[link]
Summary by Alexander Jung 8 years ago
* They suggest a slightly altered algorithm for GANs.
* The new algorithm is more stable than previous ones.
### How
* Each GAN contains a Generator that generates (fake-)examples and a Discriminator that discriminates between fake and real examples.
* Both fake and real examples can be interpreted as coming from a probability distribution.
* The basis of each GAN algorithm is to somehow measure the difference between these probability distributions
and change the network parameters of G so that the fake-distribution becomes more and more similar to the real distribution.
* There are multiple distance measures to do that:
* Total Variation (TV)
* KL-Divergence (KL)
* Jensen-Shannon divergence (JS)
* This one is based on the KL-Divergence and is the basis of the original GAN, as well as LAPGAN and DCGAN.
* Earth-Mover distance (EM), aka Wasserstein-1
* Intuitively, one can imagine both probability distributions as hilly surfaces. EM then reflects, how much mass has to be moved to convert the fake distribution to the real one.
* Ideally, a distance measure has everywhere nice values and gradients
(e.g. no +/- infinity values; no binary 0 or 1 gradients; gradients that get continously smaller when the generator produces good outputs).
* In that regard, EM beats JS and JS beats TV and KL (roughly speaking). So they use EM.
* EM
* EM is defined as
* 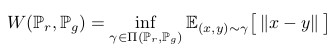
* (inf = infinum, more or less a minimum)
* which is intractable, but following the Kantorovich-Rubinstein duality it can also be calculated via
* 
* (sup = supremum, more or less a maximum)
* However, the second formula is here only valid if the network is a K-Lipschitz function (under every set of parameters).
* This can be guaranteed by simply clipping the discriminator's weights to the range `[-0.01, 0.01]`.
* Then in practice the following version of the tractable EM is used, where `w` are the parameters of the discriminator:
* 
* The full algorithm is mostly the same as for DCGAN:
* 
* Line 2 leads to training the discriminator multiple times per batch (i.e. more often than the generator).
* This is similar to the `max w in W` in the third formula (above).
* This was already part of the original GAN algorithm, but is here more actively used.
* Because of the EM distance, even a "perfect" discriminator still gives good gradient (in contrast to e.g. JS, where the discriminator should not be too far ahead). So the discriminator can be safely trained more often than the generator.
* Line 5 and 10 are derived from EM. Note that there is no more Sigmoid at the end of the discriminator!
* Line 7 is derived from the K-Lipschitz requirement (clipping of weights).
* High learning rates or using momentum-based optimizers (e.g. Adam) made the training unstable, which is why they use a small learning rate with RMSprop.
### Results
* Improved stability. The method converges to decent images with models which failed completely when using JS-divergence (like in DCGAN).
* For example, WGAN worked with generators that did not have batch normalization or only consisted of fully connected layers.
* Apparently no more mode collapse. (Mode collapse in GANs = the generator starts to generate often/always the practically same image, independent of the noise input.)
* There is a relationship between loss and image quality. Lower loss (at the generator) indicates higher image quality. Such a relationship did not exist for JS divergence.
* Example images:
* 


















