
arXiv is an e-print service in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance and statistics.
- 1996 1
- 2010 1
- 2011 1
- 2012 7
- 2013 29
- 2014 40
- 2015 130
- 2016 229
- 2017 179
- 2018 138
- 2019 95
- 2020 32
- 2021 10
- 2022 7
- 2023 3
Compressive Transformers for Long-Range Sequence Modelling
Rae, Jack W. and Potapenko, Anna and Jayakumar, Siddhant M. and Lillicrap, Timothy P.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Rae, Jack W. and Potapenko, Anna and Jayakumar, Siddhant M. and Lillicrap, Timothy P.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp













[link]
This paper is an interesting extension of earlier work, in the TransformerXL paper, that sought to give Transformers access to a "memory" beyond the scope of the subsequence where full self-attention was being performed. This was done by caching the activations from prior subsequences, and making them available to the subsequence currently being calculated in a "read-only" way, with gradients not propagated backwards. This had the effect of (1) reducing the maximum memory size compared to simply doubling the subsequence length, and (2) reducing the extent to which gradients had to propagate backward through time. The authors of the Compressive Transformers paper want to build on that set of ideas to construct an even longer accessible memory. So, they take the baseline non-backpropogated memory design of TransformerXL, but instead of having tokens roll out of memory after the end of the previous (cached) subsequence, they create an extra compressed memory. Each token in this compressed memory is a function of C inputs in the normal memory. So, if C=3, you would input 3 memory vectors into your compression function to get one instance of a compressed memory vector. Depending on the scale of your C, you can turn up the temporal distance into the past that your compressed memory had to. https://i.imgur.com/7BaCzoU.png While the gradients from the main loss function didn't, as far as I could tell, pass back into the compression function, they did apply a compression loss to incentivize the compression to be coherent. They considered an autoencoder loss to reconstruct the input tokens from the compressed memory, but decided against that on the principle that memory inherently has to be compressed and lossy to be effective, and an autoencoder loss would promote infeasibly lossless compression. Instead, they take the interesting approach of incentivizing the compressed representations to be able to reconstruct the attention calculation performed on the pre-compressed representations. Basically, any information pulled out of the pre-compressed memories by content-based lookup also needs to be able to be pulled out of the compressed memories. This incentives the network to preferentially keep the information that was being actively used by the attention mechanisms in prior steps, and discard less useful information. One framing from this paper that I enjoyed was them drawing a comparison between the approach of Transformers (of keeping all lower-level activations in memory, and recombining them "in real time," for each downstream use of that information), and the approach of RNNs (of keeping a running compressed representation of everything seen up to this point). In this frame, their method is somewhere in between, with a tunable compression rate C (by contrast, a RNN would have an effectively unlimited compression rate, since all prior tokens would be compressed into a single state representation).  |

Learning to learn via Self-Critique
Antoniou, Antreas and Storkey, Amos J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Antoniou, Antreas and Storkey, Amos J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
### Key points - Instead of just focusing on supervised learning, a self-critique and adapt network provides a unsupervised learning approach in improving the overall generalization. It does this via transductive learning by learning a label-free loss function from the validation set to improve the base model. - The SCA framework helps a learning algorithm be more robust by learning more relevant features and improve during the training phase. ### Ideas 1. Combine deep learning models with SCA that help improve genearlization when we data is fed into these large networks. 2. Build a SCA that focuses not on learning a label-free loss function but on learning quality of a concept. ### Review Overall, the paper present a novel idea that offers a unsupervised learning method to assist a supervised learning model to improve its performance. Implementation of this SCA framework is straightforward and demonstrates promising results. This approach is finally contributing to the actual theory of meta-learning and learning to learn research field. SCA framework is a new step towards self-adaptive learning systems. Unfortunately, the experimentation is insufficient and provided little insight into how this framework can help in cases where task domains vary in distribution or in concept. |

Exploring the Origins and Prevalence of Texture Bias in Convolutional Neural Networks
Hermann, Katherine L. and Kornblith, Simon
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Hermann, Katherine L. and Kornblith, Simon
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
When humans classify images, we tend to use high-level information about the shape and position of the object. However, when convolutional neural networks classify images,, they tend to use low-level, or textural, information more than high-level shape information. This paper tries to understand what factors lead to higher shape bias or texture bias. To investigate this, the authors look at three datasets with disagreeing shape and texture labels. The first is GST, or Geirhos Style Transfer. In this dataset, style transfer is used to render the content of one class in the style of another (for example, a cat shape in the texture of an elephant). In the Navon dataset, a large-scale letter is rendered by tiling smaller letters. And, in the ImageNet-C dataset, a given class is rendered with a particular kind of distortion; here the distortion is considered to be the "texture label". In the rest of the paper, "shape bias" refers to the extent to which a model trained on normal images will predict the shape label rather than the texture label associated with a GST image. The other datasets are used in experiments where a model explicitly tries to learn either shape or texture. https://i.imgur.com/aw1MThL.png To start off, the authors try to understand whether CNNs are inherently more capable of learning texture information rather than shape information. To do this, they train models on either the shape or the textural label on each of the three aforementioned datasets. On GST and Navon, shape labels can be learned faster and more efficiently than texture ones. On ImageNet-C (i.e. distorted ImageNet), it seems to be easier to learn texture than texture, but recall here that texture corresponds to the type of noise, and I imagine that the cardinality of noise types is far smaller than that of ImageNet images, so I'm not sure how informative this comparison is. Overall, this experiment suggests that CNNs are able to learn from shape alone without low-level texture as a clue, in cases where the two sources of information disagree The paper moves on to try to understand what factors about a normal ImageNet model give it higher or lower shape bias - that is, a higher or lower likelihood of classifying a GST image according to its shape rather than texture. Predictably, data augmentations have an effect here. When data is augmented with aggressive random cropping, this increases texture bias relative to shape bias, presumably because when large chunks of an object are cropped away, its overall shape becomes a less useful feature. Center cropping is better for shape bias, probably because objects are likely to be at the center of the image, so center cropping has less of a chance of distorting them. On the other hand, more "naturalistic" augmentations like adding Gaussian noise or distorting colors lead to a higher shape bias in the resulting networks, up to 60% with all the modifications. However, the authors also find that pushing the shape bias up has the result of dropping final test accuracy. https://i.imgur.com/Lb6RMJy.png Interestingly, while the techniques that increase shape bias seem to also harm performance, the authors also find that higher-performing models tend to have higher shape bias (though with texture bias still outweighing shape) suggesting that stronger models learn how to use shape more effectively, but also that handicapping models' ability to use texture in order to incentivize them to use shape tends to hurt performance overall. Overall, my take from this paper is that texture-level data is actually statistically informative and useful for classification - even in terms of generalization - even if is too high-resolution to be useful as a visual feature for humans. CNNs don't seem inherently incapable of learning from shape, but removing their ability to rely on texture seems to lead to a notable drop in accuracy, suggesting there was real signal there that we're losing out on.
1 Comments
 |
Better-than-Demonstrator Imitation Learning via Automatically-Ranked Demonstrations
Daniel S. Brown and Wonjoon Goo and Scott Niekum
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/07/09 (4 years ago)
Abstract: The performance of imitation learning is typically upper-bounded by the performance of the demonstrator. While recent empirical results demonstrate that ranked demonstrations allow for better-than-demonstrator performance, preferences over demonstrations may be difficult to obtain, and little is known theoretically about when such methods can be expected to successfully extrapolate beyond the performance of the demonstrator. To address these issues, we first contribute a sufficient condition for better-than-demonstrator imitation learning and provide theoretical results showing why preferences over demonstrations can better reduce reward function ambiguity when performing inverse reinforcement learning. Building on this theory, we introduce Disturbance-based Reward Extrapolation (D-REX), a ranking-based imitation learning method that injects noise into a policy learned through behavioral cloning to automatically generate ranked demonstrations. These ranked demonstrations are used to efficiently learn a reward function that can then be optimized using reinforcement learning. We empirically validate our approach on simulated robot and Atari imitation learning benchmarks and show that D-REX outperforms standard imitation learning approaches and can significantly surpass the performance of the demonstrator. D-REX is the first imitation learning approach to achieve significant extrapolation beyond the demonstrator's performance without additional side-information or supervision, such as rewards or human preferences. By generating rankings automatically, we show that preference-based inverse reinforcement learning can be applied in traditional imitation learning settings where only unlabeled demonstrations are available.
more
less
Daniel S. Brown and Wonjoon Goo and Scott Niekum
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/07/09 (4 years ago)
Abstract: The performance of imitation learning is typically upper-bounded by the performance of the demonstrator. While recent empirical results demonstrate that ranked demonstrations allow for better-than-demonstrator performance, preferences over demonstrations may be difficult to obtain, and little is known theoretically about when such methods can be expected to successfully extrapolate beyond the performance of the demonstrator. To address these issues, we first contribute a sufficient condition for better-than-demonstrator imitation learning and provide theoretical results showing why preferences over demonstrations can better reduce reward function ambiguity when performing inverse reinforcement learning. Building on this theory, we introduce Disturbance-based Reward Extrapolation (D-REX), a ranking-based imitation learning method that injects noise into a policy learned through behavioral cloning to automatically generate ranked demonstrations. These ranked demonstrations are used to efficiently learn a reward function that can then be optimized using reinforcement learning. We empirically validate our approach on simulated robot and Atari imitation learning benchmarks and show that D-REX outperforms standard imitation learning approaches and can significantly surpass the performance of the demonstrator. D-REX is the first imitation learning approach to achieve significant extrapolation beyond the demonstrator's performance without additional side-information or supervision, such as rewards or human preferences. By generating rankings automatically, we show that preference-based inverse reinforcement learning can be applied in traditional imitation learning settings where only unlabeled demonstrations are available.
|
[link]
## General Framework Extends T-REX (see [summary](https://www.shortscience.org/paper?bibtexKey=journals/corr/1904.06387&a=muntermulehitch)) so that preferences (rankings) over demonstrations are generated automatically (back to the common IL/IRL setting where we only have access to a set of unlabeled demonstrations). Also derives some theoretical requirements and guarantees for better-than-demonstrator performance. ## Motivations * Preferences over demonstrations may be difficult to obtain in practice. * There is no theoretical understanding of the requirements that lead to outperforming demonstrator. ## Contributions * Theoretical results (with linear reward function) on when better-than-demonstrator performance is possible: 1- the demonstrator must be suboptimal (room for improvement, obviously), 2- the learned reward must be close enough to the reward that the demonstrator is suboptimally optimizing for (be able to accurately capture the intent of the demonstrator), 3- the learned policy (optimal wrt the learned reward) must be close enough to the optimal policy (wrt to the ground truth reward). Obviously if we have 2- and a good enough RL algorithm we should have 3-, so it might be interesting to see if one can derive a requirement from only 1- and 2- (and possibly a good enough RL algo). * Theoretical results (with linear reward function) showing that pairwise preferences over demonstrations reduce the error and ambiguity of the reward learning. They show that without rankings two policies might have equal performance under a learned reward (that makes expert's demonstrations optimal) but very different performance under the true reward (that makes the expert optimal everywhere). Indeed, the expert's demonstration may reveal very little information about the reward of (suboptimal or not) unseen regions which may hurt very much the generalizations (even with RL as it would try to generalize to new states under a totally wrong reward). They also show that pairwise preferences over trajectories effectively give half-space constraints on the feasible reward function domain and thus may decrease exponentially the reward function ambiguity. * Propose a practical way to generate as many ranked demos as desired. ## Additional Assumption Very mild, assumes that a Behavioral Cloning (BC) policy trained on the provided demonstrations is better than a uniform random policy. ## Disturbance-based Reward Extrapolation (D-REX)   They also show that the more noise added to the BC policy the lower the performance of the generated trajs. ## Results Pretty much like T-REX. |

Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
Daniel S. Brown and Wonjoon Goo and Prabhat Nagarajan and Scott Niekum
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/04/12 (5 years ago)
Abstract: A critical flaw of existing inverse reinforcement learning (IRL) methods is their inability to significantly outperform the demonstrator. This is because IRL typically seeks a reward function that makes the demonstrator appear near-optimal, rather than inferring the underlying intentions of the demonstrator that may have been poorly executed in practice. In this paper, we introduce a novel reward-learning-from-observation algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), that extrapolates beyond a set of (approximately) ranked demonstrations in order to infer high-quality reward functions from a set of potentially poor demonstrations. When combined with deep reinforcement learning, T-REX outperforms state-of-the-art imitation learning and IRL methods on multiple Atari and MuJoCo benchmark tasks and achieves performance that is often more than twice the performance of the best demonstration. We also demonstrate that T-REX is robust to ranking noise and can accurately extrapolate intention by simply watching a learner noisily improve at a task over time.
more
less
Daniel S. Brown and Wonjoon Goo and Prabhat Nagarajan and Scott Niekum
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/04/12 (5 years ago)
Abstract: A critical flaw of existing inverse reinforcement learning (IRL) methods is their inability to significantly outperform the demonstrator. This is because IRL typically seeks a reward function that makes the demonstrator appear near-optimal, rather than inferring the underlying intentions of the demonstrator that may have been poorly executed in practice. In this paper, we introduce a novel reward-learning-from-observation algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), that extrapolates beyond a set of (approximately) ranked demonstrations in order to infer high-quality reward functions from a set of potentially poor demonstrations. When combined with deep reinforcement learning, T-REX outperforms state-of-the-art imitation learning and IRL methods on multiple Atari and MuJoCo benchmark tasks and achieves performance that is often more than twice the performance of the best demonstration. We also demonstrate that T-REX is robust to ranking noise and can accurately extrapolate intention by simply watching a learner noisily improve at a task over time.
