corr/LiptonKW16) from the same research group.
+ Labels:
+ Each episode is associated with 0 or more diagnoses. (in-house taxonomy, ICD-9 based).
+ Dataset contains 429 diagnoses. The paper focuses on the 128 most frequent diagnoses that appear 50 or more times in the dataset.
#### Architecture:
+ LSTM with Target Replication:
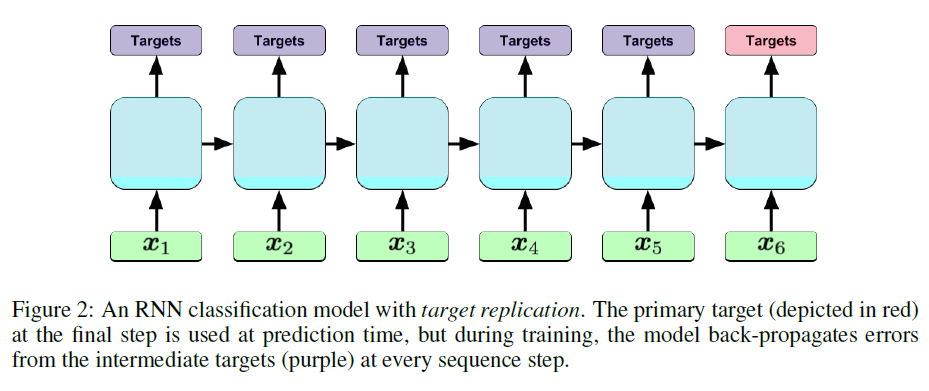
+ Loss function:
+ For the model with target replication, output y is generated at every sequence step. The loss function is then a convex combination of the final loss (log-loss in the case of this paper) and the average of the losses over all steps where T is the number of sequence steps and alpha is a hyperparameter.
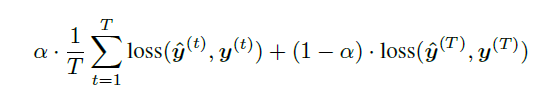
#### Experiments and Results:
**Methodology**:
+ Split dataset: 80% training, 10% validation, 10% test
+ LTSM trained for 100 epochs via gradient stochastic gradient (with momentum).
+ Regularization L2: 1e-6, obtained via validation dataset.
+ LSTM: 2 hidden layers with 64 cells or 128 cells (and 50% dropout)
+ Multiple combinations: target replication / auxiliary target variables (trained using the other 301 diagnoses and other clinical information as a target. Inferences are made only for the 128 major diagnoses.
+ Baselines for comparison:
+ Logistic Regression - L2 regularized
+ MLP with 3 hidden layers - ReLU - dropout 50%.
+ Baselines tested in the raw time-series and in a feature engineering version made by domain experts.
*Metrics*:
+ Micro AUC, Micro F1: calculated by adding the TPs, FPs, TNs and FNs for the entire dataset and for all classes.
+ Macro AUC, Macro F1: Arithmetic mean of AUCs and F1 scores for each of the classes.
+ Precision at 10: Fraction of correct diagnoses among the top 10 predictions of the model.
+ The upper bound for precision at 10 is 0.2281 since in the test set there are on average 2.281 diagnoses per patient.
*Results*:
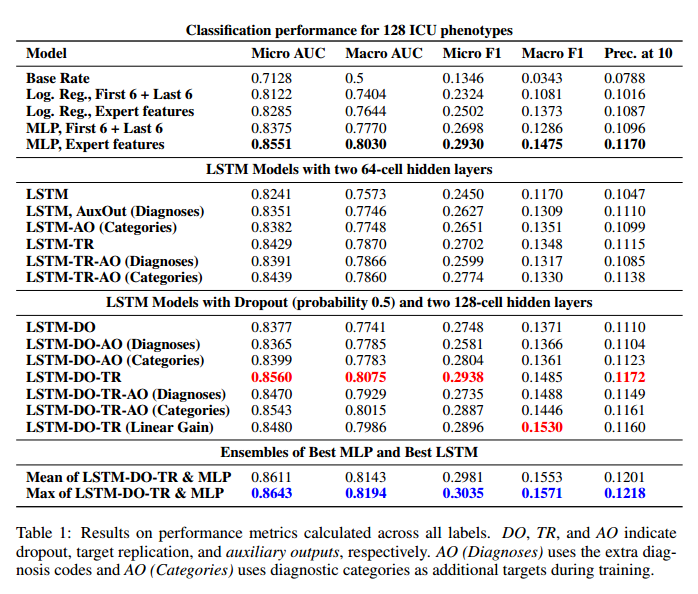
*Results for selected diagnoses*:
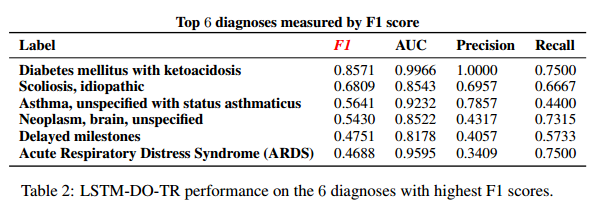
#### Discussion:
+ Auxiliary outputs improve performance at the expense of increased training time. Very unbalanced dataset for some of the remaining 301 labels makes it spend an entire epoch only to learn that one of the target variables can take values other than 0.
