[link]
Summary by Alexander Jung 8 years ago
* They suggest a variation of Faster R-CNN.
* Their network detects bounding boxes (e.g. of people, cars) in images *and also* segments the objects within these bounding boxes (i.e. classifies for each pixel whether it is part of the object or background).
* The model runs roughly at the same speed as Faster R-CNN.
### How
* The architecture and training is mostly the same as in Faster R-CNN:
* Input is an image.
* The *backbone* network transforms the input image into feature maps. It consists of convolutions, e.g. initialized with ResNet's weights.
* The *RPN* (Region Proposal Network) takes the feature maps and classifies for each location whether there is a bounding box at that point (with some other stuff to regress height/width and offsets).
This leads to a large number of bounding box candidates (region proposals) per image.
* *RoIAlign*: Each region proposal's "area" is extracted from the feature maps and converted into a fixed-size `7x7xF` feature map (with F input filters). (See below.)
* The *head* uses the region proposal's features to perform
* Classification: "is the bounding box of a person/car/.../background"
* Regression: "bounding box should have width/height/offset so and so"
* Segmentation: "pixels so and so are part of this object's mask"
* Rough visualization of the architecture:
* 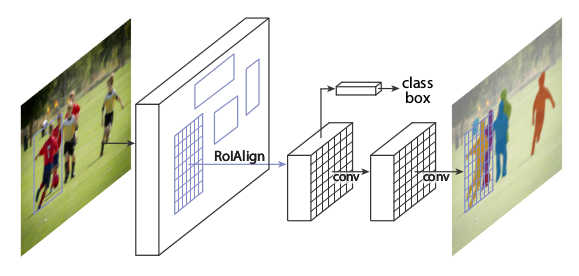
* RoIAlign
* This is very similar to RoIPooling in Faster R-CNN.
* For each RoI, RoIPooling first "finds" the features in the feature maps that lie within the RoI's rectangle. Then it max-pools them to create a fixed size vector.
* Problem: The coordinates where an RoI starts and ends may be non-integers. E.g. the top left corner might have coordinates `(x=2.5, y=4.7)`.
RoIPooling simply rounds these values to the nearest integers (e.g. `(x=2, y=5)`).
But that can create pooled RoIs that are significantly off, as the feature maps with which RoIPooling works have high (total) stride (e.g. 32 pixels in standard ResNets).
So being just one cell off can easily lead to being 32 pixels off on the input image.
* For classification, being some pixels off is usually not that bad. For masks however it can significantly worsen the results, as these have to be pixel-accurate.
* In RoIAlign this is compensated by not rounding the coordinates and instead using bilinear interpolation to interpolate between the feature map's cells.
* Each RoI is pooled by RoIAlign to a fixed sized feature map of size `(H, W, F)`, with H and W usually being 7 or 14. (It can also generate different sizes, e.g. `7x7xF` for classification and more accurate `14x14xF` for masks.)
* If H and W are `7`, this leads to `49` cells within each plane of the pooled feature maps.
* Each cell again is a rectangle -- similar to the RoIs -- and pooled with bilinear interpolation.
More exactly, each cell is split up into four sub-cells (top left, top right, bottom right, bottom left).
Each of these sub-cells is pooled via bilinear interpolation, leading to four values per cell.
The final cell value is then computed using either an average or a maximum over the four sub-values.
* Segmentation
* They add an additional branch to the *head* that gets pooled RoI as inputs and processes them seperately from the classification and regression (no connections between the branches).
* That branch does segmentation. It is fully convolutional, similar to many segmentation networks.
* The result is one mask per class.
* There is no softmax per pixel over the classes, as classification is done by a different branch.