|
[link]
## General Framework Only access to a finite set of **ranked demonstrations**. The demonstrations only contains **observations** and **do not need to be optimal** but must be (approximately) ranked from worst to best. The **reward learning part is off-line** but not the policy learning part (requires interactions with the environment). In a nutshell: learns a reward models that looks at observations. The reward model is trained to predict if a demonstration's ranking is greater than another one's. Then, once the reward model is learned, one simply uses RL to learn a policy. This latter outperform the demonstrations' performance. ## Motivations Current IRL methods cannot outperform the demonstrations because they seek a reward function that makes the demonstrator optimal and thus do not infer the underlying intentions of the demonstrator that may have been poorly executed. In practice, high quality demonstrations may be difficult to provide and it is often easier to provide demonstrations with a ranking of their relative performance (desirableness). ## Trajectory-ranked Reward EXtrapolation (T-REX)  Uses ranked demonstrations to extrapolate a user's underlying intent beyond the best demonstrations by learning a reward that assigns greater return to higher-ranked trajectories. While standard IRL seeks a reward that **justifies** the demonstrations, T-REX tries learns a reward that **explains** the ranking over demonstrations.  Having rankings over demonstrations may remove the reward ambiguity problem (always 0 reward cannot explain the ranking) as well as provide some "data-augmentation" since from a few ranked demonstrations you can define many pair-wise comparisons. Additionally, suboptimal demonstrations may provide more diverse data by exploring a larger area of the state space (but may miss the parts relevant to solving the task...) ## Tricks and Tips Authors used ground truth reward to rank trajectories, but they also show that approximate ranking does not hurt the performance much. To avoid overfitting they used an ensemble of 5 Neural Networks to predict the reward. For episodic tasks, they compare subtrajectories that correspond to similar timestep (better trajectory is a bit later in the episode than the one it is compared against so that reward increases as the episode progresses). At RL training time, the learned reward goes through a sigmoid to avoid large changes in the reward scale across time-steps. ## Results    Results are quite positive and performance can be good even when the learned reward is not really correlated with the ground truth (cf. HalfCheetah). They also show that T-REX is robust to different ranking-noises: random-swapping of pair-wise ranking, ranking by humans that only have access to a description of the task and not the ground truth reward. **They also automatically rank the demonstrations using the number of learning steps of a learning expert: therefore T-REX could be used as an intrinsic reward alongside the ground-truth to accelerate training.**  **Limitations** They do not show than T-REX can match an optimal expert, maybe ranking demonstrations hurt when all the demos are close to optimality? |
Regularizing Trajectory Optimization with Denoising Autoencoders
Boney, Rinu and Palo, Norman Di and Berglund, Mathias and Ilin, Alexander and Kannala, Juho and Rasmus, Antti and Valpola, Harri
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Boney, Rinu and Palo, Norman Di and Berglund, Mathias and Ilin, Alexander and Kannala, Juho and Rasmus, Antti and Valpola, Harri
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
The typical model based reinforcement learning (RL) loop consists of collecting data, training a model of the environment, using the model to do model predictive control (MPC). If however the model is wrong, for example for state-action pairs that have been barely visited, the dynamics model might be very wrong and the MPC fails as the imagined model and the reality align to longer. Boney et a. propose to tackle this with a denoising autoencoder for trajectory regularization according to the familiarity of a trajectory.
MPC uses at each time t the learned model $s_{t+1} = f_{\theta}(s_t, a_t)$ to select a plan of actions, that is maximizing the sum of expected future reward:
$
G(a_t, \dots, a_{t+h}) = \mathbb{E}[\sum_{k=t}^{t+H}r(o_t, a_t)] ,$
where $r(o_t, a_t)$ is the observation and action dependent reward. The plan obtained by trajectory optimization is subsequently unrolled for H steps.
Boney et al. propose to regularize trajectories by the familiarity of the visited states leading to the regularized objective:
$G_{reg} = G + \alpha \log p(o_k, a_k, \dots, o_{t+H}, a_{t+H})
$
Instead of regularizing over the whole trajectory they propose to regularize over marginal probabilities of windows of length w:
$G_{reg} = G + \alpha \sum_{k = t}^{t+H-w} \log p(x_k), \text{ where } x_k = (o_k, a_k, \dots, o_{t+w}, a_{t+w}).$
Instead of explicitly learning a generative model of the familiarity $p(x_k)$ a denoising auto-encoder is used that approximates instead the derivative of the log probability density $\frac{\delta}{\delta x} \log p(x)$. This allows the following back-propagation rule:
$ \frac{\delta G_{reg}}{\delta_i} = \frac{\delta G}{\delta a_i} + \alpha \sum_{k = i}^{i+w} \frac{\delta x_k}{\delta a_i} \frac{\delta}{\delta x} \log p(x).$
The experiments show that the proposed method has competitive sample-efficiency. For example on Halfcheetah the asymptotic performance of PETS is not matched.
This is due to the biggest limitation of this approach, the hindering of exploration. Penalizing the unfamiliarity of states is in contrast to approaches like optimism in the face of uncertainty, which is a core principle of exploration. Aiming to avoid states of high unfamiliarity, the proposed method is the precise opposite of curiosity driven exploration. The appendix proposes preliminary experiments to account for exploration. I would expect, that the pure penalization of unfamiliarity works best in a batch RL setting, which would be an interesting extension of this work.
|

What Can Learned Intrinsic Rewards Capture?
Zheng, Zeyu and Oh, Junhyuk and Hessel, Matteo and Xu, Zhongwen and Kroiss, Manuel and van Hasselt, Hado and Silver, David and Singh, Satinder
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Zheng, Zeyu and Oh, Junhyuk and Hessel, Matteo and Xu, Zhongwen and Kroiss, Manuel and van Hasselt, Hado and Silver, David and Singh, Satinder
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper out of DeepMind is an interesting synthesis of ideas out of the research areas of meta learning and intrinsic rewards. The hope for intrinsic reward structures in reinforcement learning - things like uncertainty reduction or curiosity - is that they can incentivize behavior like information-gathering and exploration, which aren't incentivized by the explicit reward in the short run, but which can lead to higher total reward in the long run. So far, intrinsic rewards have mostly been hand-designed, based on heuristics or analogies from human intelligence and learning. This paper argues that we should use meta learning to learn a parametrized intrinsic reward function that more directly succeeds our goal of facilitating long run reward. They do this by: - Creating agents that have multiple episodes within a lifetime, and learn a policy network to optimize Eta, a neural network mapping from the agent's life history to scalars, that serves as an intrinsic reward. The learnt policy is carried over from episode to episode. - The meta learner then optimizes the Eta network to achieve higher lifetime reward according to the *true* extrinsic reward, which the agent itself didn't have access to - The learned intrinsic reward function is then passed onto the next "newborn" agent, so that, even though its policy is reinitialized, it has access to past information in the form of the reward function This neatly mimics some of the dynamics of human evolution, where our long term goals of survival and reproduction are distilled into effective short term, intrinsic rewards through chemical signals. The idea is, those chemical signals were evolved over millennia of human evolution to be ones that, if followed locally, would result in the most chance of survival. The authors find that they're able to learn intrinsic rewards that "know" that they agent they're attached to will be dropped in an environment with a goal, but doesn't know the location, and so learns to incentivize searching until a goal is found, and then subsequently moving towards it. This smooth tradeoff between exploration and exploitation is something that can be difficult to balance between intrinsic exploration-focused reward and extrinsic reward. While the idea is an interesting one, an uncertainty I have with the paper is whether it'd be likely to scale beyond the simple environments it was trained on. To really learn a useful reward function in complex environments would require huge numbers of timesteps, and it seems like it'd be difficult to effectively assign credit through long lifetimes of learning, even with the lifetime value function used in the paper to avoid needing to mechanically backpropogate through entire lifetimes. It's also worth saying that the idea seems quite similar to a 2017 paper written by Singh et al; having not read that one in detail, I can't comment on the extent to which this work may just build incrementally on that one. |
Augmenting Genetic Algorithms with Deep Neural Networks for Exploring the Chemical Space
Nigam, AkshatKumar and Friederich, Pascal and Krenn, Mario and Aspuru-Guzik, Alán
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Nigam, AkshatKumar and Friederich, Pascal and Krenn, Mario and Aspuru-Guzik, Alán
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
I found this paper a bit difficult to fully understand. Its premise, as far as I can follow, is that we may want to use genetic algorithms (GA), where we make modifications to elements in a population, and keep elements around at a rate proportional to some set of their desirable properties. In particular we might want to use this approach for constructing molecules that have properties (or predicted properties) we want. However, a downside of GA is that its easy to end up in local minima, where a single molecule, or small modifications to that molecule, end up dominating your population, because everything else gets removed for having less-high reward. The authors proposed fix for this is by training a discriminator to tell the difference between molecules from the GA population and those from a reference dataset, and then using that discriminator loss, GAN-style, as part of the "fitness" term that's used to determine if elements stay in the population. The rest of the "fitness" term is made up of chemical desiderata - solubility, how easy a molecule is to synthesize, binding efficacy, etc. I think the intuition here is that if the GA produces the same molecule (or similar ones) over and over again, the discriminator will have an easy time telling the difference between the GA molecules and the reference ones. One confusion I had with this paper is that it only really seems to have one experiment supporting its idea of using a discriminator as part of the loss - where the discriminator wasn't used at all unless the chemical fitness terms plateaued for some defined period (shown below). https://i.imgur.com/sTO0Asc.png The other constrained optimization experiments in section 4.4 (generating a molecule with specific properties, improving a desired property while staying similar to a reference molecule, and drug discovery). They also specifically say that they'd like to be the case that the beta parameter - which controls the weight of the discriminator relative to the chemical fitness properties - lets you smoothly interpolate between prioritizing properties and prioritizing diversity/realness of images, but they find that's not the case, and that, in fact, there's a point at which you move beta a small amount and switch sharply to a regime where chemical fitness values are a lot lower. Plots of eventual chemical fitness found over time seem to be the highest for models with beta set to 0, which isn't what you'd expect if the discriminator was in fact useful for getting you out of plateaus and into long-term better solutions. Overall, I found this paper an interesting idea, but, especially since it was accepted into ICLR, found it had confusingly little empirical support behind it. |
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
Kumar, Aviral and Fu, Justin and Soh, Matthew and Tucker, George and Levine, Sergey
Neural Information Processing Systems Conference - 2019 via Local Bibsonomy
Keywords: dblp
Kumar, Aviral and Fu, Justin and Soh, Matthew and Tucker, George and Levine, Sergey
Neural Information Processing Systems Conference - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Kumar et al. propose an algorithm to learn in batch reinforcement learning (RL), a setting where an agent learns purely form a fixed batch of data, $B$, without any interactions with the environments. The data in the batch is collected according to a batch policy $\pi_b$. Whereas most previous methods (like BCQ) constrain the learned policy to stay close to the behavior policy, Kumar et al. propose bootstrapping error accumulation reduction (BEAR), which constrains the newly learned policy to place some probability mass on every non negligible action.
The difference is illustrated in the picture from the BEAR blog post:
https://i.imgur.com/zUw7XNt.png
The behavior policy is in both images the dotted red line, the left image shows the policy matching where the algorithm is constrained to the purple choices, while the right image shows the support matching.
**Theoretical Contribution:**
The paper analysis formally how the use of out-of-distribution actions to compute the target in the Bellman equation influences the back-propagated error.
Firstly a distribution constrained backup operator is defined as
$T^{\Pi}Q(s,a) = \mathbb{E}[R(s,a) + \gamma \max_{\pi \in \Pi} \mathbb{E}_{P(s' \vert s,a)} V(s')]$ and $V(s) = \max_{\pi \in \Pi} \mathbb{E}_{\pi}[Q(s,a)]$
which considers only policies $\pi \in \Pi$.
It is possible that the optimal policy $\pi^*$ is not contained in the policy set $\Pi$, thus there is a suboptimallity constant $\alpha (\Pi) = \max_{s,a} \vert \mathcal{T}^{\Pi}Q^{*}(s,a) - \mathcal{T}Q^{*}(s,a) ]\vert $ which captures how far $\pi^{*}$ is from $\Pi$.
Letting $P^{\pi_i}$ be the transition-matrix when following policy $\pi_i$, $\rho_0$ the state marginal distribution of the training data in the batch and $\pi_1, \dots, \pi_k \in \Pi $. The error analysis relies upon a concentrability assumption $\rho_0 P^{\pi_1} \dots P^{\pi_k} \leq c(k)\mu(s)$, with $\mu(s)$ the state marginal. Note that $c(k)$ might be infinite if the support of $\Pi$ is not contained in the state marginal of the batch. Using the coefficients $c(k)$ a concentrability coefficient is defined as:
$C(\Pi) = (1-\gamma)^2\sum_{k=1}^{\infty}k \gamma^{k-1}c(k).$
The concentrability takes values between 1 und $\infty$, where 1 corresponds to the case that the batch data were collected by $\pi$ and $\Pi = \{\pi\}$ and $\infty$ to cases where $\Pi$ has support outside of $\pi$.
Combining this Kumar et a. get a bound of the Bellman error for distribution constrained value iteration with the constrained Bellman operator $T^{\Pi}$:
$\lim_{k \rightarrow \infty} \mathbb{E}_{\rho_0}[\vert V^{\pi_k}(s)- V^{*}(s)] \leq \frac{\gamma}{(1-\gamma^2)} [C(\Pi) \mathbb{E}_{\mu}[\max_{\pi \in \Pi}\mathbb{E}_{\pi}[\delta(s,a)] + \frac{1-\gamma}{\gamma}\alpha(\Pi) ] ]$, where $\delta(s,a)$ is the Bellman error.
