Self-Normalizing Neural Networks
Günter Klambauer and Thomas Unterthiner and Andreas Mayr and Sepp Hochreiter
arXiv e-Print archive - 2017 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2017/06/08 (6 years ago)
Abstract: Deep Learning has revolutionized vision via convolutional neural networks (CNNs) and natural language processing via recurrent neural networks (RNNs). However, success stories of Deep Learning with standard feed-forward neural networks (FNNs) are rare. FNNs that perform well are typically shallow and, therefore cannot exploit many levels of abstract representations. We introduce self-normalizing neural networks (SNNs) to enable high-level abstract representations. While batch normalization requires explicit normalization, neuron activations of SNNs automatically converge towards zero mean and unit variance. The activation function of SNNs are "scaled exponential linear units" (SELUs), which induce self-normalizing properties. Using the Banach fixed-point theorem, we prove that activations close to zero mean and unit variance that are propagated through many network layers will converge towards zero mean and unit variance -- even under the presence of noise and perturbations. This convergence property of SNNs allows to (1) train deep networks with many layers, (2) employ strong regularization, and (3) to make learning highly robust. Furthermore, for activations not close to unit variance, we prove an upper and lower bound on the variance, thus, vanishing and exploding gradients are impossible. We compared SNNs on (a) 121 tasks from the UCI machine learning repository, on (b) drug discovery benchmarks, and on (c) astronomy tasks with standard FNNs and other machine learning methods such as random forests and support vector machines. SNNs significantly outperformed all competing FNN methods at 121 UCI tasks, outperformed all competing methods at the Tox21 dataset, and set a new record at an astronomy data set. The winning SNN architectures are often very deep. Implementations are available at: github.com/bioinf-jku/SNNs.
more
less
Günter Klambauer and Thomas Unterthiner and Andreas Mayr and Sepp Hochreiter
arXiv e-Print archive - 2017 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2017/06/08 (6 years ago)
Abstract: Deep Learning has revolutionized vision via convolutional neural networks (CNNs) and natural language processing via recurrent neural networks (RNNs). However, success stories of Deep Learning with standard feed-forward neural networks (FNNs) are rare. FNNs that perform well are typically shallow and, therefore cannot exploit many levels of abstract representations. We introduce self-normalizing neural networks (SNNs) to enable high-level abstract representations. While batch normalization requires explicit normalization, neuron activations of SNNs automatically converge towards zero mean and unit variance. The activation function of SNNs are "scaled exponential linear units" (SELUs), which induce self-normalizing properties. Using the Banach fixed-point theorem, we prove that activations close to zero mean and unit variance that are propagated through many network layers will converge towards zero mean and unit variance -- even under the presence of noise and perturbations. This convergence property of SNNs allows to (1) train deep networks with many layers, (2) employ strong regularization, and (3) to make learning highly robust. Furthermore, for activations not close to unit variance, we prove an upper and lower bound on the variance, thus, vanishing and exploding gradients are impossible. We compared SNNs on (a) 121 tasks from the UCI machine learning repository, on (b) drug discovery benchmarks, and on (c) astronomy tasks with standard FNNs and other machine learning methods such as random forests and support vector machines. SNNs significantly outperformed all competing FNN methods at 121 UCI tasks, outperformed all competing methods at the Tox21 dataset, and set a new record at an astronomy data set. The winning SNN architectures are often very deep. Implementations are available at: github.com/bioinf-jku/SNNs.













[link]
_Objective:_ Design Feed-Forward Neural Network (fully connected) that can be trained even with very deep architectures.
* _Dataset:_ [MNIST](yann.lecun.com/exdb/mnist/), [CIFAR10](https://www.cs.toronto.edu/%7Ekriz/cifar.html), [Tox21](https://tripod.nih.gov/tox21/challenge/) and [UCI tasks](https://archive.ics.uci.edu/ml/datasets/optical+recognition+of+handwritten+digits).
* _Code:_ [here](https://github.com/bioinf-jku/SNNs)
## Inner-workings:
They introduce a new activation functio the Scaled Exponential Linear Unit (SELU) which has the nice property of making neuron activations converge to a fixed point with zero-mean and unit-variance.
They also demonstrate that upper and lower bounds and the variance and mean for very mild conditions which basically means that there will be no exploding or vanishing gradients.
