Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification
Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa
ACM Transactions on Graphics (Proc. of SIGGRAPH 2016) - 2016 via Local
Keywords:
Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa
ACM Transactions on Graphics (Proc. of SIGGRAPH 2016) - 2016 via Local
Keywords:













[link]
https://www.youtube.com/watch?v=MfaTOXxA8dM 
Your comment:
|

|
[link]
* They present a model which adds color to grayscale images (e.g. to old black and white images).
* It works best with 224x224 images, but can handle other sizes too.
### How
* Their model has three feature extraction components:
* Low level features:
* Receives 1xHxW images and outputs 512xH/8xW/8 matrices.
* Uses 6 convolutional layers (3x3, strided, ReLU) for that.
* Global features:
* Receives the low level features and converts them to 256 dimensional vectors.
* Uses 4 convolutional layers (3x3, strided, ReLU) and 3 fully connected layers (1024 -> 512 -> 256; ReLU) for that.
* Mid-level features:
* Receives the low level features and converts them to 256xH/8xW/8 matrices.
* Uses 2 convolutional layers (3x3, ReLU) for that.
* The global and mid-level features are then merged with a Fusion Layer.
* The Fusion Layer is basically an extended convolutional layer.
* It takes the mid-level features (256xH/8xW/8) and the global features (256) as input and outputs a matrix of shape 256xH/8xW/8.
* It mostly operates like a normal convolutional layer on the mid-level features. However, its weight matrix is extended to also include weights for the global features (which will be added at every pixel).
* So they use something like `fusion at pixel u,v = sigmoid(bias + weights * [global features, mid-level features at pixel u,v])` - and that with 256 different weight matrices and biases for 256 filters.
* After the Fusion Layer they use another network to create the coloring:
* This network receives 256xH/8xW/8 matrices (merge of global and mid-level features) and generates 2xHxW outputs (color in L\*a\*b\* color space).
* It uses a few convolutional layers combined with layers that do nearest neighbour upsampling.
* The loss for the colorization network is a MSE based on the true coloring.
* They train the global feature extraction also on the true class labels of the used images.
* Their model can handle any sized image. If the image doesn't have a size of 224x224, it must be resized to 224x224 for the gobal feature extraction. The mid-level feature extraction only uses convolutions, therefore it can work with any image size.
### Results
* The training set that they use is the "Places scene dataset".
* After cleanup the dataset contains 2.3M training images (205 different classes) and 19k validation images.
* Users rate images colored by their method in 92.6% of all cases as real-looking (ground truth: 97.2%).
* If they exclude global features from their method, they only achieve 70% real-looking images.
* They can also extract the global features from image A and then use them on image B. That transfers the style from A to B. But it only works well on semantically similar images.
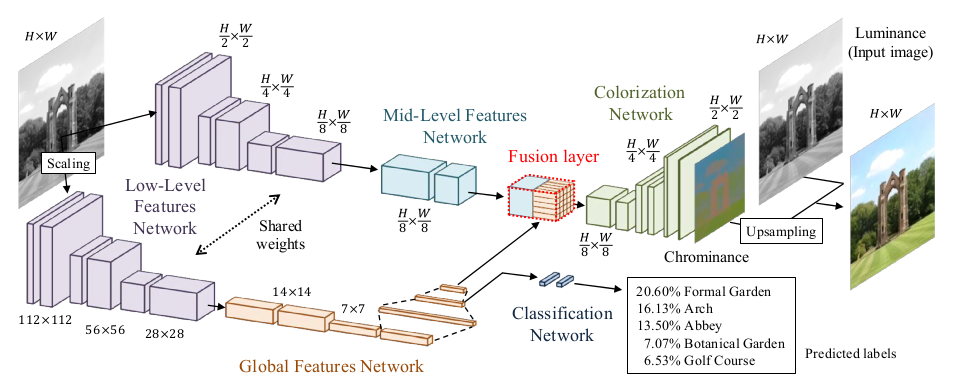
*Architecture of their model.*