This presents the inherent batch RL trade-off between keeping policies close to the behavior policy of the batch (captured by $C(\Pi)$ and keeping $\Pi$ sufficiently large (captured by $\alpha(\Pi)$).
It is finally proposed to use support sets to construct $\Pi$, that is $\Pi_{\epsilon} = \{\pi \vert \pi(a \vert s)=0 \text{ whenever } \beta(a \vert s) < \epsilon \}$. This amounts to the set of all policies that place probability on all non-negligible actions of the behavior policy. For this particular choice of $\Pi = \Pi_{\epsilon}$ the concentrability coefficient can be bounded.
**Algorithm**:
The algorithm has an actor critic style, where the Q-value to update the policy is taken to be the minimum over the ensemble. The support constraint to place at least some probability mass on every non negligible action from the batch is enforced via sampled MMD. The proposed algorithm is a member of the policy regularized algorithms as the policy is updated to optimize:
$\pi_{\Phi} = \max_{\pi} \mathbb{E}_{s \sim B} \mathbb{E}_{a \sim \pi(\cdot \vert s)} [min_{j = 1 \dots, k} Q_j(s,a)] s.t. \mathbb{E}_{s \sim B}[MMD(D(s), \pi(\cdot \vert s))] \leq \epsilon$
The Bellman target to update the Q-functions is computed as the convex combination of minimum and maximum of the ensemble.
**Experiments**
The experiments use the Mujoco environments Halfcheetah, Walker, Hopper and Ant. Three scenarios of batch collection, always consisting of 1Mio. samples, are considered:
- completely random behavior policy
- partially trained behavior policy
- optimal policy as behavior policy
The experiments confirm that BEAR outperforms other off-policy methods like BCQ or KL-control. The ablations show further that the choice of MMD is crucial as it is sometimes on par and sometimes substantially better than choosing KL-divergence.
|
Behavior Regularized Offline Reinforcement Learning
Wu, Yifan and Tucker, George and Nachum, Ofir
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Wu, Yifan and Tucker, George and Nachum, Ofir
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Wu et al. provide a framework (behavior regularized actor critic (BRAC)) which they use to empirically study the impact of different design choices in batch reinforcement learning (RL). Specific instantiations of the framework include BCQ, KL-Control and BEAR.
Pure off-policy rl describes the problem of learning a policy purely from a batch $B$ of one step transitions collected with a behavior policy $\pi_b$. The setting allows for no further interactions with the environment. This learning regime is for example in high stake scenarios, like education or heath care, desirable.
The core principle of batch RL-algorithms in to stay in some sense close to the behavior policy. The paper proposes to incorporate this firstly via a regularization term in the value function, which is denoted as **value penalty**. In this case the value function of BRAC takes the following form:
$
V_D^{\pi}(s) = \sum_{t=0}^{\infty} \gamma ^t \mathbb{E}_{s_t \sim P_t^{\pi}(s)}[R^{pi}(s_t)- \alpha D(\pi(\cdot\vert s_t) \Vert \pi_b(\cdot \vert s_t)))],
$
where $\pi_b$ is the maximum likelihood estimate of the behavior policy based upon $B$.
This results in a Q-function objective:
$\min_{Q} = \mathbb{E}_{\substack{(s,a,r,s') \sim D \\ a' \sim \pi_{\theta}(\cdot \vert s)}}\left[(r + \gamma \left(\bar{Q}(s',a')-\alpha D(\pi(\cdot\vert s) \Vert \pi_b(\cdot \vert s) \right) - Q(s,a) \right]
$
and the corresponding policy update:
$
\max_{\pi_{\theta}} \mathbb{E}_{(s,a,r,s') \sim D} \left[ \mathbb{E}_{a^{''} \sim \pi_{\theta}(\cdot \vert s)}[Q(s,a^{''})] - \alpha D(\pi(\cdot\vert s) \Vert \pi_b(\cdot \vert s) \right]
$
The second approach is **policy regularization** . Here the regularization weight $\alpha$ is set for value-objectives (V- and Q) to zero and is non-zero for the policy objective.
It is possible to instantiate for example the following batch RL algorithms in this setting:
- BEAR: policy regularization with sample-based kernel MMD as D and min-max mixture of the two ensemble elements for $\bar{Q}$
- BCQ: no regularization but policy optimization over restricted space
Extensive Experiments over the four Mujoco tasks Ant, HalfCheetah,Hopper Walker show:
1. for a BEAR like instantiation there is a modest advantage of keeping $\alpha$ fixed
2. using a mixture of a two or four Q-networks ensemble as target value yields better returns that using one Q-network
3. taking the minimum of ensemble Q-functions is slightly better than taking a mixture (for Ant, HalfCeetah & Walker, but not for Hooper
4. the use of value-penalty yields higher return than the policy-penalty
5. no choice for D (MMD, KL (primal), KL(dual) or Wasserstein (dual)) significantly outperforms the other (note that his contradicts the BEAR paper where MMD was better than KL)
6. the value penalty version consistently outperforms BEAR which in turn outperforms BCQ with improves upon a partially trained baseline.
This large scale study of different design choices helps in developing new methods. It is however surprising to see, that most design choices in current methods are shown empirically to be non crucial. This points to the importance of agreeing upon common test scenarios within a community to prevent over-fitting new algorithms to a particular setting.
|
Self-Attention Based Molecule Representation for Predicting Drug-Target Interaction
Shin, Bonggun and Park, Sungsoo and Kang, Keunsoo and Ho, Joyce C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Shin, Bonggun and Park, Sungsoo and Kang, Keunsoo and Ho, Joyce C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In the last three years, Transformers, or models based entirely on attention for aggregating information from across multiple places in a sequence, have taken over the world of NLP. In this paper, the authors propose using a Transformer to learn a molecular representation, and then building a model to predict drug/target interaction on top of that learned representation. A drug/target interaction model takes in two inputs - a protein involved in a disease pathway, and a (typically small) molecule being considered as a candidate drug - and predicts the binding affinity they'll have for one another. If binding takes place between the two, that protein will be prevented from playing its role in the chain of disease progression, and the drug will be effective. The mechanics of the proposed Molecular Transformer DTI (or MT-DTI) model work as follows: https://i.imgur.com/ehfjMK3.png - Molecules are represented as SMILES strings, a character-based representation of atoms and their structural connections. Proteins are represented as sequences of amino acids. - A Transformer network is constructed over the characters in the SMILES string, where, at each level, the representation of each character comes from taking an attention-weighted average of the representations at other positions in the character string at that layer. At the final layer, the aggregated molecular representation is taken from a special "REP" token. - The molecular transformer is pre-trained in BERT-like way: by taking a large corpus (97M molecules) of unsupervised molecular representations, masking or randomizing tokens within the strings, and training the model to predict the true correct token at each point. The hope is that this task will force the representations to encode information relevant to the global structures and chemical constraints of the molecule in question - This pre-trained Transformer is then plugged into the DTI model, alongside a protein representation model in the form of multiple layers convolutions acting on embedded representations of amino acids. The authors noted that they considered a similar pretrained transformer architecture for the protein representation side of the model, but that they chose not to because (1) the calculations involved in attention are N^2 in the length of the sequence, and proteins are meaningfully longer than the small molecules being studied, and (2) there's no comparably large dataset of protein sequences that could be effectively used for pretraining - The protein and molecule representations are combined with multiple dense layers, and then produce a final affinity score. Although the molecular representation model starts with a set of pretrained weights, it also fine tunes on top of them. https://i.imgur.com/qybLKvf.png When evaluated empirically on two DTI datasets, this attention based model outperforms the prior SOTA, using a convolutional architecture, by a small but consistent amount across all metrics. Interestingly, their model is reasonably competitive even if they don't fine-tune the molecular representation for the DTI task, but only pretraining and fine-tuning together get the MT-DTI model over the threshold of prior work. |
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Rakelly, Kate and Zhou, Aurick and Quillen, Deirdre and Finn, Chelsea and Levine, Sergey
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Rakelly, Kate and Zhou, Aurick and Quillen, Deirdre and Finn, Chelsea and Levine, Sergey
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Rakelly et al. propose a method to do off-policy meta reinforcement learning (rl). The method achieves a 20-100x improvement on sample efficiency compared to on-policy meta rl like MAML+TRPO.
The key difficulty for offline meta rl arises from the meta-learning assumption, that meta-training and meta-test time match. However during test time the policy has to explore and sees as such on-policy data which is in contrast to the off-policy data that should be used at meta-training. The key contribution of PEARL is an algorithm that allows for online task inference in a latent variable at train and test time, which is used to train a Soft Actor Critic, a very sample efficient off-policy algorithm, with additional dependence of the latent variable.
The implementation of Rakelly et al. proposes to capture knowledge about the current task in a latent stochastic variable Z. A inference network $q_{\Phi}(z \vert c)$ is used to predict the posterior over latents given context c of the current task in from of transition tuples $(s,a,r,s')$ and trained with an information bottleneck. Note that the task inference is done on samples according to a sampling strategy sampling more recent transitions. The latent z is used as an additional input to policy $\pi(a \vert s, z)$ and Q-function $Q(a,s,z)$ of a soft actor critic algorithm which is trained with offline data of the full replay buffer.
https://i.imgur.com/wzlmlxU.png
So the challenge of differing conditions at test and train times is resolved by sampling the content for the latent context variable at train time only from very recent transitions (which is almost on-policy) and at test time by construction on-policy. Sampling $z \sim q(z \vert c)$ at test time allows for posterior sampling of the latent variable, yielding efficient exploration.
The experiments are performed across 6 Mujoco tasks with ProMP, MAML+TRPO and $RL^2$ with PPO as baselines. They show:
- PEARL is 20-100x more sample-efficient
- the posterior sampling of the latent context variable enables deep exploration that is crucial for sparse reward settings
- the inference network could be also a RNN, however it is crucial to train it with uncorrelated transitions instead of trajectories that have high correlated transitions
- using a deterministic latent variable, i.e. reducing $q_{\Phi}(z \vert c)$ to a point estimate, leaves the algorithm unable to solve sparse reward navigation tasks which is attributed to the lack of temporally extended exploration.
The paper introduces an algorithm that allows to combine meta learning with an off-policy algorithm that dramatically increases the sample-efficiency compared to on-policy meta learning approaches. This increases the chance of seeing meta rl in any sort of real world applications.
|
Meta-Learning via Learned Loss
Sarah Bechtle and Artem Molchanov and Yevgen Chebotar and Edward Grefenstette and Ludovic Righetti and Gaurav Sukhatme and Franziska Meier
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.RO, stat.ML
First published: 2019/06/12 (4 years ago)
Abstract: Typically, loss functions, regularization mechanisms and other important aspects of training parametric models are chosen heuristically from a limited set of options. In this paper, we take the first step towards automating this process, with the view of producing models which train faster and more robustly. Concretely, we present a meta-learning method for learning parametric loss functions that can generalize across different tasks and model architectures. We develop a pipeline for meta-training such loss functions, targeted at maximizing the performance of the model trained under them. The loss landscape produced by our learned losses significantly improves upon the original task-specific losses in both supervised and reinforcement learning tasks. Furthermore, we show that our meta-learning framework is flexible enough to incorporate additional information at meta-train time. This information shapes the learned loss function such that the environment does not need to provide this information during meta-test time.
more
less
Sarah Bechtle and Artem Molchanov and Yevgen Chebotar and Edward Grefenstette and Ludovic Righetti and Gaurav Sukhatme and Franziska Meier
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.RO, stat.ML
First published: 2019/06/12 (4 years ago)
Abstract: Typically, loss functions, regularization mechanisms and other important aspects of training parametric models are chosen heuristically from a limited set of options. In this paper, we take the first step towards automating this process, with the view of producing models which train faster and more robustly. Concretely, we present a meta-learning method for learning parametric loss functions that can generalize across different tasks and model architectures. We develop a pipeline for meta-training such loss functions, targeted at maximizing the performance of the model trained under them. The loss landscape produced by our learned losses significantly improves upon the original task-specific losses in both supervised and reinforcement learning tasks. Furthermore, we show that our meta-learning framework is flexible enough to incorporate additional information at meta-train time. This information shapes the learned loss function such that the environment does not need to provide this information during meta-test time.
|
[link]
Bechtle et al. propose meta learning via learned loss ($ML^3$) and derive and empirically evaluate the framework on classification, regression, model-based and model-free reinforcement learning tasks.
The problem is formalized as learning parameters $\Phi$ of a meta loss function $M_\phi$ that computes loss values $L_{learned} = M_{\Phi}(y, f_{\theta}(x))$. Following the outer-inner loop meta algorithm design the learned loss $L_{learned}$ is used to update the parameters of the learner in the inner loop via gradient descent:
$\theta_{new} = \theta - \alpha \nabla_{\theta}L_{learned} $. The key contribution of the paper is the way to construct a differentiable learning signal for the loss parameters $\Phi$.
The framework requires to specify a task loss $L_T$ during meta train time, which can be for example the mean squared error for regression tasks. After updating the model parameters to $\theta_{new}$ the task loss is used to measure how much learning progress has been made with loss parameters $\Phi$. The key insight is the decomposition via chain-rule of $\nabla_{\Phi} L_T(y, f_{\theta_{new}})$:
$\nabla_{\Phi} L_T(y, f_{\theta_{new}}) = \nabla_f L_t \nabla_{\theta_{new}}f_{\theta_{new}} \nabla_{\Phi} \theta_{new} = \nabla_f L_t \nabla_{\theta_{new}}f_{\theta_{new}} [\theta - \alpha \nabla_{\theta} \mathbb{E}[M_{\Phi}(y, f_{\theta}(x))]]$.
This allows to update the loss parameters with gradient descent as: $\Phi_{new} = \Phi - \eta \nabla_{\Phi} L_T(y, f_{\theta_{new}})$.
This update rules yield the following $ML^3$ algorithm for supervised learning tasks:
https://i.imgur.com/tSaTbg8.png
For reinforcement learning the task loss is the expected future reward of policies induced by the policy $\pi_{\theta}$, for model-based rl with respect to the approximate dynamics model and for the model free case a system independent surrogate: $L_T(\pi_{\theta_{new}}) = -\mathbb{E}_{\pi_{\theta_{new}}} \left[ R(\tau_{\theta_{new}}) \log \pi_{\theta_{new}}(\tau_{new})\right] $.
The allows further to incorporate extra information via an additional loss term $L_{extra}$ and to consider the augmented task loss $\beta L_T + \gamma L_{extra} $, with weights $\beta, \gamma$ at train time. Possible extra loss terms are used to add physics priors, encouragement of exploratory behavior or to incorporate expert demonstrations. The experiments show that this, at test time unavailable information, is retained in the shape of the loss landscape.
The paper is packed with insightful experiments and shows that the learned loss function:
- yields in regression and classification better accuracies at train and test tasks
- generalizes well and speeds up learning in model based rl tasks
- yields better generalization and faster learning in model free rl
- is agnostic across a bunch of evaluated architectures (2,3,4,5 layers)
- with incorporated extra knowledge yields better performance than without and is superior to alternative approaches like iLQR in a MountainCar task.
The paper introduces a promising alternative, by learning the loss parameters, to MAML like approaches that learn the model parameters. It would be interesting to see if the learned loss function generalizes better than learned model parameters to a broader distribution of tasks like the meta-world tasks.
|
Once for All: Train One Network and Specialize it for Efficient Deployment
Cai, Han and Gan, Chuang and Han, Song
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Cai, Han and Gan, Chuang and Han, Song
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
**Summary**: The goal of this work is to propose a "Once-for-all” (OFA) network: a large network which is trained such that its subnetworks (subsets of the network with smaller width, convolutional kernel sizes, shallower units) are also trained towards the target task. This allows to adapt the architecture to a given budget at inference time while preserving performance. **Elastic Parameters.** The goal is to train a large architecture that contains several well-trained subnetworks with different architecture configurations (in terms of depth, width, kernel size, and resolution). One of the key difficulties is to ensure that each subnetwork reaches high-accuracy even though it is not trained independently but as part of a larger architecture. This work considers standard CNN architectures (decreasing spatial resolution and increasing number of feature maps), which can be decomposed into units (A unit is a block of layers such that the first layer has stride 2, and the remaining ones have stride 1). The parameters of these units (depth, kernel size, input resolution, width) are denoted as *elastic parameters* in the sense that they can take different values, which defines different subnetworks, which still share the convolutional parameters. **Progressive Shrinking.** Additionally, the authors consider a curriculum-style training process which they call *progressive shrinking*. First, they train the model with the maximum depth, $D$, kernel size, $K$, and width, $W$, which yields convolutional parameters . Then they progressively fine-tune this weight, with an additional distillation term from the largest network, while considering different values for the elastic parameters, in the following order: * Elastic kernel size: Training for a kernel size $k < K$ is done by taking a linear transformation the center $k \times k$ patch in the full $K \times K$ kernels that are in . The linear transformation is useful to model the fact that different scales might be useful for different tasks. * Elastic depth: To train for depth $d < D$, simply skip the last $D-d$ layers of the unit (rather than looking at every subset of dlayers) * Elastic width: For a width $w < W$. First, the channels are reorganized by importance (decreasing order of the $L1$-norm of their weights), then use only the top wchannels * Elastic resolution: Simply train with different image resolutions / resizing: This is actually used for all training processes. **Experiments.** Having trained the Once-for-all (OFA) network, the goal is now to find the adequate architecture configuration, given a specific task/budget constraints. To do this automatically, they propose to train a small performance predictive model. They randomly sample 16K subnetworks from OFA, evaluate their accuracy on a validation set, and learn to predict accuracy based on architecture and input image resolution. (Note: It seems that this predictor is then used to perform a cheap evolutionary search, given latency constraints, to find the best architecture config but the whole process is not entirely clear to me. Compared to a proper neural architecture search, however it should be inexpensive). The main experiments are on ImageNet, using MobileNetv3 as the base full architecture, with the goal of applying the model across different platforms with different inference budget constraints. Overall, the proposed model achieves comparable or higher accuracies for reduced search time, compared to neural architecture search baselines. More precisely their model has a fixed training cost (the OFA network) and a small search cost (find best config based on target latency), which is still lower than doing exhaustive neural architecture search. Furthermore, progressive shrinking does have a significant positive impact on the subnetworks accuracy (+4%). |

Combining docking pose rank and structure with deep learning improves protein-ligand binding mode prediction
Joseph A. Morrone and Jeffrey K. Weber and Tien Huynh and Heng Luo and Wendy D. Cornell
arXiv e-Print archive - 2019 via Local arXiv
Keywords: q-bio.BM, physics.bio-ph, stat.ML
First published: 2019/10/07 (4 years ago)
Abstract: We present a simple, modular graph-based convolutional neural network that takes structural information from protein-ligand complexes as input to generate models for activity and binding mode prediction. Complex structures are generated by a standard docking procedure and fed into a dual-graph architecture that includes separate sub-networks for the ligand bonded topology and the ligand-protein contact map. This network division allows contributions from ligand identity to be distinguished from effects of protein-ligand interactions on classification. We show, in agreement with recent literature, that dataset bias drives many of the promising results on virtual screening that have previously been reported. However, we also show that our neural network is capable of learning from protein structural information when, as in the case of binding mode prediction, an unbiased dataset is constructed. We develop a deep learning model for binding mode prediction that uses docking ranking as input in combination with docking structures. This strategy mirrors past consensus models and outperforms the baseline docking program in a variety of tests, including on cross-docking datasets that mimic real-world docking use cases. Furthermore, the magnitudes of network predictions serve as reliable measures of model confidence
more
less
Joseph A. Morrone and Jeffrey K. Weber and Tien Huynh and Heng Luo and Wendy D. Cornell
arXiv e-Print archive - 2019 via Local arXiv
Keywords: q-bio.BM, physics.bio-ph, stat.ML
First published: 2019/10/07 (4 years ago)
Abstract: We present a simple, modular graph-based convolutional neural network that takes structural information from protein-ligand complexes as input to generate models for activity and binding mode prediction. Complex structures are generated by a standard docking procedure and fed into a dual-graph architecture that includes separate sub-networks for the ligand bonded topology and the ligand-protein contact map. This network division allows contributions from ligand identity to be distinguished from effects of protein-ligand interactions on classification. We show, in agreement with recent literature, that dataset bias drives many of the promising results on virtual screening that have previously been reported. However, we also show that our neural network is capable of learning from protein structural information when, as in the case of binding mode prediction, an unbiased dataset is constructed. We develop a deep learning model for binding mode prediction that uses docking ranking as input in combination with docking structures. This strategy mirrors past consensus models and outperforms the baseline docking program in a variety of tests, including on cross-docking datasets that mimic real-world docking use cases. Furthermore, the magnitudes of network predictions serve as reliable measures of model confidence
|
[link]
This paper focuses on the application of deep learning to the docking problem within rational drug design. The overall objective of drug design or discovery is to build predictive models of how well a candidate compound (or "ligand") will bind with a target protein, to help inform the decision of what compounds are promising enough to be worth testing in a wet lab. Protein binding prediction is important because many small-molecule drugs, which are designed to be small enough to get through cell membranes, act by binding to a specific protein within a disease pathway, and thus blocking that protein's mechanism. The formulation of the docking problem, as best I understand it, is: 1. A "docking program," which is generally some model based on physical and chemical interactions, takes in a (ligand, target protein) pair, searches over a space of ways the ligand could orient itself within the binding pocket of the protein (which way is it facing, where is it twisted, where does it interact with the protein, etc), and ranks them according to plausibility 2. A scoring function takes in the binding poses (otherwise known as binding modes) ranked the highest, and tries to predict the affinity strength of the resulting bond, or the binary of whether a bond is "active". The goal of this paper was to interpose modern machine learning into the second step, as alternative scoring functions to be applied after the pose generation . Given the complex data structure that is a highly-ranked binding pose, the hope was that deep learning would facilitate learning from such a complicated raw data structure, rather than requiring hand-summarized features. They also tested a similar model structure on the problem of predicting whether a highly ranked binding pose was actually the empirically correct one, as determined by some epsilon ball around the spatial coordinates of the true binding pose. Both of these were binary tasks, which I understand to be 1. Does this ranked binding pose in this protein have sufficiently high binding affinity to be "active"? This is known as the "virtual screening" task, because it's the relevant task if you want to screen compounds in silico, or virtually, before doing wet lab testing. 2. Is this ranked binding pose the one that would actually be empirically observed? This is known as the "binding mode prediction" task The goal of this second task was to better understand biases the researchers suspected existed in the underlying dataset, which I'll explain later in this post. The researchers used a graph convolution architecture. At a (very) high level, graph convolution works in a way similar to normal convolution - in that it captures hierarchies of local patterns, in ways that gradually expand to have visibility over larger areas of the input data. The distinction is that normal convolution defines kernels over a fixed set of nearby spatial coordinates, in a context where direction (the pixel on top vs the pixel on bottom, etc) is meaningful, because photos have meaningful direction and orientation. By contrast, in a graph, there is no "up" or "down", and a given node doesn't have a fixed number of neighbors (whereas a fixed pixel in 2D space does), so neighbor-summarization kernels have to be defined in ways that allow you to aggregate information from 1) an arbitrary number of neighbors, in 2) a manner that is agnostic to orientation. Graph convolutions are useful in this problem because both the summary of the ligand itself, and the summary of the interaction of the posed ligand with the protein, can be summarized in terms of graphs of chemical bonds or interaction sites. Using this as an architectural foundation, the authors test both solo versions and ensembles of networks: https://i.imgur.com/Oc2LACW.png 1. "L" - A network that uses graph convolution to summarize the ligand itself, with no reference to the protein it's being tested for binding affinity with 2. "LP" - A network that uses graph convolution on the interaction points between the ligand and protein under the binding pose currently being scored or predicted 3. "R" - A simple network that takes into account the rank assigned to the binding pose by the original docking program (generally used in combination with one of the above). The authors came to a few interesting findings by trying different combinations of the above model modules. First, they found evidence supporting an earlier claim that, in the dataset being used for training, there was a bias in the positive and negative samples chosen such that you could predict activity of a ligand/protein binding using *ligand information alone.* This shouldn't be possible if we were sampling in an unbiased way over possible ligand/protein pairs, since even ligands that are quite effective with one protein will fail to bind with another, and it shouldn't be informationally possible to distinguish the two cases without protein information. Furthermore, a random forest on hand-designed features was able to perform comparably to deep learning, suggesting that only simple features are necessary to perform the task on this (bias and thus over-simplified) Specifically, they found that L+LP models did no better than models of L alone on the virtual screening task. However, the binding mode prediction task offered an interesting contrast, in that, on this task, it's impossible to predict the output from ligand information alone, because by construction each ligand will have some set of binding modes that are not the empirically correct one, and one that is, and you can't distinguish between these based on ligand information alone, without looking at the actual protein relationship under consideration. In this case, the LP network did quite well, suggesting that deep learning is able to learn from ligand-protein interactions when it's incentivized to do so. Interestingly, the authors were only able to improve on the baseline model by incorporating the rank output by the original docking program, which you can think of an ensemble of sorts between the docking program and the machine learning model. Overall, the authors' takeaways from this paper were that (1) we need to be more careful about constructing datasets, so as to not leak information through biases, and (2) that graph convolutional models are able to perform well, but (3) seem to be capturing different things than physics-based models, since ensembling the two together provides marginal value. |
Benchmarking Batch Deep Reinforcement Learning Algorithms
Scott Fujimoto and Edoardo Conti and Mohammad Ghavamzadeh and Joelle Pineau
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2019/10/03 (4 years ago)
Abstract: Widely-used deep reinforcement learning algorithms have been shown to fail in the batch setting--learning from a fixed data set without interaction with the environment. Following this result, there have been several papers showing reasonable performances under a variety of environments and batch settings. In this paper, we benchmark the performance of recent off-policy and batch reinforcement learning algorithms under unified settings on the Atari domain, with data generated by a single partially-trained behavioral policy. We find that under these conditions, many of these algorithms underperform DQN trained online with the same amount of data, as well as the partially-trained behavioral policy. To introduce a strong baseline, we adapt the Batch-Constrained Q-learning algorithm to a discrete-action setting, and show it outperforms all existing algorithms at this task.
more
less
Scott Fujimoto and Edoardo Conti and Mohammad Ghavamzadeh and Joelle Pineau
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2019/10/03 (4 years ago)
Abstract: Widely-used deep reinforcement learning algorithms have been shown to fail in the batch setting--learning from a fixed data set without interaction with the environment. Following this result, there have been several papers showing reasonable performances under a variety of environments and batch settings. In this paper, we benchmark the performance of recent off-policy and batch reinforcement learning algorithms under unified settings on the Atari domain, with data generated by a single partially-trained behavioral policy. We find that under these conditions, many of these algorithms underperform DQN trained online with the same amount of data, as well as the partially-trained behavioral policy. To introduce a strong baseline, we adapt the Batch-Constrained Q-learning algorithm to a discrete-action setting, and show it outperforms all existing algorithms at this task.
|
[link]
The authors propose a unified setting to evaluate the performance of batch reinforcement learning algorithms. The proposed benchmark is discrete and based on the popular Atari Domain. The authors review and benchmark several current batch RL algorithms against a newly introduced version of BCQ (Batch Constrained Deep Q Learning) for discrete environments.
https://i.imgur.com/zrCZ173.png
Note in line 5 that the policy chooses actions with a restricted argmax operation, eliminating actions that have not enough support in the batch.
One of the key difficulties in batch-RL is the divergence of value estimates. In this paper the authors use Double DQN, which means actions are selected with a value net $Q_{\theta}$ and the policy evaluation is done with a target network $Q_{\theta'}$ (line 6).
**How is the batch created?**
A partially trained DQN-agent (trained online for 10mio steps, aka 40mio frames) is used as behavioral policy to collect a batch $B$ containing 10mio transitions. The DQN agent uses either with probability 0.8 an $\epsilon=0.2$ and with probability 0.2 an $\epsilon = 0.001$. The batch RL agents are trained on this batch for 10mio steps and evaluated every 50k time steps for 10 episodes. This process of batch creation differs from the settings used in other papers in i) having only a single behavioral policy, ii) the batch size and iii) the proficiency level of the batch policy.
The experiments, performed on the arcade learning environment include DQN, REM, QR-DQN, KL-Control, BCQ, OnlineDQN and Behavioral Cloning and show that:
- for conventional RL algorithms distributional algorithms (QR-DQN) outperform the plain algorithms (DQN)
- batch RL algorithms perform better than conventional algorithms with BCQ outperforming every other algorithm in every tested game
In addition to the return the authors plot the value estimates for the Q-networks. A drop in performance corresponds in all cases to a divergence (up or down) in value estimates.
The paper is an important contribution to the debate about what is the right setting to evaluate batch RL algorithms. It remains however to be seen if the proposed choice of i) a single behavior policy, ii) the batch size and iii) quality level of the behavior policy will be accepted as standard. Further work is in any case required to decide upon a benchmark for continuous domains.
|
Off-Policy Deep Reinforcement Learning without Exploration
Fujimoto, Scott and Meger, David and Precup, Doina
International Conference on Machine Learning - 2019 via Local Bibsonomy
Keywords: dblp
Fujimoto, Scott and Meger, David and Precup, Doina
International Conference on Machine Learning - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Interacting with the environment comes sometimes at a high cost, for example in high stake scenarios like health care or teaching. Thus instead of learning online, we might want to learn from a fixed buffer $B$ of transitions, which is filled in advance from a behavior policy.
The authors show that several so called off-policy algorithms, like DQN and DDPG fail dramatically in this pure off-policy setting.
They attribute this to the extrapolation error, which occurs in the update of a value estimate $Q(s,a)$, where the target policy selects an unfamiliar action $\pi(s')$ such that $(s', \pi(s'))$ is unlikely or not present in $B$. Extrapolation error is caused by the mismatch between the true state-action visitation distribution of the current policy and the state-action distribution in $B$ due to:
- state-action pairs (s,a) missing in $B$, resulting in arbitrarily bad estimates of $Q_{\theta}(s, a)$ without sufficient data close to (s,a).
- the finiteness of the batch of transition tuples $B$, leading to a biased estimate of the transition dynamics in the Bellman operator $T^{\pi}Q(s,a) \approx \mathbb{E}_{\boldsymbol{s' \sim B}}\left[r + \gamma Q(s', \pi(s')) \right]$
- transitions are sampled uniformly from $B$, resulting in a loss weighted w.r.t the frequency of data in the batch: $\frac{1}{\vert B \vert} \sum_{\boldsymbol{(s, a, r, s') \sim B}} \Vert r + \gamma Q(s', \pi(s')) - Q(s, a)\Vert^2$
The proposed algorithm Batch-Constrained deep Q-learning (BCQ) aims to choose actions that:
1. minimize distance of taken actions to actions in the batch
2. lead to states contained in the buffer
3. maximizes the value function,
where 1. is prioritized over the other two goals to mitigate the extrapolation error.
Their proposed algorithm (for continuous environments) consists informally of the following steps that are repeated at each time $t$:
1. update generator model of the state conditional marginal likelihood $P_B^G(a \vert s)$
2. sample n actions form the generator model
3. perturb each of the sampled actions to lie in a range $\left[-\Phi, \Phi \right]$
4. act according to the argmax of respective Q-values of perturbed actions
5. update value function
The experiments considers Mujoco tasks with four scenarios of batch data creation:
- 1 million time steps from training a DDPG agent with exploration noise $\mathcal{N}(0,0.5)$ added to the action.This aims for a diverse set of states and actions.
- 1 million time steps from training a DDPG agent with an exploration noise $\mathcal{N}(0,0.1)$ added to the actions as behavior policy. The batch-RL agent and the behavior DDPG are trained concurrently from the same buffer.
- 1 million transitions from rolling out a already trained DDPG agent
- 100k transitions from a behavior policy that acts with probability 0.3 randomly and follows otherwise an expert demonstration with added exploration noise $\mathcal{N}(0,0.3)$
I like the fourth choice of behavior policy the most as this captures high stake scenarios like education or medicine the closest, in which training data would be acquired by human experts that are by the nature of humans not optimal but significantly better than learning from scratch.
The proposed BCQ algorithm is the only algorithm that is successful across all experiments. It matches or outperforms the behavior policy. Evaluation of the value estimates showcases unstable and diverging value estimates for all algorithms but BCQ that exhibits a stable value function.
The paper outlines a very important issue that needs to be tackled in order to use reinforcement learning in real world applications.
|
Limitations of the Empirical Fisher Approximation for Natural Gradient Descent
Frederik Kunstner and Lukas Balles and Philipp Hennig
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/05/29 (4 years ago)
Abstract: Natural gradient descent, which preconditions a gradient descent update with the Fisher information matrix of the underlying statistical model, is a way to capture partial second-order information. Several highly visible works have advocated an approximation known as the empirical Fisher, drawing connections between approximate second-order methods and heuristics like Adam. We dispute this argument by showing that the empirical Fisher---unlike the Fisher---does not generally capture second-order information. We further argue that the conditions under which the empirical Fisher approaches the Fisher (and the Hessian) are unlikely to be met in practice, and that, even on simple optimization problems, the pathologies of the empirical Fisher can have undesirable effects.
more
less
Frederik Kunstner and Lukas Balles and Philipp Hennig
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/05/29 (4 years ago)
Abstract: Natural gradient descent, which preconditions a gradient descent update with the Fisher information matrix of the underlying statistical model, is a way to capture partial second-order information. Several highly visible works have advocated an approximation known as the empirical Fisher, drawing connections between approximate second-order methods and heuristics like Adam. We dispute this argument by showing that the empirical Fisher---unlike the Fisher---does not generally capture second-order information. We further argue that the conditions under which the empirical Fisher approaches the Fisher (and the Hessian) are unlikely to be met in practice, and that, even on simple optimization problems, the pathologies of the empirical Fisher can have undesirable effects.
|
[link]
The authors analyse in the very well written paper the relation between Fisher $F(\theta) = \sum_n \mathbb{E}_{p_{\theta}(y \vert x)}[\nabla_{\theta} \log(p_{\theta}(y \vert x_n))\nabla_{\theta} \log(p_{\theta}(y \vert x_n))^T] $ and empirical Fisher $\bar{F}(\theta) = \sum_n [\nabla_{\theta} \log(p_{\theta}(y_n \vert x_n))\nabla_{\theta} \log(p_{\theta}(y_n \vert x_n))^T] $, which has recently seen a surge in interest. . The definitions differ in that $y_n$ is a training label instead of a sample of the model $p_{\theta}(y \vert x_n)$, thus even so the name suggests otherwise $\bar{F}$ is not a empirical, for example Monte Carlo, estimate of the Fisher. The authors rebuff common arguments used to justify the use of the empirical fisher by an amendment to the generalized Gauss-Newton, give conditions when the empirical Fisher does indeed approach the Fisher and give an argument why the empirical fisher might work in practice nonetheless.
The Fisher, capturing the curvature of the parameter space, provides information about the geometry of the parameters pace, the empirical Fisher might however fail so capture the curvature as the striking plot from the paper shows:
https://i.imgur.com/c5iCqXW.png
The authors rebuff the two major justifications for the use of empirical Fisher:
1. "the empirical Fisher matches the construction of a generalized Gauss-Newton"
* for the log-likelihood $log(p(y \vert f) = \log \exp(-\frac{1}{2}(y-f)^2))$ the generalized Gauss-Newton intuition that small residuals $f(x_n, \theta) - y_n$ lead to a good approximation of the Hessian is not satisfied. Whereas the Fisher approaches the Hessian, the empirical Fisher approaches 0
2. "the empirical Fisher converges to the true Fisher when the model is a good fit for the data"
* the authors sharpen the argument to "the empirical Fisher converges at the minimum to the Fisher as the number of samples grows", which is unlikely to be satisfied in practice.
The authors provide an alternative perspective on why the empirical Fisher might be successful, namely to adapt the gradient to the gradient noise in stochastic optimization. The empirical Fisher coincides with the second moment of the stochastic gradient estimate and encodes as such covariance information about the gradient noise. This allows to reduce the effects of gradient noise by scaling back the updates in high variance aka noise directions.
|
Adversarial camera stickers: A physical camera-based attack on deep learning systems
Li, Juncheng and Schmidt, Frank R. and Kolter, J. Zico
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Li, Juncheng and Schmidt, Frank R. and Kolter, J. Zico
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Li et al. propose camera stickers that when computed adversarially and physically attached to the camera leads to mis-classification. As illustrated in Figure 1, these stickers are realized using circular patches of uniform color. These individual circular stickers are computed in a gradient-descent fashion by optimizing their location, color and radius. The influence of the camera on these stickers is modeled realistically in order to guarantee success. https://i.imgur.com/xHrqCNy.jpg Figure 1: Illustration of adversarial stickers on the camera (left) and the effect on the taken photo (right). Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |

Provably Robust Deep Learning via Adversarially Trained Smoothed Classifiers
Salman, Hadi and Li, Jerry and Razenshteyn, Ilya P. and Zhang, Pengchuan and Zhang, Huan and Bubeck, Sébastien and Yang, Greg
Neural Information Processing Systems Conference - 2019 via Local Bibsonomy
Keywords: dblp
Salman, Hadi and Li, Jerry and Razenshteyn, Ilya P. and Zhang, Pengchuan and Zhang, Huan and Bubeck, Sébastien and Yang, Greg
Neural Information Processing Systems Conference - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Salman et al. combined randomized smoothing with adversarial training based on an attack specifically designed against smoothed classifiers. Specifically, they consider the formulation of randomized smoothing by Cohen et al. [1]; here, Gaussian noise around the input (adversarial or clean) is sampled and the classifier takes a simple majority vote. In [1], Cohen et al. show that this results in good bounds on robustness. In this paper, Salman et al. propose an adaptive attack against randomized smoothing. Essentially, they use a simple PGD attack to attack a smoothed classifier, i.e., maximize the cross entropy loss of the smoothed classifier. To make the objective tractable, Monte Carlo samples are used in each iteration of the PGD optimization. Based on this attack, they do adversarial training, with adversarial examples computed against the smoothed (and adversarially trained) classifier. In experiments, this approach outperforms the certified robustness by Cohen et al. on several datasets. [1] Jeremy M. Cohen, Elan Rosenfeld and J. Zico Kolter. Certified Adversarial Robustness via Randomized Smoothing. ArXiv, 1902.02918, 2019. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Exploring the Hyperparameter Landscape of Adversarial Robustness
Duesterwald, Evelyn and Murthi, Anupama and Venkataraman, Ganesh and Sinn, Mathieu and Vijaykeerthy, Deepak
- 2019 via Local Bibsonomy
Keywords: adversarial, robustness
Duesterwald, Evelyn and Murthi, Anupama and Venkataraman, Ganesh and Sinn, Mathieu and Vijaykeerthy, Deepak
- 2019 via Local Bibsonomy
Keywords: adversarial, robustness
|
[link]
Duesterwald et al. study the influence of hyperparameters on adversarial training and its robustness as well as accuracy. As shown in Figure 1, the chosen parameters, the ratio of adversarial examples per batch and the allowed perturbation $\epsilon$, allow to control the trade-off between adversarial robustness and accuracy. Even for larger $\epsilon$, at least on MNIST and SVHN, using only few adversarial examples per batch increases robustness significantly while only incurring a small loss in accuracy. https://i.imgur.com/nMZNpFB.jpg Figure 1: Robustness (red) and accuracy (blue) depending on the two hyperparameters $\epsilon$ and ratio of adversarial examples per batch. Robustness is measured in adversarial accuracy. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
CapsAttacks: Robust and Imperceptible Adversarial Attacks on Capsule Networks
Marchisio, Alberto and Nanfa, Giorgio and Khalid, Faiq and Hanif, Muhammad Abdullah and Martina, Maurizio and Shafique, Muhammad
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Marchisio, Alberto and Nanfa, Giorgio and Khalid, Faiq and Hanif, Muhammad Abdullah and Martina, Maurizio and Shafique, Muhammad
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Marchisio et al. propose a black-box adversarial attack on Capsule Networks. The main idea of the attack is to select pixels based on their local standard deviation. Given a window of allowed pixels to be manipulated, these are sorted based on standard deviation and possible impact on the predicted probability (i.e., gap between target class probability and maximum other class probability). A subset of these pixels is then manipulated by a fixed noise value $\delta$. In experiments, the attack is shown to be effective for CapsuleNetworks and other networks. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Efficient Evaluation-Time Uncertainty Estimation by Improved Distillation
Englesson, Erik and Azizpour, Hossein
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Englesson, Erik and Azizpour, Hossein
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Englesson and Azizpour propose an adapted knowledge distillation version to improve confidence calibration on out-of-distribution examples including adversarial examples. In contrast to vanilla distillation, they make the following changes: First, high capacity student networks are used, for example, by increasing depth or with. Then, the target distribution is “sharpened” using the true label by reducing the distributions overall entropy. Finally, for wrong predictions of the teacher model, they propose an alternative distribution with maximum mass on the correct class, while not losing the information provided on the incorrect label. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
On Norm-Agnostic Robustness of Adversarial Training
Li, Bai and Chen, Changyou and Wang, Wenlin and Carin, Lawrence
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Li, Bai and Chen, Changyou and Wang, Wenlin and Carin, Lawrence
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Li et al. evaluate adversarial training using both $L_2$ and $L_\infty$ attacks and proposes a second-order attack. The main motivation of the paper is to show that adversarial training cannot increase robustness against both $L_2$ and $L_\infty$ attacks. To this end, they propose a second-order adversarial attack and experimentally show that ensemble adversarial training can partly solve the problem. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Improving Robustness Without Sacrificing Accuracy with Patch Gaussian Augmentation
Lopes, Raphael Gontijo and Yin, Dong and Poole, Ben and Gilmer, Justin and Cubuk, Ekin D.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Lopes, Raphael Gontijo and Yin, Dong and Poole, Ben and Gilmer, Justin and Cubuk, Ekin D.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Lopes et al. propose patch-based Gaussian data augmentation to improve accuracy and robustness against common corruptions. Their approach is intended to be an interpolation between Gaussian noise data augmentation and CutOut. During training, random patches on images are selected and random Gaussian noise is added to these patches. With increasing noise level (i.e., its standard deviation) this results in CutOut; with increasing patch size, this results in regular Gaussian noise data augmentation. On ImageNet-C and Cifar-C, the authors show that this approach improves robustness against common corruptions while also improving accuracy slightly. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
MNIST-C: A Robustness Benchmark for Computer Vision
Mu, Norman and Gilmer, Justin
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Mu, Norman and Gilmer, Justin
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Mu and Gilmer introduce MNIST-C, an MNIST-based corruption benchmark for out-of-distribution evaluation. The benchmark includes various corruption types including random noise (shot and impulse noise), blur (glass and motion blur), (affine) transformations, “striping” or occluding parts of the image, using Canny images or simulating fog. These corruptions are also shown in Figure 1. The transformations have been chosen to be semantically invariant, meaning that the true class of the image does not change. This is important for evaluation as model’s can easily be tested whether they still predict the correct labels on the corrupted images. https://i.imgur.com/Y6LgAM4.jpg Figure 1: Examples of the used corruption types included in MNIST-C. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
A Research Agenda: Dynamic Models to Defend Against Correlated Attacks
Goodfellow, Ian J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Goodfellow, Ian J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Goodfellow motivates the use of dynamical models as “defense” against adversarial attacks that violate both the identical and independent assumptions in machine learning. Specifically, he argues that machine learning is mostly based on the assumption that the data is samples identically and independently from a data distribution. Evasion attacks, meaning adversarial examples, mainly violate the assumption that they come from the same distribution. Adversarial examples computed within an $\epsilon$-ball around test examples basically correspond to an adversarial distribution the is larger (but entails) the original data distribution. In this article, Goodfellow argues that we should also consider attacks violating the independence assumption. This means, as a simple example, that the attacker can also use the same attack over and over again. This yields the idea of correlated attacks as mentioned in the paper’s title. Against this more general threat model, Goodfellow argues that dynamic models are required; meaning the model needs to change (or evolve) – be a moving target that is harder to attack. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Examples Are a Natural Consequence of Test Error in Noise
Ford, Nic and Gilmer, Justin and Carlini, Nicholas and Cubuk, Ekin Dogus
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ford, Nic and Gilmer, Justin and Carlini, Nicholas and Cubuk, Ekin Dogus
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Ford et al. show that the existence of adversarial examples can directly linked to test error on noise and other types of random corruption. Additionally, obtaining model robust against random corruptions is difficult, and even adversarially robust models might not be entirely robust against these corruptions. Furthermore, many “defenses” against adversarial examples show poor performance on random corruption – showing that some defenses do not result in robust models, but make attacking the model using gradient-based attacks more difficult (gradient masking). Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarially Robust Distillation
Goldblum, Micah and Fowl, Liam and Feizi, Soheil and Goldstein, Tom
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Goldblum, Micah and Fowl, Liam and Feizi, Soheil and Goldstein, Tom
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Goldblum et al. show that distilling robustness is possible, however, depends on the teacher model and the considered dataset. Specifically, while classical knowledge distillation does not convey robustness against adversarial examples, distillation with a robust teacher model might increase robustness of the student model – even if trained on clean examples only. However, this seems to depend on both the dataset as well as the teacher model, as pointed out in experiments on Cifar100. Unfortunately, from the paper, it does not become clear in which cases robustness distillation does not work. To overcome this limitation, the authors propose to combine adversarial training and distillation and show that this recovers robustness; the student model’s robustness might even exceed the teacher model’s robustness. This, however, might be due to the additional adversarial examples used during distillation. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
When to use parametric models in reinforcement learning?
van Hasselt, Hado and Hessel, Matteo and Aslanides, John
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
van Hasselt, Hado and Hessel, Matteo and Aslanides, John
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper is a bit provocative (especially in the light of the recent DeepMind MuZero paper), and poses some interesting questions about the value of model-based planning. I'm not sure I agree with the overall argument it's making, but I think the experience of reading it made me hone my intuitions around why and when model-based planning should be useful. The overall argument of the paper is: rather than learning a dynamics model of the environment and then using that model to plan and learn a value/policy function from, we could instead just keep a large replay buffer of actual past transitions, and use that in lieu of model-sampled transitions to further update our reward estimators without having to acquire more actual experience. In this paper's framing, the central value of having a learned model is this ability to update our policy without needing more actual experience, and it argues that actual real transitions from the environment are more reliable and less likely to diverge than transitions from a learned parametric model. It basically sees a big buffer of transitions as an empirical environment model that it can sample from, in a roughly equivalent way to being able to sample transitions from a learnt model. An obvious counter-argument to this is the value of models in being able to simulate particular arbitrary trajectories (for example, potential actions you could take from your current point, as is needed for Monte Carlo Tree Search). Simply keeping around a big stock of historical transitions doesn't serve the use case of being able to get a probable next state *for a particular transition*, both because we might not have that state in our data, and because we don't have any way, just given a replay buffer, of knowing that an available state comes after an action if we haven't seen that exact combination before. (And, even if we had, we'd have to have some indexing/lookup mechanism atop the data). I didn't feel like the paper's response to this was all that convincing. It basically just argues that planning with model transitions can theoretically diverge (though acknowledges it empirically often doesn't), and that it's dangerous to update off of "fictional" modeled transitions that aren't grounded in real data. While it's obviously definitionally true that model transitions are in some sense fictional, that's just the basic trade-off of how modeling works: some ability to extrapolate, but a realization that there's a risk you extrapolate poorly. https://i.imgur.com/8jp22M3.png The paper's empirical contribution to its argument was to argue that in a low-data setting, model-free RL (in the form of the "everything but the kitchen sink" Rainbow RL algorithm) with experience replay can outperform a model-based SimPLe system on Atari. This strikes me as fairly weak support for the paper's overall claim, especially since historically Atari has been difficult to learn good models of when they're learnt in actual-observation pixel space. Nonetheless, I think this push against the utility of model-based learning is a useful thing to consider if you do think models are useful, because it will help clarify the reasons why you think that's the case. |
Are Disentangled Representations Helpful for Abstract Visual Reasoning?
van Steenkiste, Sjoerd and Locatello, Francesco and Schmidhuber, Jürgen and Bachem, Olivier
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
van Steenkiste, Sjoerd and Locatello, Francesco and Schmidhuber, Jürgen and Bachem, Olivier
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Arguably, the central achievement of the deep learning era is multi-layer neural networks' ability to learn useful intermediate feature representations using a supervised learning signal. In a supervised task, it's easy to define what makes a feature representation useful: the fact that's easier for a subsequent layer to use to make the final class prediction. When we want to learn features in an unsupervised way, things get a bit trickier. There's the obvious problem of what kinds of problem structures and architectures work to extract representations at all. But there's also a deeper problem: when we ask for a good feature representation, outside of the context of any given task, what are we asking for? Are there some inherent aspects of a representation that can be analyzed without ground truth labels to tell you whether the representations you've learned are good are not? The notion of "disentangled" features is one answer to that question: it suggests that a representation is good when the underlying "factors of variation" (things that are independently variable in the underlying generative process of the data) are captured in independent dimensions of the feature representation. That is, if your representation is a ten-dimensional vector, and it just so happens that there are ten independent factors along which datapoints differ (color, shape, rotation, etc), you'd ideally want each dimension to correspond to each factor. This criteria has an elegance to it, and it's previously been shown useful in predicting when the representations learned by a model will be useful in predicting the values of the factors of variation. This paper goes one step further, and tests the value representations for solving a visual reasoning task that involves the factors of variation, but doesn't just involve predicting them. In particular, the authors use learned representations to solve a task patterned on a human IQ test, where some factors stay fixed across a row in a grid, and some vary, and the model needs to generate the image that "fits the pattern". https://i.imgur.com/O1aZzcN.png To test the value of disentanglement, they looked at a few canonical metrics of disentanglement, including scores that represent "how many factors are captured in each dimension" and "how many dimensions is a factor spread across". They measured the correlation of these metrics with task performance, and compared that with the correlation between simple autoencoder reconstruction error and performance. They found that at early stages of training on top of the representations, the disentanglement metrics were more predictive of performance than reconstruction accuracy. This distinction went away as the model learning on top of the representations had more time to train. It makes reasonable sense that you'd mostly see value for disentangled features in a low-data regime, since after long enough the fine-tuning network can learn its own features regardless. But, this paper does appear to contribute to evidence that disentangled features are predictive of task performance, at least when that task directly involves manipulation of specific, known, underlying factors of variation. |
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
Yu, Haonan and Edunov, Sergey and Tian, Yuandong and Morcos, Ari S.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Yu, Haonan and Edunov, Sergey and Tian, Yuandong and Morcos, Ari S.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Summary: An odd thing about machine learning these days is how far you can get in a line of research while only ever testing your method on image classification and image datasets in general. This leads one occasionally to wonder whether a given phenomenon or advance is a discovery of the field generally, or whether it's just a fact about the informatics and learning dynamics inherent in image data. This paper, part of a set of recent papers released by Facebook centering around the Lottery Ticket Hypothesis, exists in the noble tradition of "lets try <thing> on some non-image datasets, and see if it still works". This can feel a bit silly in the cases where the ideas or approaches do transfer, but I think it's still an important impulse for the field to have, lest we become too captured by ImageNet and its various descendants. This paper test the Lottery Ticket Hypothesis - the idea that there are a small subset of weights in a trained network whose lucky initializations promoted learning, such that if you reset those weights to their initializations and train only them you get comparable or near-comparable performance to the full network - on reinforcement learning and NLP datasets. In particular, within RL, they tested on both simple continuous control (where the observation state is a vector of meaningful numbers) and Atari from pixels (where the observation is a full from-pixels image). In NLP, they trained on language modeling and translation, with both a LSTM and a Transformer respectively. (Prior work had found that Transformers didn't exhibit lottery ticket like phenomenon, but this paper found a circumstance where they appear to. ) Some high level interesting results: https://i.imgur.com/kd03bQ4.png https://i.imgur.com/rZTH7FJ.png - So as to not bury the lede: by and large, "winning" tickets retrained at their original initializations outperform random initializations of the same size and configuration on both NLP and Reinforcement Learning problems - There is wide variability in how much pruning in general (a necessary prerequisite operation) impacts reinforcement learning. On some games, pruning at all crashes performance, on others, it actually improves it. This leads to some inherent variability in results https://i.imgur.com/4o71XPt.png - One thing that prior researchers in this area have found is that pruning weights all at once at the end of training tends to crash performance for complex models, and that in order to find pruned models that have Lottery Ticket-esque high-performing properties, you need to do "iterative pruning". This works by training a model for a period, then pruning some proportion of weights, then training again from the beginning, and then pruning again, and so on, until you prune down to the full percentage you want to prune. The idea is that this lets the model adapt gradually to a drop in weights, and "train around" the capacity reduction, rather than it just happening all at once. In this paper, the authors find that this is strongly necessary for Lottery Tickets to be found for either Transformers or many RL problems. On a surface level, this makes sense, since Reinforcement Learning is a notoriously tricky and non-stationary learning problem, and Transformers are complex models with lots of parameters, and so dramatically reducing parameters can handicap the model. A weird wrinkle, though, is that the authors find that lottery tickets found without iterative pruning actually perform worse than "random tickets" (i.e. initialized subnetworks with random topology and weights). This is pretty interesting, since it implies that the topology and weights you get if you prune all at once are actually counterproductive to learning. I don't have a good intuition as to why, but would love to hear if anyone does. https://i.imgur.com/9LnJe6j.png - For the Transformer specifically, there was an interesting divergence in the impact of weight pruning between the weights of the embedding matrix and the weights of the rest of the network machinery. If you include embeddings in the set of weights being pruned, there's essentially no difference in performance between random and winning tickets, whereas if you exclude them, winning tickets exhibit the more typical pattern of outperforming random ones. This implies that whatever phenomenon that makes winning tickets better is more strongly (or perhaps only) present in weights for feature calculation on top of embeddings, and not very present for the embeddings themselves |
Uncertainty-guided Continual Learning with Bayesian Neural Networks
Ebrahimi, Sayna and Elhoseiny, Mohamed and Darrell, Trevor and Rohrbach, Marcus
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ebrahimi, Sayna and Elhoseiny, Mohamed and Darrell, Trevor and Rohrbach, Marcus
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
## Introduction Bayesian Neural Networks (BNN): intrinsic importance model based on weight uncertainty; variational inference can approximate posterior distributions using Monte Carlo sampling for gradient estimation; acts like an ensemble method in that they reduce the prediction variance but only uses 2x the number of parameters. The idea is to use BNN's uncertainty to guide gradient descent to not update the important weight when learning new tasks. ## Bayes by Backprop (BBB): https://i.imgur.com/7o4gQMI.png Where $q(w|\theta)$ is our approximation of the posterior $p(w|x)$. $q$ is most probably gaussian with diagonal covariance. We can optimize this via the ELBO: https://i.imgur.com/OwGm20b.png ## Uncertainty-guided CL with BNN (UCB): UCB the regularizing is performed with the learning rate such that the learning rate of each parameter and hence its gradient update becomes a function of its importance. They set the importance to be inversely proportional to the standard deviation $\sigma$ of $q(w|\theta)$ Simply put, the more confident the posterior is about a certain weight, the less is this weight going to be updated. You can also use the importance for weight pruning (sort of a hard version of the first idea) ## Cartoon https://i.imgur.com/6Ld79BS.png |

One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers
Morcos, Ari S. and Yu, Haonan and Paganini, Michela and Tian, Yuandong
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Morcos, Ari S. and Yu, Haonan and Paganini, Michela and Tian, Yuandong
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In my view, the Lottery Ticket Hypothesis is one of the weirder and more mysterious phenomena of the last few years of Machine Learning. We've known for awhile that we can take trained networks and prune them down to a small fraction of their weights (keeping those weights with the highest magnitudes) and maintain test performance using only those learned weights. That seemed somewhat surprising, in that there were a lot of weights that weren't actually necessary to encoding the learned function, but, the thinking went, possibly having many times more weights than that was helpful for training, even if not necessary once a model is trained. The authors of the original Lottery Ticket paper came to the surprising realization that they could take the weights that were pruned to exist in the final network, re-initialize them (and only them) to the values they had during initial training, and perform almost as well as the final pruned model that had all weights active during training. And, performance using the specific weights and their particular initialization values is much higher than training a comparable topology of weights with random initial values. This paper out of Facebook AI adds another fascinating experiment to the pile of off evidence around lottery tickets: they test whether lottery tickets transfer *between datasets*, and they find that they often do (at least when the dataset on which the lottery ticket is found is more complex (in terms of in size, input complexity, or number of classes) than the dataset the ticket is being transferred to. Even more interestingly, they find that for sufficiently simple datasets, the "ticket" initialization pattern learned on a more complex dataset actually does *better* than ones learned on the simple dataset itself. They also find that tickets by and large transfer between SGD and Adam, so whatever kind of inductive bias or value they provide is general across optimizers in addition to at least partially general across datasets. https://i.imgur.com/H0aPjRN.png I find this result fun to think about through a few frames. The first is to remember that figuring out heuristics for initializing networks (as a function of their topology) was an important step in getting them to train at all, so while this result may at first seem strange and arcane, in that context it feels less surprising that there are still-better initialization heuristics out there, possibly with some kind of interesting theoretical justification to them, that humans simply haven't been clever enough to formalize yet, and have only discovered empirically through methods like this. This result is also interesting in terms of transfer: we've known for awhile that the representations learned on more complex datasets can convey general information back to smaller ones, but it's less easy to think about what information is conveyed by the topology and connectivity of a network. This paper suggests that the information is there, and has prompted me to think more about the slightly mind-bending question of how training models could lead to information compressed in this form, and how this information could be better understood. |
Generating Diverse High-Fidelity Images with VQ-VAE-2
Razavi, Ali and van den Oord, Aäron and Vinyals, Oriol
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Razavi, Ali and van den Oord, Aäron and Vinyals, Oriol
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
VQ-VAE is a Variational AutoEncoder that uses as its information bottleneck a discrete set of codes, rather than a continuous vector. That is: the encoder creates a downsampled spatial representation of the image, where in each grid cell of the downsampled image, the cell is represented by a vector. But, before that vector is passed to the decoder, it's discretized, by (effectively) clustering the vectors the network has historically seen, and substituting each vector with the center of the vector it's closest to. This has the effect of reducing the capacity of your information bottleneck, but without just pushing your encoded representation closer to an uninformed prior. (If you're wondering how the gradient survives this very much not continuous operation, the answer is: we just pretend that operation didn't exist, and imagine that the encoder produced the cluster-center "codebook" vector that the decoder sees). The part of the model that got a (small) upgrade in this paper is the prior distribution model that's learned on top of these latent representations. The goal of this prior is to be able to just sample images, unprompted, from the distribution of latent codes. Once we have a trained decoder, if we give it a grid of such codes, it can produce an image. But these codes aren't one-per-image, but rather a grid of many codes representing features in different part of the image. In order to generate a set of codes corresponding to a reasonable image, we can either generate them all at once, or else (as this paper does) use an autoregressive approach, where some parts of the code grid are generated, and then subsequent ones conditioned on those. In the original version of the paper, the autoregressive model used was a PixelCNN (don't have the space to fully explain that here, but, at a high level: a model that uses convolutions over previously generated regions to generate a new region). In this paper, the authors took inspiration from the huge rise of self-attention in recent years, and swapped that operation in in lieu of the convolutions. Self-attention has the nice benefit that you can easily have a global receptive range (each region being generated can see all other regions) which you'd otherwise need multiple layers of convolutions to accomplish. In addition, the authors add an additional layer of granularity: generating both a 32x32 and 64x64 grid, and using both to generate the decoded reconstruction. They argue that this allows one representation to focus on more global details, and the other on more precise ones. https://i.imgur.com/zD78Pp4.png The final result is the ability to generate quite realistic looking images, that at least are being claimed to be more diverse than those generated by GANs (examples above). I'm always a bit cautious of claims of better performance in the image-generation area, because it's all squinting at pixels and making up somewhat-reasonable but still arbitrary metrics. That said, it seems interesting and useful to be aware of the current relative capabilities of two of the main forms of generative modeling, and so I'd recommend this paper on that front, even if it's hard for me personally to confidently assess the improvements on prior art. |
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser and Ioannis Antonoglou and Thomas Hubert and Karen Simonyan and Laurent Sifre and Simon Schmitt and Arthur Guez and Edward Lockhart and Demis Hassabis and Thore Graepel and Timothy Lillicrap and David Silver
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/11/19 (4 years ago)
Abstract: Constructing agents with planning capabilities has long been one of the main challenges in the pursuit of artificial intelligence. Tree-based planning methods have enjoyed huge success in challenging domains, such as chess and Go, where a perfect simulator is available. However, in real-world problems the dynamics governing the environment are often complex and unknown. In this work we present the MuZero algorithm which, by combining a tree-based search with a learned model, achieves superhuman performance in a range of challenging and visually complex domains, without any knowledge of their underlying dynamics. MuZero learns a model that, when applied iteratively, predicts the quantities most directly relevant to planning: the reward, the action-selection policy, and the value function. When evaluated on 57 different Atari games - the canonical video game environment for testing AI techniques, in which model-based planning approaches have historically struggled - our new algorithm achieved a new state of the art. When evaluated on Go, chess and shogi, without any knowledge of the game rules, MuZero matched the superhuman performance of the AlphaZero algorithm that was supplied with the game rules.
more
less
Julian Schrittwieser and Ioannis Antonoglou and Thomas Hubert and Karen Simonyan and Laurent Sifre and Simon Schmitt and Arthur Guez and Edward Lockhart and Demis Hassabis and Thore Graepel and Timothy Lillicrap and David Silver
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/11/19 (4 years ago)
Abstract: Constructing agents with planning capabilities has long been one of the main challenges in the pursuit of artificial intelligence. Tree-based planning methods have enjoyed huge success in challenging domains, such as chess and Go, where a perfect simulator is available. However, in real-world problems the dynamics governing the environment are often complex and unknown. In this work we present the MuZero algorithm which, by combining a tree-based search with a learned model, achieves superhuman performance in a range of challenging and visually complex domains, without any knowledge of their underlying dynamics. MuZero learns a model that, when applied iteratively, predicts the quantities most directly relevant to planning: the reward, the action-selection policy, and the value function. When evaluated on 57 different Atari games - the canonical video game environment for testing AI techniques, in which model-based planning approaches have historically struggled - our new algorithm achieved a new state of the art. When evaluated on Go, chess and shogi, without any knowledge of the game rules, MuZero matched the superhuman performance of the AlphaZero algorithm that was supplied with the game rules.
|
[link]
The successes of deep learning on complex strategic games like Chess and Go have been largely driven by the ability to do tree search: that is, simulating sequences of actions in the environment, and then training policy and value functions to more speedily approximate the results that more exhaustive search reveals. However, this relies on having a good simulator that can predict the next state of the world, given your action. In some games, with straightforward rules, this is easy to explicitly code, but in many RL tasks like Atari, and in many contexts in the real world, having a good model of how the world responds to your actions is in fact a major part of the difficulty of RL. A response to this within the literature has been systems that learn models of the world from trajectories, and then use those models to do this kind of simulated planning. Historically these have been done by designing models that predict the next observation, given past observations and a passed-in action. This lets you "roll out" observations from actions in a way similar to how a simulator could. However, in high-dimensional observation spaces it takes a lot of model capacity to accurately model the full observation, and many parts of a given observation space will often be irrelevant. https://i.imgur.com/wKK8cnj.png To address this difficulty, the MuZero architecture uses an approach from Value Prediction Networks, and learns an internal model that can predict transitions between abstract states (which don't need to match the actual observation state of the world) and then predict a policy, value, and next-step reward from the abstract state. So, we can plan in latent space, by simulating transitions from state to state through actions, and the training signal for that space representation and transition model comes from being able to accurately predict the reward, the empirical future value at a state (discovered through Monte Carlo rollouts) and the policy action that the rollout search would have taken at that point. If two observations are identical in terms of their implications for these quantities, the transition model doesn't need to differentiate them, making it more straightforward to learn. (Apologies for the long caption in above screenshot; I feel like it's quite useful to gain intuition, especially if you're less recently familiar with the MCTS deep learning architectures DeepMind typically uses) https://i.imgur.com/4nepG6o.png The most impressive empirical aspect of this paper is the fact that it claims (from what I can tell credibly) to be able to perform as well as planning algorithms with access to a real simulator in games like Chess and Go, and as well as model-free models in games like Atari where MFRL has typically been the state of the art (because world models have been difficult to learn). I feel like I've read a lot recently that suggests to me that the distinction between model-free and model-based RL is becoming increasingly blurred, and I'm really curious to see how that trajectory evolves in future. |
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Jaques, Natasha and Ghandeharioun, Asma and Shen, Judy Hanwen and Ferguson, Craig and Lapedriza, Àgata and Jones, Noah and Gu, Shixiang and Picard, Rosalind W.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Jaques, Natasha and Ghandeharioun, Asma and Shen, Judy Hanwen and Ferguson, Craig and Lapedriza, Àgata and Jones, Noah and Gu, Shixiang and Picard, Rosalind W.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Given the tasks that RL is typically used to perform, it can be easy to equate the problem of reinforcement learning with "learning dynamically, online, as you take actions in an environment". And while this does represent most RL problems in the literature, it is possible to learn a reinforcement learning system in an off-policy way (read: trained off of data that the policy itself didn't collect), and there can be compelling reasons to prefer this approach. In this paper, which seeks to train a chatbot to learn from implicit human feedback in text interactions, the authors note prior bad experiences with Microsoft's Tay bot, and highlight the value of being able to test and validate a learned model offline, rather than have it continue to learn in a deployment setting. This problem, of learning a RL model off of pre-collected data, is known as batch RL. In this setting, the batch is collected by simply using a pretrained language model to generate interactions with a human, and then extracting reward from these interactions to train a Q learning system once the data has been collected. If naively applied, Q learning (a good approach for off-policy problems, since it directly estimates the value of states and actions rather than of a policy) can lead to some undesirable results in a batch setting. An interesting one, that hadn't occurred to me, was the fact that Q learning translates its (state, action) reward model into a policy by taking the action associated with the highest reward. This is a generally sensible thing to do if you've been able to gather data on all or most of a state space, but it can also bias the model to taking actions that it has less data for, because high-variance estimates will tend make up a disproportionate amount of maximum values of any estimated distribution. One approach to this is to learn two separate Q functions, and take the minimum over them, and then take the max of that across actions (in this case: words in a sentence being generated). The idea here is that low-data, high-variance parts of state space might have one estimate be high, but might have the other be low, because high variance. However, it's costly to train and run two separate models. Instead, the authors here propose the simpler solution of training a single model with dropout, and using multiple "draws" from that model to simulate a distribution over Q value estimates. This will have a similar effect of penalizing actions whose estimate varies across different dropout masks (which can be hand-wavily thought of as different models). The authors also add a term to their RL training that penalizes divergence from the initial language model that they used to collect the data, and also that is the initialization point for the parameters of the model. This is done via KL-divergence control: the model is penalized for outputting a distribution over words that is different in distributional-metric terms from what the language model would have output. This makes it costlier for the model to diverge from the pretrained model, and should lead to it only happening in cases of convincing high reward. Out of these two approaches, it seems like the former is more convincing to me as a general-purpose method to use in batch RL settings. The latter is definitely something I would have expected to work well (and, indeed, KL-controlled models performed much better in empirical tests in the paper!), but more simply because language modeling is hard, and I would expect it to be good to constrain a model to be close to realistic outputs, since the sentiment-based reward signal won't reward realism directly. This seems more like something generally useful for avoiding catastrophic forgetting when switching from an old task to a new one (language modeling to sentiment modeling), rather than a particularly batch-RL-centric innovation. https://i.imgur.com/EmInxOJ.png An interesting empirical observation of this paper is that models without language-model control end up drifting away from realism, and repeatedly exploit part of the reward function that, in addition to sentiment, gave points for asking questions. By contrast, the KL-controlled models appear to have avoided falling into this local minimum, and instead generated realistic language that was polite and empathetic. (Obviously this is still a simplified approximation of what makes a good chat bot, but it's at least a higher degree of complexity in its response to reward). Overall, I quite enjoyed this paper, both for its thoughtfulness and its clever application of engineering to use RL for a problem well outside of its more typical domain. |
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