+ Real-Time Predictions: In the future, the authors expect that the proposed solution could be used to make continuously updated real-time alerts and diagnoses.
|
Development and validation of a continuous measure of patient condition using the Electronic Medical Record
Rothman, Michael J. and Rothman, Steven I. and IV, Joseph Beals
Journal of Biomedical Informatics - 2013 via Local Bibsonomy
Keywords: dblp
Rothman, Michael J. and Rothman, Steven I. and IV, Joseph Beals
Journal of Biomedical Informatics - 2013 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Goal: + Development and validation of a continuous score for patient assessment (to be used both outside and inside intensive care). + Prior work: Modified Early Warning Score (MEWS) identifies 44% of intensive care transfers occurring within the next 12 hours. Generates 69 false positives for each correctly identified event. #### Dataset: Model Creation | Model Validation ---------------|------------------ 22,265 patients admitted to the *Sarasota Memorial Hospital* (SMH) between Jan/2004 and Dec/2004 | 32341 patients admitted to the SMH between Sep/2007 and Jun/2009 | 45,771 patients admitted to the SMH between Jan/2008 and May/2010 | 32,416 patients admitted to *Abigton Memorial Hospital* (AMH) between Jul/2009 and Jun/2010 | 19,402 patients admitted between Jul/2008 and Nov/2008 in *Hospital C*. + ~ 7000 variables, 500 laboratory tests. + Constraints: + Variables should be related to the patient's condition + Collected with some frequency + Susceptible to variation during patient stay in the hospital + Focus: "How the patient is" not "Who the patient is" + The constraints reduce the number of candidate variables to 43 (13 nurse assessments, 6 vital signs and 23 laboratory tests) #### Rothman Index: + The Rothman Index is based on the "Excess Risk" associated with each of the variables: + The excess risk is determined by the increase (in percentage points) of the mortality at 1 year identified for that variable. In the best case, the "excess" risk is zero and the Rothman Index equals 100. 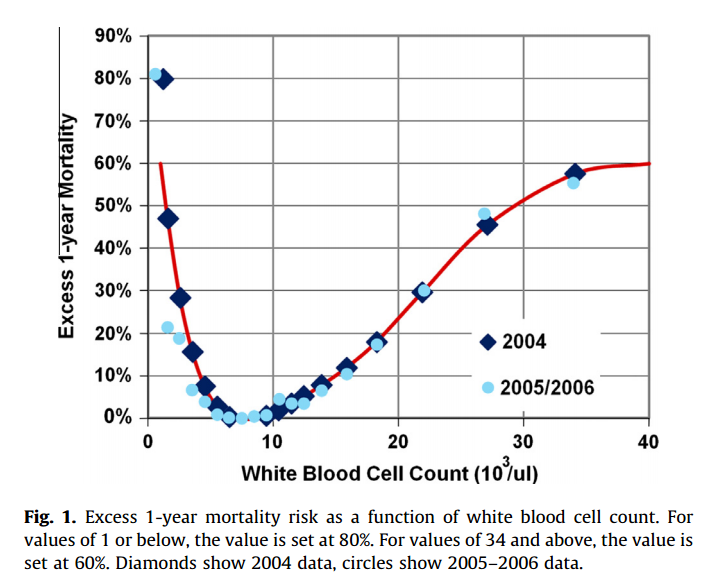 + The excess risk somewhat resembles the *impact coding* for categorical variables. One must always be careful that there is no data snooping. + The index consists of the 26 variables below. They were chosen from the 43 candidates using a *forward stepwise logistic regression* with the patients of the model creation dataset (criterion p-value <0.05). Note that the logistic regression is used only to choose the variables. The Rothman Index is not a regression model itself. 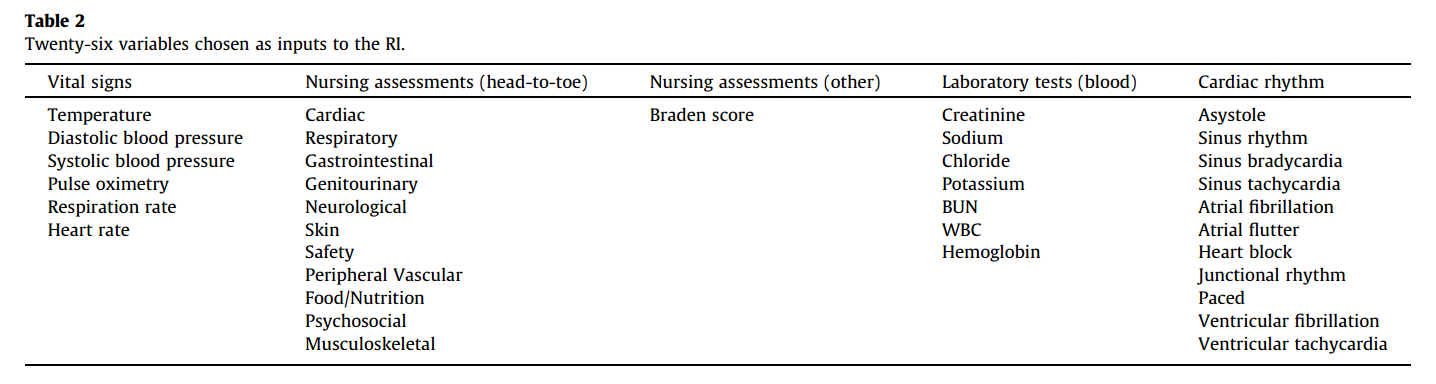 + The lab tests are collected less frequently. The score is divided into two parts (one that takes into account the laboratory variables and another that does not take into account). 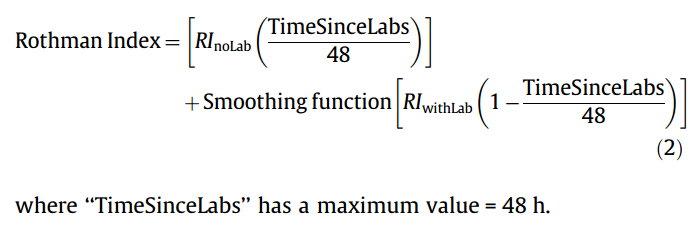 + *TimeSinceLabs* has a maximum value of 48 hours. #### Results: + Outcomes: + Mortality in 24h + Unplanned readmission in 30 days + Discharge + Rothman Index is correlated with discharge category (Home, Home healthcare, Rehab, Skilled Nursing Facility, Hospice, Death) |Mortality in 24h || Readmission in 30 days || Discriminates type of discharge| | |-------------|-|-----------------------|-|------------------------|-------------------------------| | Hospital| AUC | Hospital | AUC | Hospital | AUC| |SMH | 0.933 (0.915-0.930) | SMH | 0.62 (0.61-0.63) | SMH | 0.923 (0.915-0.930)| |AMH | 0.948 (0.960-0.970) | AMH | *| AMH | 0.965 (0.960-0.970)| |C | 0.929 (0.919-0.940) | C | *| C| 0.915 (0.900-0.931) | (*) in the case of readmission in 30 days it was possible to only identify the patients of the SMH hospital. + Tracking the Rothman Index and correlating it with events during hospital stay: 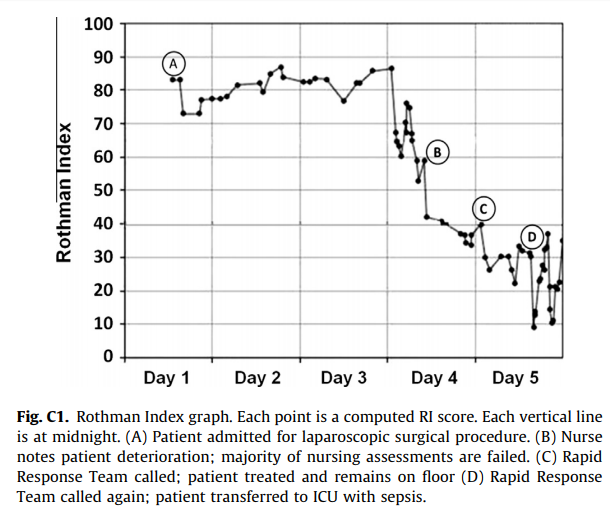 #### Discussion: + Choice of 1-year mortality to calculate excess risk: + Instead of in-hospital death, which is relatively rare (approximately 1—2% of patients), the model is based on 1-year post discharge mortality, where death is far more common (approximately 10% of patients). + Improve the *signal strength* to determine the relationships between clinical measures and risk. + Outcome should be sufficiently frequent and a plausible surrogate for the patient condition. In this case, the risk tries to quantify *distance from death*. + The Rothman index is not designed to predict any specific outcome. + Caveat: Results should have included precision/recall analysis. For risk assessment it is important to evaluate the rate of false alarms per one true positive. |
Doctor AI: Predicting Clinical Events via Recurrent Neural Networks
Choi, Edward and Bahadori, Mohammad Taha and Sun, Jimeng
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
Choi, Edward and Bahadori, Mohammad Taha and Sun, Jimeng
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Goal:
+ Diagnostic and drug code prediction on a subsequent visit using diagnostic codes, medications, procedures and date of previous visits.
+ Predict when the next visit to the doctor will happen.
#### Dataset:
+ Sutter Health Palo Alto Medical Foundation - primary care - case-control study for heart failure.
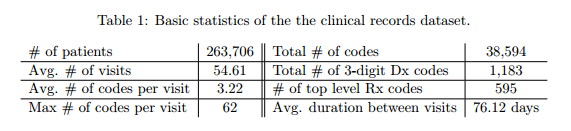
+ Patients with fewer than two visits were excluded.
+ Inputs:
+ ICD-9 codes,
+ GPI drug codes
+ codes for CPT procedures
+ Records are time-stamped with the patient's visiting time.
+ If a patient receives multiple codes on the same visit, they all receive the same timestamp.
+ Granularity of codes - group subcategories:
+ ICD-9 3 digits: 1183 unique codes
+ GPI Drug class: 595 single groups
+ Target: y = [diagnosis, drug] - vector of 1183 + 595 = 1778 dimensions.
#### Architecture:
+ Gated Recurrent Units (GRU)
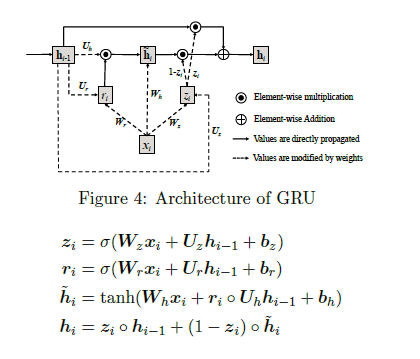")
+ The input vector x is one-hot encoded and has a dimension of 40000. The first layer tries to reduce dimensionality.
+ Two approaches to dimensionality reduction (embedding matrix W_emb)
+ W_emb is learned together with the model.
+ W_emb is pre-trained using techniques such as word2vec.
+ Loss function: cross entropy for codes + quadratic error for forecasting visits.
+ Prediction layer codes: Softmax / Prediction layer of the next time visit: ReLu.
#### Experiments and Results:
+ Code available on GitHub: https://github.com/mp2893/doctorai
+ Implementation in Theano - Training with 2 Nvidia Tesla K80 GPUs
*Methodology*:
+ Dataset split: 85% training, 15% test.
+ RNN trained for 20 epochs.
+ L2 regularization for both the vector of coefficients of the codes and for the vector of coefficients of the next visit (lambda = 0.001) - Dropout between GRU and prediction layer (and between GRU layers if there are more than 1).
+ 2000 neurons in the hidden layer
*Baselines*:
+ Frequency: The codes from the previous visit are repeated on the new visit. Good baseline for the case of patients whose condition tends to stabilize over time.
+ Top k most frequent codes from the previous visit.
+ Logistic Regression and Multilayer Perceptron. Uses the last 5 visits to predict the next.