*Their model applied to old images.*
--------------------
# Rough chapter-wise notes
* (1) Introduction
* They use a CNN to color images.
* Their network extracts global priors and local features from grayscale images.
* Global priors:
* Extracted from the whole image (e.g. time of day, indoor or outdoors, ...).
* They use class labels of images to train those. (Not needed during test.)
* Local features: Extracted from small patches (e.g. texture).
* They don't generate a full RGB image, instead they generate the chrominance map using the CIE L\*a\*b\* colorspace.
* Components of the model:
* Low level features network: Generated first.
* Mid level features network: Generated based on the low level features.
* Global features network: Generated based on the low level features.
* Colorization network: Receives mid level and global features, which were merged in a fusion layer.
* Their network can process images of arbitrary size.
* Global features can be generated based on another image to change the style of colorization, e.g. to change the seasonal colors from spring to summer.
* (3) Joint Global and Local Model
* <repetition of parts of the introduction>
* They mostly use ReLUs.
* (3.1) Deep Networks
* <standard neural net introduction>
* (3.2) Fusing Global and Local Features for Colorization
* Global features are used as priors for local features.
* (3.2.1) Shared Low-Level Features
* The low level features are which's (low level) features are fed into the networks of both the global and the medium level features extractors.
* They generate them from the input image using a ConvNet with 6 layers (3x3, 1x1 padding, strided/no pooling, ends in 512xH/8xW/8).
* (3.2.2) Global Image Features
* They process the low level features via another network into global features.
* That network has 4 conv-layers (3x3, 2 strided layers, all 512 filters), followed by 3 fully connected layers (1024, 512, 256).
* Input size (of low level features) is expected to be 224x224.
* (3.2.3) Mid-Level Features
* Takes the low level features (512xH/8xW/8) and uses 2 conv layers (3x3) to transform them to 256xH/8xW/8.
* (3.2.4) Fusing Global and Local Features
* The Fusion Layer is basically an extended convolutional layer.
* It takes the mid-level features (256xH/8xW/8) and the global features (256) as input and outputs a matrix of shape 256xH/8xW/8.
* It mostly operates like a normal convolutional layer on the mid-level features. However, its weight matrix is extended to also include weights for the global features (which will be added at every pixel).
* So they use something like `fusion at pixel u,v = sigmoid(bias + weights * [global features, mid-level features at pixel u,v])` - and that with 256 different weight matrices and biases for 256 filters.
* (3.2.5) Colorization Network
* The colorization network receives the 256xH/8xW/8 matrix from the fusion layer and transforms it to the 2xHxW chrominance map.
* It basically uses two upsampling blocks, each starting with a nearest neighbour upsampling layer, followed by 2 3x3 convs.
* The last layer uses a sigmoid activation.
* The network ends in a MSE.
* (3.3) Colorization with Classification
* To make training more effective, they train parts of the global features network via image class labels.
* I.e. they take the output of the 2nd fully connected layer (at the end of the global network), add one small hidden layer after it, followed by a sigmoid output layer (size equals number of class labels).
* They train that with cross entropy. So their global loss becomes something like `L = MSE(color accuracy) + alpha*CrossEntropy(class labels accuracy)`.
* (3.4) Optimization and Learning
* Low level feature extraction uses only convs, so they can be extracted from any image size.
* Global feature extraction uses fc layers, so they can only be extracted from 224x224 images.
* If an image has a size unequal to 224x224, it must be (1) resized to 224x224, fed through low level feature extraction, then fed through the global feature extraction and (2) separately (without resize) fed through the low level feature extraction and then fed through the mid-level feature extraction.
* However, they only trained on 224x224 images (for efficiency).
* Augmentation: 224x224 crops from 256x256 images; random horizontal flips.
* They use Adadelta, because they don't want to set learning rates. (Why not adagrad/adam/...?)
* (4) Experimental Results and Discussion
* They set the alpha in their loss to `1/300`.
* They use the "Places scene dataset". They filter images with low color variance (including grayscale images). They end up with 2.3M training images and 19k validation images. They have 205 classes.
* Batch size: 128.
* They train for about 11 epochs.
* (4.1) Colorization results
* Good looking colorization results on the Places scene dataset.
* (4.2) Comparison with State of the Art
* Their method succeeds where other methods fail.
* Their method can handle very different kinds of images.
* (4.3) User study
* When rated by users, 92.6% think that their coloring is real (ground truth: 97.2%).
* Note: Users were told to only look briefly at the images.
* (4.4) Importance of Global Features
* Their model *without* global features only achieves 70% user rating.
* There are too many ambiguities on the local level.
* (4.5) Style Transfer through Global Features
* They can perform style transfer by extracting the global features of image B and using them for image A.
* (4.6) Colorizing the past
* Their model performs well on old images despite the artifacts commonly found on those.
* (4.7) Classification Results
* Their method achieves nearly as high classification accuracy as VGG (see classification loss for global features).
* (4.8) Comparison of Color Spaces
* L\*a\*b\* color space performs slightly better than RGB and YUV, so they picked that color space.
* (4.9) Computation Time
* One image is usually processed within seconds.
* CPU takes roughly 5x longer.
* (4.10) Limitations and Discussion
* Their approach is data driven, i.e. can only deal well with types of images that appeared in the dataset.
* Style transfer works only really well for semantically similar images.
* Style transfer cannot necessarily transfer specific colors, because the whole model only sees the grayscale version of the image.
* Their model tends to strongly prefer the most common color for objects (e.g. grass always green).
Your comment:
You must log in before you can post this comment!
|


You must log in before you can submit this summary! Your draft will not be saved!
Preview:
