Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp













[link]
* Previously, methods to detect bounding boxes in images were often based on the combination of manual feature extraction with SVMs.
* They replace the manual feature extraction with a CNN, leading to significantly higher accuracy.
* They use supervised pre-training on auxiliary datasets to deal with the small amount of labeled data (instead of the sometimes used unsupervised pre-training).
* They call their method R-CNN ("Regions with CNN features").
### How
* Their system has three modules: 1) Region proposal generation, 2) CNN-based feature extraction per region proposal, 3) classification.
* 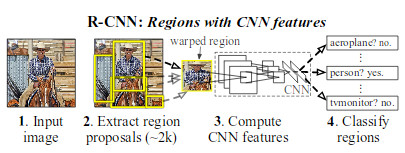
* Region proposals generation
* A region proposal is a bounding box candidate that *might* contain an object.
* By default they generate 2000 region proposals per image.
* They suggest "simple" (i.e. not learned) algorithms for this step (e.g. objectneess, selective search, CPMC).
* They use selective search (makes it comparable to previous systems).
* CNN features
* Uses a CNN to extract features, applied to each region proposal (replaces the previously used manual feature extraction).
* So each region proposal ist turned into a fixed length vector.
* They use AlexNet by Krizhevsky et al. as their base CNN (takes 227x227 RGB images, converts them into 4096-dimensional vectors).
* They add `p=16` pixels to each side of every region proposal, extract the pixels and then simply resize them to 227x227 (ignoring aspect ratio, so images might end up distorted).
* They generate one 4096d vector per image, which is less than what some previous manual feature extraction methods used. That enables faster classification, less memory usage and thus more possible classes.
* Classification
* A classifier that receives the extracted feature vectors (one per region proposal) and classifies them into a predefined set of available classes (e.g. "person", "car", "bike", "background / no object").
* They use one SVM per available class.
* The regions that were not classified as background might overlap (multiple bounding boxes on the same object).
* They use greedy non-maximum suppresion to fix that problem (for each class individually).
* That method simply rejects regions if they overlap strongly with another region that has higher score.
* Overlap is determined via Intersection of Union (IoU).
* Training method
* Pre-Training of CNN
* They use AlexNet pretrained on Imagenet (1000 classes).
* They replace the last fully connected layer with a randomly initialized one that leads to `C+1` classes (`C` object classes, `+1` for background).
* Fine-Tuning of CNN
* The use SGD with learning rate `0.001`.
* Batch size is 128 (32 positive windows, 96 background windows).
* A region proposal is considered positive, if its IoU with any ground-truth bounding box is `>=0.5`.
* SVM
* They train one SVM per class via hard negative mining.
* For positive examples they use here an IoU threshold of `>=0.3`, which performed better than 0.5.
### Results
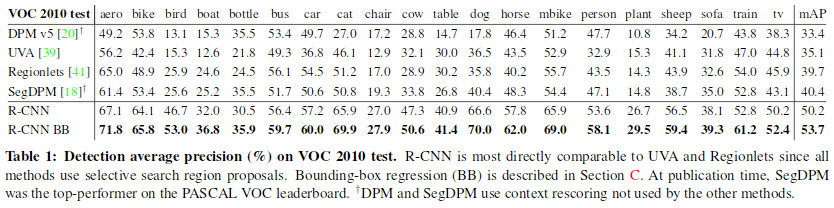
* Pascal VOC 2010
* They: 53.7% mAP
* Closest competitor (SegDPM): 40.4% mAP
* Closest competitor that uses the same region proposal method (UVA): 35.1% mAP
* 
* ILSVRC2013 detection
* They: 31.4% mAP
* Closest competitor (OverFeat): 24.3% mAP
* The feed a large number of region proposals through the network and log for each filter in the last conv-layer which images activated it the most:
* 
* Usefulness of layers:
* They remove later layers of the network and retrain in order to find out which layers are the most useful ones.
* Their result is that both fully connected layers of AlexNet seemed to be very domain-specific and profit most from fine-tuning.
* Using VGG16:
* Using VGG16 instead of AlexNet increased mAP from 58.5% to 66.0% on Pascal VOC 2007.
* Computation time was 7 times higher.
* They train a linear regression model that improves the bounding box dimensions based on the extracted features of the last pooling layer. That improved their mAP by 3-4 percentage points.
* The region proposals generated by selective search have a recall of 98% on Pascal VOC and 91.6% on ILSVRC2013 (measured by IoU of `>=0.5`).

Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