*Metrics*:
+ top-k recall emulates the behavior of physicians when making a differential diagnosis
top-k recall = # of true positives in the top k predictions / number of true positives
+ R^2 used to evaluate the performance of the next visit prediction.
+ Predict logarithm of time duration between visits to reduce the impact of very long intervals.
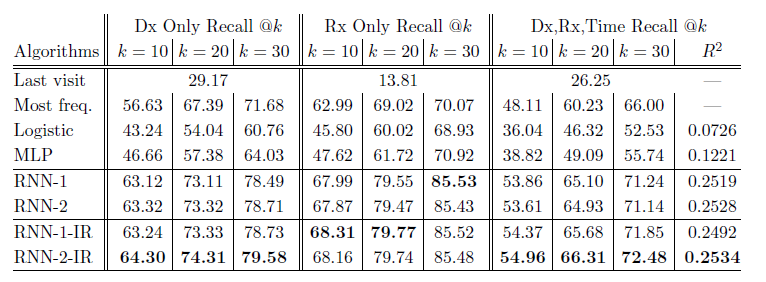
*Results Table*:
+ RNN-1: RNN with a single hidden layer initialized with a random orthogonal matrix for W_emb.
+ RNN-2: RNN with two hidden layers initialized with a random orthogonal matrix for W_emb.
+ RNN-1-IR: RNN using a single hidden layer initialized embedding matrix w emb with the Skip-gram vectors trained on the entire dataset.
+ RNN-2-IR: RNN with two hidden layers initialized embedding matrix W_emb with the Skip-gram vectors trained on the entire dataset.
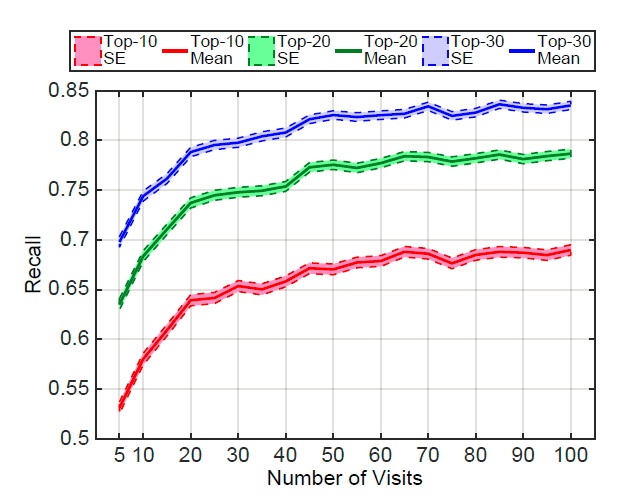
+ Performance varies according to the number of patient visits:
+ Networks learn best when they observe more records.
+ Patients with frequent visits are sicker patients. In a way, it is easier to predict the future in these cases.
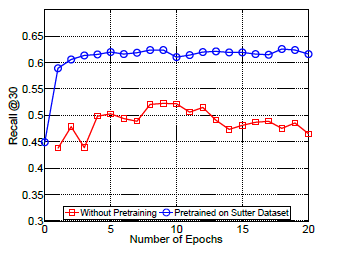
+ Performance of Doctor AI in other datasets:
+ Potential to transfer knowledge accross hospitals. Pre-train Doctor AI on Sutter Health dataset and fine-tuned in MIMIC II dataset.
#### Extras
+ There is an interview about the paper at the [Data Skeptic](https://dataskeptic.com/blog/episodes/2017/doctor-ai) podcast.
|
Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records
Riccardo Miotto and Li Li and Brian A. Kidd and Joel T. Dudley
Scientific Reports - 2016 via Local CrossRef
Keywords:
Riccardo Miotto and Li Li and Brian A. Kidd and Joel T. Dudley
Scientific Reports - 2016 via Local CrossRef
Keywords:
|
[link]
#### Goal
+ Use unsupervised deep learning to obtain a low-dimensional representation of a patient from EHR data.
+ A better representation will facilitate clinical prediction tasks.
#### Architecture:
+ Patient EHR is obtained from the Hospital Data Warehouse:
+ demographic info
+ ICD-9 codes
+ medication, labs
+ clinical notes: free text
+ Use stacked denoising autoencoders (SDA) to obtain an abstract representation of the patient with lower dimensionality.
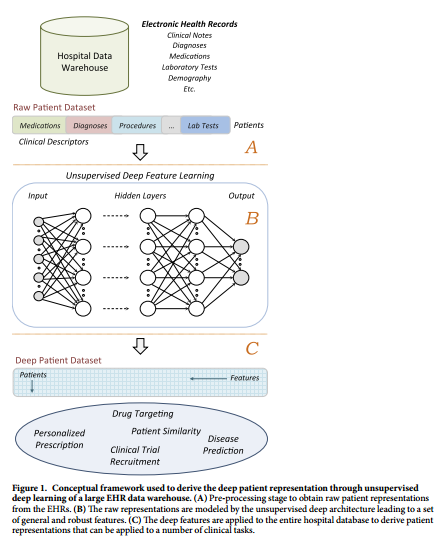
#### Dataset:
+ Data Warehouse from Mount Sinai Hospital in NY.
+ All patient records that had a diagnosed disease (ICD-9 code) between 1980 and 2014 - approximately 1.2 million patients with 88.9 records/patient - were initially selected.
+ 1980-2013: training, 2014: test.
*Data Cleaning*:
+ Diseases diagnosed in fewer than 10 patients in the training dataset were eliminated.
+ Diseases that could not be diagnosed through EHR labels were eliminated. Related to social behavior (HIV), fortuitous events (injuries, poisoning) or unspecific ('other cancers'). The final list contains 78 diseases.