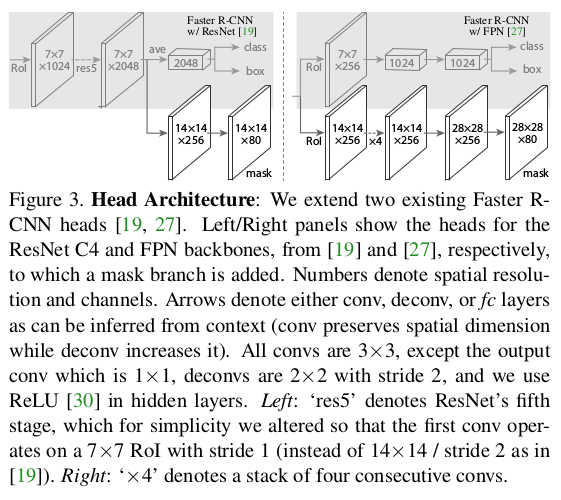
* Base networks
* Their *backbone* networks are either ResNet or ResNeXt (in the 50 or 102 layer variations).
* Their *head* is either the fourth/fifth module from ResNet/ResNeXt (called *C4* (fourth) or *C5* (fifth)) or they use the second half from the FPN network (called *FPN*).
* They denote their networks via `backbone-head`, i.e. ResNet-101-FPN means that their backbone is ResNet-101 and their head is FPN.
* Visualization of the different heads:
* 
* Training
* Training happens in basically the same way as Faster R-CNN.
* They just add an additional loss term to the total loss (`L = L_classification + L_regression + L_mask`). `L_mask` is based on binary cross-entropy.
* For each predicted RoI, the correct mask is the intersection between that RoI's area and the correct mask.
* They only train masks for RoIs that are positive (overlap with ground truth bounding boxes).
* They train for 120k iterations at learning rate 0.02 and 40k at 0.002 with weight decay 0.0002 and momentum 0.9.
* Test
* For the *C4*-head they sample up to 300 region proposals from the RPN (those with highest confidence values). For the FPN head they sample up to 1000, as FPN is faster.
* They sample masks only for the 100 proposals with highest confidence values.
* Each mask is turned into a binary mask using a threshold of 0.5.
### Results
* Instance Segmentation
* They train and test on COCO.
* They can outperform the best competitor by a decent margin (AP 37.1 vs 33.6 for FCIS+++ with OHEM).
* Their model especially performs much better when there is overlap between bounding boxes.
* Ranking of their models: ResNeXt-101-FPN > ResNet-101-FPN > ResNet-50-FPN > ResNet-101-C4 > ResNet-50-C4.
* Using sigmoid instead of softmax (over classes) for the mask prediction significantly improves results by 5.5 to 7.1 points AP (depending on measurement method).
* Predicting only one mask per RoI (class-agnostic) instead of C masks (where C is the number of classes) only has a small negative effect on AP (about 0.6 points).
* Using RoIAlign instead of RoIPooling has significant positive effects on the AP of around 5 to 10 points (if a network with C5 head is chosen, which has a high stride of 32). Effects are smaller for small strides and FPN head.
* Using fully convolutional networks for the mask branch performs better than fully connected layers (1-3 points AP).
* Examples results on COCO vs FCIS (note the better handling of overlap):
* 
* Bounding-Box-Detection
* Training additionally on masks seems to improve AP for bounding boxes by around 1 point (benefit from multi-task learning).
* Timing
* Around 200ms for ResNet-101-FPN. (M40 GPU)
* Around 400ms for ResNet-101-C4.
* Human Pose Estimation
* The mask branch can be used to predict keypoint (landmark) locations on human bodies (i.e. locations of hands, feet etc.).
* This is done by using one mask per keypoint, initializing it to `0` and setting the keypoint location to `1`.
* By doing this, Mask R-CNN can predict keypoints roughly as good as the current leading models (on COCO), while running at 5fps.
* Cityscapes
* They test their model on the cityscapes dataset.
* They beat previous models with significant margins. This is largely due to their better handling of overlapping instances.
* They get their best scores using a model that was pre-trained on COCO.
* Examples results on cityscapes:
* 




