The activation function is:
[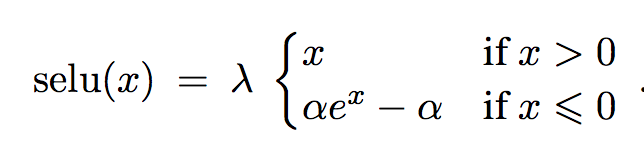](https://user-images.githubusercontent.com/17261080/27125901-1a4f7276-50f6-11e7-857d-ebad1ac94789.png)
With specific parameters for alpha and lambda to ensure the previous properties. The tensorflow impementation is:
def selu(x):
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale*np.where(x>=0.0, x, alpha*np.exp(x)-alpha)
They also introduce a new dropout (alpha-dropout) to compensate for the fact that [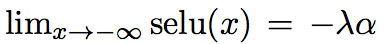](https://user-images.githubusercontent.com/17261080/27126174-e67d212c-50f6-11e7-8952-acad98b850be.png)
## Results:
Batch norm becomes obsolete and they are also able to train deeper architectures. This becomes a good choice to replace shallow architectures where random forest or SVM used to be the best results. They outperform most other techniques on small datasets.
[](https://user-images.githubusercontent.com/17261080/27125798-bd04c256-50f5-11e7-8a74-b3b6a3fe82ee.png)
Might become a new standard for fully-connected activations in the future.

Your comment:
|

|
[link]
"Using the "SELU" activation function, you get better results than any other activation function, and you don't have to do batch normalization. The "SELU" activation function is:
if x<0, 1.051\*(1.673\*e^x-1.673) if x>0, 1.051\*x"
Source: narfon2, reddit
```
import numpy as np
def selu(x):
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale*np.where(x>=0.0, x, alpha*np.exp(x)-alpha)
```
Source: CaseOfTuesday, reddit
Discussion here: https://www.reddit.com/r/MachineLearning/comments/6g5tg1/r_selfnormalizing_neural_networks_improved_elu/
Your comment:
You must log in before you can post this comment!
|


|
[link]
https://github.com/bioinf-jku/SNNs
* They suggest a variation of ELUs, which leads to networks being automatically normalized.
* The effects are comparable to Batch Normalization, while requiring significantly less computation (barely more than a normal ReLU).
### How
* They define Self-Normalizing Neural Networks (SNNs) as neural networks, which automatically keep their activations at zero-mean and unit-variance (per neuron).
* SELUs
* They use SELUs to turn their networks into SNNs.
* Formula:
* 
* with `alpha = 1.6733` and `lambda = 1.0507`.
* They proof that with properly normalized weights the activations approach a fixed point of zero-mean and unit-variance. (Different settings for alpha and lambda can lead to other fixed points.)
* They proof that this is still the case when previous layer activations and weights do not have optimal values.
* They proof that this is still the case when the variance of previous layer activations is very high or very low and argue that the mean of those activations is not so important.
* Hence, SELUs with these hyperparameters should have self-normalizing properties.
* SELUs are here used as a basis because:
1. They can have negative and positive values, which allows to control the mean.
2. They have saturating regions, which allows to dampen high variances from previous layers.
3. They have a slope larger than one, which allows to increase low variances from previous layers.
4. They generate a continuous curve, which ensures that there is a fixed point between variance damping and increasing.
* ReLUs, Leaky ReLUs, Sigmoids and Tanhs do not offer the above properties.
* Initialization
* SELUs for SNNs work best with normalized weights.
* They suggest to make sure per layer that:
1. The first moment (sum of weights) is zero.
2. The second moment (sum of squared weights) is one.
* This can be done by drawing weights from a normal distribution `N(0, 1/n)`, where `n` is the number of neurons in the layer.
* Alpha-dropout
* SELUs don't perform as well with normal Dropout, because their point of low variance is not 0.
* They suggest a modification of Dropout called Alpha-dropout.
* In this technique, values are not dropped to 0 but to `alpha' = -lambda * alpha = -1.0507 * 1.6733 = -1.7581`.
* Similar to dropout, activations are changed during training to compensate for the dropped units.
* Each activation `x` is changed to `a(xd+alpha'(1-d))+b`.
* `d = B(1, q)` is the dropout variable consisting of 1s and 0s.
* `a = (q + alpha'^2 q(1-q))^(-1/2)`
* `b = -(q + alpha'^2 q(1-q))^(-1/2) ((1-q)alpha')`
* They made good experiences with dropout rates around 0.05 to 0.1.
### Results
* Note: All of their tests are with fully connected networks. No convolutions.