*Final version of the dataset (raw patient representation)*:
+ Training: 704,587 patients (to obtain deep features post SDA).
+ Validation: 5,000 patients (for the evaluation of the predictive model for diseases).
+ Test: 76,214 patients (for the evaluation of the predictive model for diseases).
+ 41072 columns - demographic info, ICD-9, medication, lab test, free text (LDA topic modeling dimension 300)
+ Very high dimensional but very sparse representation
#### Results:
*Stacked Denoisinig Autoencoders for low-dimensional patient representation*:
+ 3 layers of denoising autoencoders.
+ Each layer has 500 neurons. Patient is now represented by a dense vector of 500 features.
+ Inputs are normalized to lie in the [0, 1] interval.
+ Inputs in each of the layers have added noise at a ratio of 5% noise (masking noise corruption - value of these features is set to '0').
+ Sigmoid activation function.
*Classifiers for disease prediction*:
+ Random forest classifiers with 100 trees trained for each of the 78 diseases.
*Baseline for comparison*:
+ PCA with 100 components, k-means with 500 clusters, GMM with 200 mixes and ICA with 100 components. (see Discussion)
+ RawFeat: original patient EHR features: sparse vector with 41072 features (~ 1% of non-zero entries).
+ Threshold to rank as "positive": 0.6
*Aggregate performance in predicting diseases*:
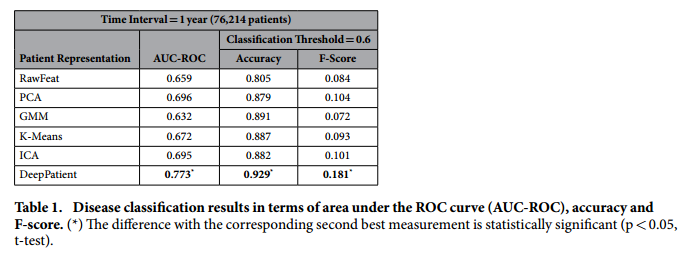
+ Comment: This result of F-Score = 0.181 implies a precision of 0.102 (let us assume a recall in the order of 80%), which means that with each correct diagnosis, the Deep Patient generates approximately 9 false alarms.
*Performance for some particular diseases*:
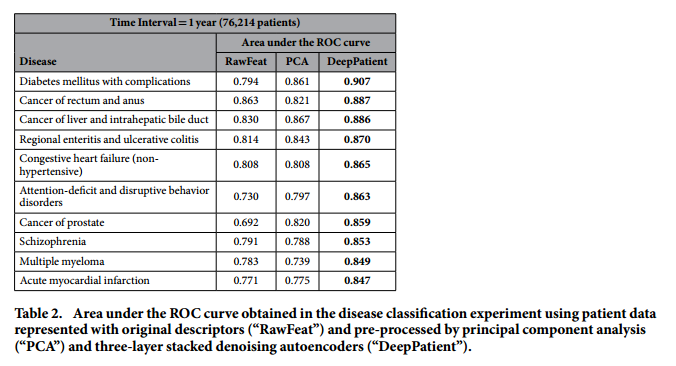
#### Discussion:
+ DeepPatient *does not* use lab results in model building. Only the *frequency* at which the analysis is performed is taken into account.
+ Future enhancements:
+ Describe a patient with a temporal sequence of vectors s instead of summarizing all data in one vector.
+ Add other categories of EHR data, such as insurance details, family history and social behaviors.
+ Use PCA as a pre-processing step before SDA?
+ Caveat: the comparisons does not seem to be fair. If the autoencoder has dimension 500, the other baselines should also have dimension 500.
|
Directly Modeling Missing Data in Sequences with RNNs: Improved Classification of Clinical Time Series
Lipton, Zachary Chase and Kale, David C. and Wetzel, Randall C.
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
Lipton, Zachary Chase and Kale, David C. and Wetzel, Randall C.
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Motivation:
+ Take advantage of the fact that missing values can be very informative about the label.
+ Sampling a time series generates many missing values.

#### Model (indicator flag):
+ Indicator of occurrence of missing value.
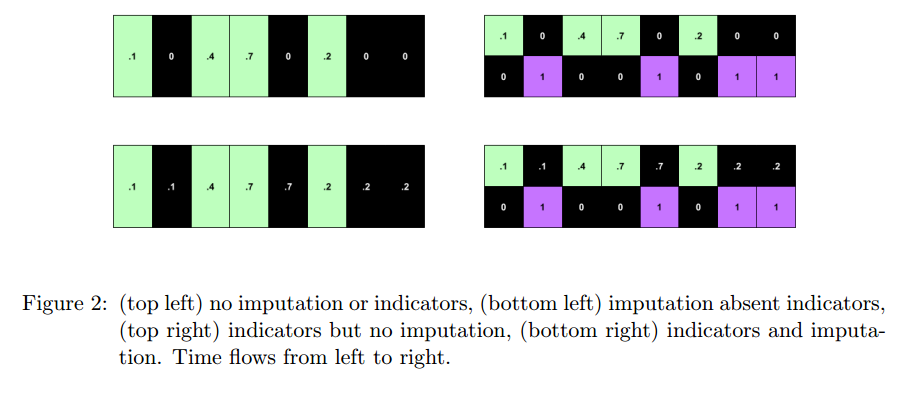
+ An RNN can learn about missing values and their importance only by using the indicator function. The nonlinearity from this type of model helps capturing these dependencies.
+ If one wants to use a linear model, feature engineering is needed to overcome its limitations.
+ indicator for whether a variable was measured at all
+ mean and standard deviation of the indicator
+ frequency with which a variable switches from measured to missing and vice-versa.
#### Architecture:
+ RNN with target replication following the work "Learning to Diagnose with LSTM Recurrent Neural Networks" by the same authors.
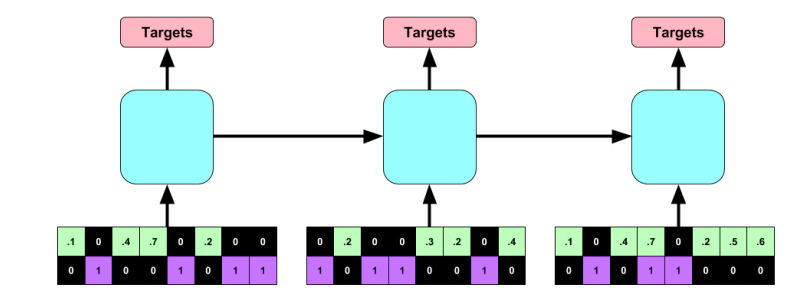
#### Dataset:
+ Children's Hospital LA
+ Episode is a multivariate time series that describes the stay of one patient in the intensive care unit
Dataset properties | Value
---------|----------
Number of episodes | 10,401
Duration of episodes | From 12h to several months
Time series variables | Systolic blood pressure, Diastolic blood pressure, Peripheral capillary refill rate, End tidal CO2, Fraction of inspired O2, Glasgow coma scale, Blood glucose, Heart rate, pH, Respiratory rate, Blood O2 Saturation, Body temperature, Urine output.
#### Experiments and Results:
**Goal**
+ Predict 128 diagnoses.
+ Multilabel: patients can have more than one diagnose.
**Methodology**
+ Split: 80% training, 10% validation, 10% test.
+ Normalized data to be in the range [0,1].
+ LSTM RNN:
+ 2 hidden layers with 128 cells. Dropout = 0.5, L2-regularization: 1e-6
+ Training for 100 epochs. Parameters chosen correspond to the time that generated the smallest error in the validation dataset.
+ Baselines:
+ Logistic Regression (L2 regularization)
+ MLP with 3 hidden layers and 500 hidden neurons / layer (parameters chosen via validation set)
+ Tested with raw-features and hand-engineered features.
+ Strategies for missing values:
+ Zeroing
+ Impute via forward / backfilling
+ Impute with zeros and use indicator function
+ Impute via forward / backfilling and use indicator function
+ Use indicator function only
#### Results
+ Metrics:
+ Micro AUC, Micro F1: calculated by adding the TPs, FPs, TNs and FNs for the entire dataset and for all classes.
+ Macro AUC, Macro F1: Arithmetic mean of AUCs and F1 scores for each of the classes.
+ Precision at 10: Fraction of correct diagnostics among the top 10 predictions of the model.
+ The upper bound for precision at 10 is 0.2281 since in the test set there are on average 2.281 diagnoses per patient.
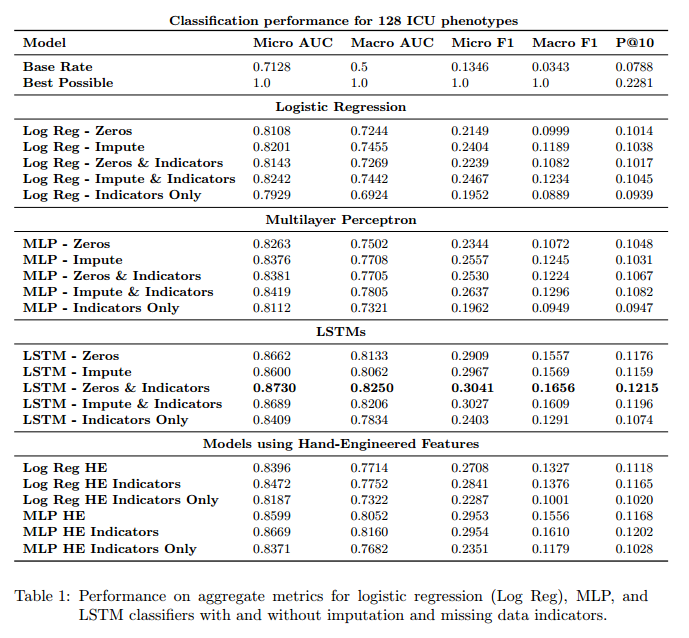
#### Discussion:
+ Predictive model based on data collected following a given routine. This routine can change if the model is put into practice. Will the model predictions in this new routine remain valid?
+ Missing values in a way give an indication of the type of treatment being followed.
+ Trade-off between complex models operating on raw features and very complex features operating on more interpretable models.
|
Recurrent Neural Networks for Multivariate Time Series with Missing Values
Zhengping Che and Sanjay Purushotham and Kyunghyun Cho and David Sontag and Yan Liu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.NE, stat.ML
First published: 2016/06/06 (7 years ago)
Abstract: Many multivariate time series data in practical applications, such as health care, geoscience, and biology, are characterized by a variety of missing values. It has been noted that the missing patterns and values are often correlated with the target labels, a.k.a., missingness is informative, and there is significant interest to explore methods which model them for time series prediction and other related tasks. In this paper, we develop novel deep learning models based on Gated Recurrent Units (GRU), a state-of-the-art recurrent neural network, to handle missing observations. Our model takes two representations of missing patterns, i.e., masking and time duration, and effectively incorporates them into a deep model architecture so that it not only captures the long-term temporal dependencies in time series, but also utilizes the missing patterns to improve the prediction results. Experiments of time series classification tasks on real-world clinical datasets (MIMIC-III, PhysioNet) and synthetic datasets demonstrate that our models achieve state-of-art performance on these tasks and provide useful insights for time series with missing values.
more
less
Zhengping Che and Sanjay Purushotham and Kyunghyun Cho and David Sontag and Yan Liu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.NE, stat.ML
First published: 2016/06/06 (7 years ago)
Abstract: Many multivariate time series data in practical applications, such as health care, geoscience, and biology, are characterized by a variety of missing values. It has been noted that the missing patterns and values are often correlated with the target labels, a.k.a., missingness is informative, and there is significant interest to explore methods which model them for time series prediction and other related tasks. In this paper, we develop novel deep learning models based on Gated Recurrent Units (GRU), a state-of-the-art recurrent neural network, to handle missing observations. Our model takes two representations of missing patterns, i.e., masking and time duration, and effectively incorporates them into a deep model architecture so that it not only captures the long-term temporal dependencies in time series, but also utilizes the missing patterns to improve the prediction results. Experiments of time series classification tasks on real-world clinical datasets (MIMIC-III, PhysioNet) and synthetic datasets demonstrate that our models achieve state-of-art performance on these tasks and provide useful insights for time series with missing values.
|
[link]
#### Motivation:
+ When sampling a clinical time series, missing values become ubiquitous due to a variety of factors such as frequency of medical events (when a blood test is performed, for example).
+ Missing values can be very informative about the label - *informative missingness*.
+ The goal of the paper is to propose a deep learning model that **exploits the missingness patterns** to enhance its performance.
#### Time series notation:
Multivariate time series with $D$ variables of length $T$:
+ ${\bf X} = ({\bf x}_1, {\bf x}_2, \ldots, {\bf x}_T)^T \in \mathbb{R}^{T \times D}$.
+ ${\bf x}_t \in \mathbb{R}^{D}$ is the $t$-th measurement of all variables.
+ $x_t^d$ is the $d$-th component of ${\bf x}_t$.
Missing value information is incorporated using *masking* and *time-interval* concepts.
+ Masking: says which of the entries are missing values.
+ Masking vector ${\bf m}_t \in \{0, 1\}^D$, $m_t^d = 1$ if $x_t^d$ exists and $m_t^d = 0$ if $x_t^d$ is missing.
+ Time-interval: temporal pattern of 'no-missing' observations. Represented by time-stamps $s_t$ and time intervals $\delta_t$ (since its last observation).
Example:
${\bf X}$: input time series with 2 variables,
$$ {\bf X} = \begin{pmatrix}
47 & 49 & NA & 40 & NA & 43 & 55 \\ NA & 15 & 14 & NA & NA & NA & 15
\end{pmatrix}
$$
with time-stamps
$${\bf s} = \begin{pmatrix}
0 & 0.1 & 0.6 & 1.6 & 2.2 & 2.5 & 3.1
\end{pmatrix}
$$
The masking vectors ${\bf m}_t$ and time intervals ${\delta}_t$ for each variable are computed and stacked forming the masking matrix ${\bf M}$ and time interval matrix ${\bf \Delta}$ :
$$ {\bf M} = \begin{pmatrix}
1 & 1 & 0 & 1 & 0 & 1 & 1 \\ 0 & 1 & 1 & 0 & 0 & 0 & 1
\end{pmatrix}
$$
$$ {\bf \Delta} = \begin{pmatrix}
0 & 0.1 & 0.5 & 1.5 & 0.6 & 0.9 & 0.6 \\ 0 & 0.1 & 0.5 & 1.0 & 1.6 & 1.9 & 2.5
\end{pmatrix}
$$
#### Proposed Architecture:
+ GRU (Gated Recurrent Units) with "trainable" decays:
+ Input decay: which causes the variable to converge to its empirical mean instead of simply filling with the last value of the variable. The decay of each input is treated independently
+ Hidden state decay: Attempts to capture richer information from missing patterns. In this case the hidden state of the network at the previous time step is decayed.
#### Dataset:
+ MIMIC III v1.4: https://mimic.physionet.org/
+ Input events, Output events, Lab events, Prescription events
+ PhysioNet Challenge 2012: https://physionet.org/challenge/2012/
| MIMIC III | PhysioNet 2012 |
-----------------------------------|--------------|---------------------
Number of samples ($N$) | 19714 | 4000
Number of variables ($D$) |99 | 33
Mean number of time steps |35.89 | 68.91
Maximum number of time steps|150 | 155
Mean of variable missing rate |0.9621| 0.8225
#### Experiments and Results:
**Methodology**
+ Baselines:
+ Logistic Regression, SVM, Random Forest (PhysioNet sampled every 1h. MIMIC sampled every 2h). Forward / backfilling imputation. Masking vector is concatenated input to inform the models what inputs are imputed.
+ LSTM with mean imputation.
+ Variations of the proposed GRU model:
+ GRU-mean: impute average of the training set.
+ GRU-forward: impute last value.
+ GRU-simple: masking vectors and time interval are inputs. There is no imputation.
+ GRU-D: proposed model.
+ Batch normalization and dropout (p = 0.5) applied to the regression layer.
+ Normalized inputs to have a mean of 0 and standard deviation 1.
+ Parameter optimization: early stopping on validation set.
**Results**
Mortality Prediction (results in terms of AUC):
+ Proposed GRU-D outperforms other models on both datasets:
+ AUC = 0.8527 $\pm$ 0.003 for MIMIC-III and 0.8424 $\pm$ 0.012 for PhysioNet
+ Random Forest and SVM are the best non-RNN baselines.
+ GRU-simple was the best RNN variant.
Multitask Prediction (results in terms of AUC):
+ PhysioNet: mortality, <3 days, surgery, cardiac condition.
+ MIMIC III: 20 diagnostic categories.
+ The proposed GRU-D outperforms other baseline models.
#### Positive Aspects:
+ Instead of performing simple mean imputation or using indicator functions, the paper exploits missing values and missing patterns in a novel way.
+ The paper performs lengthy comparisons against baselines.