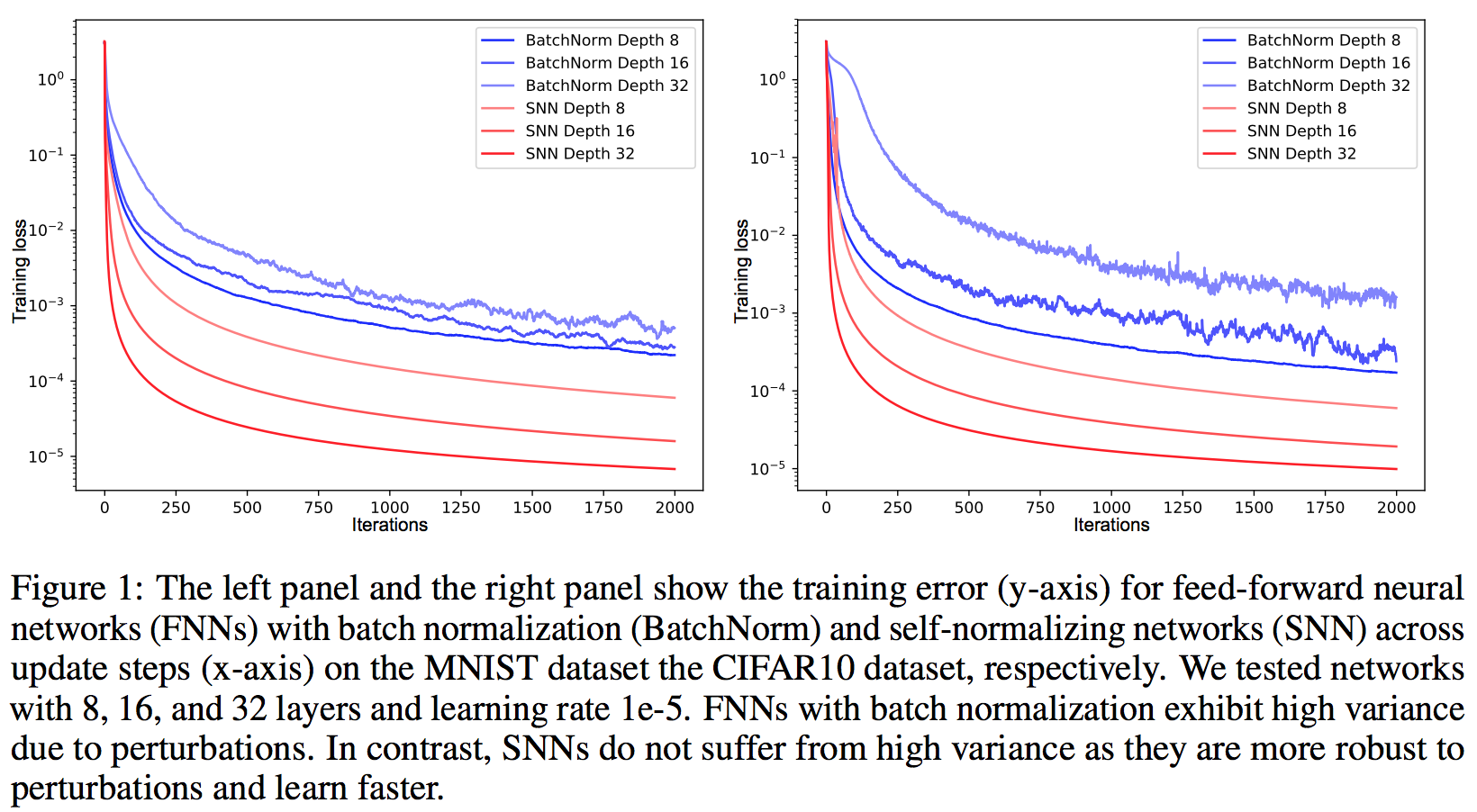
* Example training results:
* 
* Left: MNIST, Right: CIFAR10
* Networks have N layers each, see legend. No convolutions.
* 121 UCI Tasks
* They manage to beat SVMs and RandomForests, while other networks (Layer Normalization, BN, Weight Normalization, Highway Networks, ResNet) perform significantly worse than their network (and usually don't beat SVMs/RFs).
* Tox21
* They achieve better results than other networks (again, Layer Normalization, BN, etc.).
* They achive almost the same result as the so far best model on the dataset, which consists of a mixture of neural networks, SVMs and Random Forests.
* HTRU2
* They achieve better results than other networks.
* They beat the best non-neural method (Naive Bayes).
* Among all tested other networks, MSRAinit performs best, which references a network withput any normalization, only ReLUs and Microsoft Weight Initialization (see paper: `Delving deep into rectifiers: Surpassing human-level performance on imagenet classification`).
Your comment:
You must log in before you can post this comment!
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