#### Caveats:
+ Clinical mortality datasets usually have very high imbalance between classes. In such cases, AUC alone is not the best metric to evaluate. It would have been interesting to see the results in terms of precision/recall.
|
Clinical Intervention Prediction and Understanding using Deep Networks
Harini Suresh and Nathan Hunt and Alistair Johnson and Leo Anthony Celi and Peter Szolovits and Marzyeh Ghassemi
arXiv e-Print archive - 2017 via Local arXiv
Keywords: cs.LG
First published: 2017/05/23 (6 years ago)
Abstract: Real-time prediction of clinical interventions remains a challenge within intensive care units (ICUs). This task is complicated by data sources that are noisy, sparse, heterogeneous and outcomes that are imbalanced. In this paper, we integrate data from all available ICU sources (vitals, labs, notes, demographics) and focus on learning rich representations of this data to predict onset and weaning of multiple invasive interventions. In particular, we compare both long short-term memory networks (LSTM) and convolutional neural networks (CNN) for prediction of five intervention tasks: invasive ventilation, non-invasive ventilation, vasopressors, colloid boluses, and crystalloid boluses. Our predictions are done in a forward-facing manner to enable "real-time" performance, and predictions are made with a six hour gap time to support clinically actionable planning. We achieve state-of-the-art results on our predictive tasks using deep architectures. We explore the use of feature occlusion to interpret LSTM models, and compare this to the interpretability gained from examining inputs that maximally activate CNN outputs. We show that our models are able to significantly outperform baselines in intervention prediction, and provide insight into model learning, which is crucial for the adoption of such models in practice.
more
less
Harini Suresh and Nathan Hunt and Alistair Johnson and Leo Anthony Celi and Peter Szolovits and Marzyeh Ghassemi
arXiv e-Print archive - 2017 via Local arXiv
Keywords: cs.LG
First published: 2017/05/23 (6 years ago)
Abstract: Real-time prediction of clinical interventions remains a challenge within intensive care units (ICUs). This task is complicated by data sources that are noisy, sparse, heterogeneous and outcomes that are imbalanced. In this paper, we integrate data from all available ICU sources (vitals, labs, notes, demographics) and focus on learning rich representations of this data to predict onset and weaning of multiple invasive interventions. In particular, we compare both long short-term memory networks (LSTM) and convolutional neural networks (CNN) for prediction of five intervention tasks: invasive ventilation, non-invasive ventilation, vasopressors, colloid boluses, and crystalloid boluses. Our predictions are done in a forward-facing manner to enable "real-time" performance, and predictions are made with a six hour gap time to support clinically actionable planning. We achieve state-of-the-art results on our predictive tasks using deep architectures. We explore the use of feature occlusion to interpret LSTM models, and compare this to the interpretability gained from examining inputs that maximally activate CNN outputs. We show that our models are able to significantly outperform baselines in intervention prediction, and provide insight into model learning, which is crucial for the adoption of such models in practice.
|
[link]
#### Goal: Predict interventions on ICU patients using LSTM and CNN. #### Dataset: MIMIC-III v.1.4 https://mimic.physionet.org/ + Patients over 15 years of age with intensive care stay between 12h and 240h. (Only the first stay is considered for each patient) - 34148 unique records. + 5 static variables. + 29 vital signs and test results. + Clinical notes of patients (presented as time series). #### Feature Engineering: + Topic Modeling of clinical notes: Vector of topics using Latent Dirichlet Allocation (LDA) + Physiological Words: Vital / Laboratory results converted to z-scores - [integer values between -4 and 4] and score is one-hot encoded (each vital / lab is replaced by 9 columns). It is good idea to avoid the imputation of missing values as the physiological word in this case is the all-zero vector. Feature vector: + is the concatenation of the static variables, physiological words for each vital/lab and the topic vector. + 1 feature vector / patient / hour. + 6-hour slice used to predict a 4-hour window after a 6-hour gap. All the features values are normalized between 0 and 1. (static variables are replicated). #### Target Classes: For some of the procedures to be predicted there are 4 classes: + Onset: Y goes from 0 to 1 during the prediction window. + Wean: Y goes from 1 to 0 during the prediction window. + Stay On: Y stays at 1 throughout prediction window. + Stay Off: Y stays at 0 for the entire prediction window. #### Setup of the Experiments: + Dataset Split: 70% training, 10% validation, 20% test. Long Short Term Memory (LSTM) Networks: + Dropout P(keep) = 0.8, L2 regularization. + 2 hidden layers: 512 nodes in each. Convolutional Neural Networks + 3 different temporal granularities (3, 4, 5 hours). 64 filters in each. + Features are treated as channels. 1D temporal convolution. + Dropout between fully connected layers. P (keep) = 0.5. TensorFlow 1.0.1 - Adam optimizer. Minibatches of size 128. Validation set used for early stopping (metric: AUC). #### Results: + Baseline for comparison: L2-regularized Logistic Regression + Metrics: + AUC per class. + AUC macro = Arithmetic mean of AUC per class. + Proposed architectures outperforms baseline. + Physiological words improve performance (especially on high class imbalance scenario). #### Model Interpretability: + LSTM: feature occlusion like analysis. The feature is replaced by uniformly distributed noise between 0 and 1 and variation in AUC is computed. + CNN: analysis of the maximally activating trajectories. #### Positive Aspects: + Relevant work: In the healthcare domain is very important to anticipate events. + Built on top of rich and heterogeneous data: It leverages large amounts of ICU data. + The proposed model is not a complete black-box. Interpretability is crucial if the system is to be adopted in the future. #### Caveats: + Some of the methodology is not clearly explained: + How the split of the dataset was performed? Was it on a patient-level? + When testing the logistic regression baseline it is not clear how the feature vector was built. Was it built by simply flattening the 6-hour chunk? + For the raw data test, it was not mentioned the way the missing values were treated. |