At a high level, this paper is a massive (34 pgs!) and highly-resourced study of many nuanced variations of language pretraining tasks, to see which of those variants produce models that transfer the best to new tasks. As a result, it doesn't lend itself *that* well to being summarized into a central kernel of understanding. So, I'm going to do my best to pull out some high-level insights, and recommend you read the paper in more depth if you're working particularly in language pretraining and want to get the details. The goals here are simple: create a standardized task structure and a big dataset, so that you can use the same architecture across a wide range of objectives and subsequent transfer tasks, and thus actually compare tasks on equal footing. To that end, the authors created a huge dataset by scraping internet text, and filtering it according to a few common sense criteria. This is an important and laudable task, but not one with a ton of conceptual nuance to it. https://i.imgur.com/5z6bN8d.png A more interesting structural choice was to adopt a unified text to text framework for all of the tasks they might want their pretrained model to transfer to. This means that the input to the model is always a sequence of tokens, and so is the output. If the task is translation, the input sequence might be "translate english to german: build a bed" and the the desired output would be that sentence in German. This gets particularly interesting as a change when it comes to tasks where you're predicting relationships of words within sentences, and would typically have a categorical classification loss, which is changed here to predicting the word of the correct class. This restructuring doesn't seem to hurt performance, and has the nice side effect that you can directly use the same model as a transfer starting point for all tasks, without having to add additional layers. Some of the transfer tasks include: translation, sentiment analysis, summarization, grammatical checking of a sentence, and checking the logical relationship between claims. All tested models followed a transformer (i.e. fully attentional) architecture. The authors tested performance along many different axes. A structural variation was the difference between an encoder-decoder architecture and a language model one. https://i.imgur.com/x4AOkLz.png In both cases, you take in text and predict text, but in an encoder-decoder, you have separate models that operate on the input and output, whereas in a language model, it's all seen as part of a single continuous sequence. They also tested variations in what pretraining objective is used. The most common is simple language modeling, where you predict words in a sentence given prior or surrounding ones, but, inspired by the success of BERT, they also tried a number of denoising objectives, where an original sentence was corrupted in some way (by dropping tokens and replacing them with either masks, nothing, or random tokens, dropping individual words vs contiguous spans of words) and then the model had to predict the actual original sentence. https://i.imgur.com/b5Eowl0.png Finally, they performed testing as to the effect of dataset size and number of training steps. Some interesting takeaways: - In almost all tests, the encoder-decoder architecture, where you separately build representations of your input and output text, performs better than a language model structure. This is still generally (though not as consistently) true if you halve the number of parameters in the encoder-decoder, suggesting that there's some structural advantage there beyond just additional parameter count. - A denoising, BERT-style objective works consistently better than a language modeling one. Within the set of different kinds of corruption, none work obviously and consistently better across tasks, though some have a particular advantage at a given task, and some are faster to train with due to different lengths of output text. - Unsurprisingly, more data and bigger models both lead to better performance. Somewhat interestingly, training with less data but the same number of training iterations (such that you see the same data multiple times) seems to be fine up to a point. This potentially gestures at an ability to train over a dataset a higher number of times without being as worried about overfitting. - Also somewhat unsurprisingly, training on a dataset that filters out HTML, random lorem-ipsum web text, and bad words performs meaningfully better than training on one that doesn't |
Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck
Igl, Maximilian and Ciosek, Kamil and Li, Yingzhen and Tschiatschek, Sebastian and Zhang, Cheng and Devlin, Sam and Hofmann, Katja
- 2019 via Local Bibsonomy
Keywords: approximate, readings, generalization, optimization, information, compression, theory
Igl, Maximilian and Ciosek, Kamil and Li, Yingzhen and Tschiatschek, Sebastian and Zhang, Cheng and Devlin, Sam and Hofmann, Katja
- 2019 via Local Bibsonomy
Keywords: approximate, readings, generalization, optimization, information, compression, theory
|
[link]
Coming from the perspective of the rest of machine learning, a somewhat odd thing about reinforcement learning that often goes unnoticed is the fact that, in basically all reinforcement learning, performance of an algorithm is judged by its performance on the same environment it was trained on. In the parlance of ML writ large: training on the test set. In RL, most of the focus has historically been on whether automatic systems would be able to learn a policy from the state distribution of a single environment, already a fairly hard task. But, now that RL has had more success in the single-environment case, there comes the question: how can we train reinforcement algorithms that don't just perform well on a single environment, but over a range of environments. One lens onto this question is that of meta-learning, but this paper takes a different approach, and looks at how straightforward regularization techniques pulled from the land of supervised learning can (or can't straightforwardly) be applied to reinforcement learning. In general, the regularization techniques discussed here are all ways of reducing the capacity of the model, and preventing it from overfitting. Some ways to reduce capacity are: - Apply L2 weight penalization - Apply dropout, which handicaps the model by randomly zeroing out neurons - Use Batch Norm, which uses noisy batch statistics, and increases randomness in a way that, similar to above, deteriorates performance - Use an information bottleneck: similar to a VAE, this approach works by learning some compressed representation of your input, p(z|x), and then predicting your output off of that z, in a way that incentivizes your z to be informative (because you want to be able to predict y well) but also penalizes too much information being put in it (because you penalize differences between your learned p(z|x) distribution and an unconditional prior p(z) ). This pushes your model to use its conditional-on-x capacity wisely, and only learn features if they're quite valuable in predicting y However, the paper points out that there are some complications in straightforwardly applying these techniques to RL. The central one is the fact that in (most) RL, the distribution of transitions you train on comes from prior iterations of your policy. This means that a noisier and less competent policy will also leave you with less data to train on. Additionally, using a noisy policy can increase variance, both by making your trained policy more different than your rollout policy (in an off-policy setting) and by making your estimate of the value function higher-variance, which is problematic because that's what you're using as a target training signal in a temporal difference framework. The paper is a bit disconnected in its connection between justification and theory, and makes two broad, mostly distinct proposals: 1. The most successful (though also the one least directly justified by the earlier-discussed theoretical difficulties of applying regularization in RL) is an information bottleneck ported into a RL setting. It works almost the same as the classification-model one, except that you're trying to increase the value of your actions given compressed-from-state representation z, rather than trying to increase your ability to correctly predict y. The justification given here is that it's good to incentivize RL algorithms in particular to learn simpler, more compressible features, because they often have such poor data and also training signal earlier in training 2. SNI (Selective Noise Injection) works by only applying stochastic aspects of regularization (sampling from z in an information bottleneck, applying different dropout masks, etc) to certain parts of the training procedure. In particular, the rollout used to collect data is non-stochastic, removing the issue of noisiness impacting the data that's collected. They then do an interesting thing where they calculate a weighted mixture of the policy update with a deterministic model, and the update with a stochastic one. The best performing of these that they tested seems to have been a 50/50 split. This is essentially just a knob you can turn on stochasticity, to trade off between the regularizing effect of noise and the variance-increasing-negative effect of it. https://i.imgur.com/fi0dHgf.png https://i.imgur.com/LLbDaRw.png Based on my read of the experiments in the paper, the most impressive thing here is how well their information bottleneck mechanism works as a way to improve generalization, compared to both the baseline and other regularization approaches. It does look like there's some additional benefit to SNI, particularly in the CoinRun setting, but very little in the MultiRoom setting, and in general the difference is less dramatic than the difference from using the information bottleneck. |
Adversarial Self-Defense for Cycle-Consistent GANs
Bashkirova, Dina and Usman, Ben and Saenko, Kate
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Bashkirova, Dina and Usman, Ben and Saenko, Kate
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Domain translation - for example, mapping from a summer to a winter scene, or from a photorealistic image to an object segmentation map - is often performed by GANs through something called cycle consistency loss. This model works by having, for each domain, a generator to map domain A into domain B, and a discriminator to differentiate between real images from domain B, and those that were constructed through the cross-domain generator. With a given image in domain A, training happens by using the A→B generator to map it into domain B, and then then B→ A generator to map it back the original domain. These generators are then trained using two losses: one based on the B-domain discriminator, to push the generated image to look like it belongs from that domain, and another based on the L2 loss between the original domain A image, and the image you get on the other end when you translate it into B and back again. This paper addresses an effect (identified originally in an earlier paper) where in domains with a many to one mapping between domains (for example, mapping a realistic scene into a domain segmentation map, where information is inherently lost by translating pixels to object outlines), the cycle loss incentivizes the model to operate in a strange, steganographic way, where it saves information about the that would otherwise be lost in the form of low-amplitude random noise in the translated image. This low-amplitude information can't be isolated, but can be detected in a few ways. First, we can simply examine images and notice that information that could not have been captured in the lower-information domain is being perfectly reconstructed. Second, if you add noise to the translation in the lower-information domain, in such a way as to not perceptibly change the translation to human eyes, this can cause the predicted image off of that translation to deteriorate considerably, suggesting that the model was using information that could be modified by such small additions of noise to do its reconstruction. https://i.imgur.com/08i1j0J.png The authors of this paper ask whether it's possible to train models that don't perform this steganographic information-storing (which they call "self adversarial examples"). A typical approach to such a problem would be to train generators to perform translations with and without the steganographic information, but even though we can prove the existence of the information, we can't isolate it in a way that would allow us to remove it, and thus create these kinds of training pairs. The two tactics the paper uses are: 1) Simply training the generators to be able to translate a domain-mapped image with noise as well as one without noise, in the hope that this would train it not use information that can be interfered with by the application of such noise. 2) In addition to a L2 cycle loss, adding a discriminator to differentiate between the back-translated image and the original one. I believe the idea here is that if both of the encoders are adding in noise as a kind of secret signal, this would be a way for the discriminator to distinguish between the original and reconstructed image, and would thus be penalized. They find that both of these methods reduce the use of steganographic information, as determined both by sensitivity to noise (where less sensitivity of reconstruction to noise means less use of coded information) and reconstruction honesty (which constrains accuracy of reconstruction in many to one domains to be no greater than the prediction that a supervised predictor could make given the image from the compressed domain |
CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning
Girdhar, Rohit and Ramanan, Deva
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Girdhar, Rohit and Ramanan, Deva
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In Machine Learning, our models are lazy: they're only ever as good as the datasets we train them on. If a task doesn't require a given capability in order for a model to solve it, then the model won't gain that capability. This fact motivates a desire on the part of researchers to construct new datasets, to provide both a source of signal and a not-yet-met standard against which models can be measured. This paper focuses on the domain of reasoning about videos and the objects within them across frames. It observes that, on many tasks that ostensibly require a model to follow what's happening in a video, models that simply aggregate some set of features across frames can do as well as models that actually track and account for temporal evolution from one frame for another. They argue that this shows that, on these tasks, which often involve real-world scenes, the model can predict what's happening within a frame simply based on expectations of the world that can be gleaned from single frames - for example, if you see a swimming pool, you can guess that swimming is likely to take place there. As an example of the kind of task they'd like to get a model to solve, they showed a scene from the Godfather where a character leaves the room, puts a gun in his pocket, and returns to the room. Any human viewer could infer that the gun is in his pocket when it returns, but there doesn't exist any single individual frame that could give evidence of that, so it requires reasoning across frames.
https://i.imgur.com/F2Ngsgw.png
To get around this inherent layer of bias in real-world scenes, the authors decide to artificially construct their own dataset, where objects are moved, and some objects are moved to be contained and obscured within others, in an entirely neutral environment, where the model can't generally get useful information from single frames. This is done using the same animation environment as is used in CLEVR, which contains simple objects that have color, texture, and shape, and that can be moved around a scene. Within this environment, called CATER, the benchmark is made up of three tasks:
- Simply predicting what action ("slide cone" or "pick up and place box") is happening in a given frame. For actions like sliding, where in a given frame a sliding cone is indistinguishable from a static one, this requires a model to actually track prior position in order to correctly predict an action taking place
- Being able to correctly identify the order in which a given pair of actions occurs
- Watching a single golden object that can be moved and contained within other objects (entertainingly enough, for Harry Potter fans, called the snitch), and guessing what frame it's in at the end of the scene. This is basically just the "put a ball in a cup and move it around" party trick, but as a learning task
https://i.imgur.com/bBhPnFZ.png
The authors do show that the "frame aggregation/pooling" methods that worked well on previous datasets don't work well on this dataset - which accords with both expectations and the authors goals. Obviously, it's still a fairly simplified environment, but they hope CATER can still be a useful shared benchmark for people working in the space to solve a task that is known to require more explicit spatiotemporal reasoning.
|
Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
Ovadia, Yaniv and Fertig, Emily and Ren, Jie and Nado, Zachary and Sculley, David and Nowozin, Sebastian and Dillon, Joshua V. and Lakshminarayanan, Balaji and Snoek, Jasper
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ovadia, Yaniv and Fertig, Emily and Ren, Jie and Nado, Zachary and Sculley, David and Nowozin, Sebastian and Dillon, Joshua V. and Lakshminarayanan, Balaji and Snoek, Jasper
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
A common critique of deep learning is its brittleness off-distribution, combined with its tendency to give confident predictions for off-distribution inputs, as is seen in the case of adversarial examples. In response to this critique, a number of different methods have cropped up in recent years, that try to capture a model's uncertainty as well as its overall prediction. This paper tries to do a broad evaluation of uncertainty methods, and, particularly, to test how they perform on out of distribution data, including both data that is perturbed from its original values, and fully OOD data from ground-truth categories never seen during training. Ideally, we would want an uncertainty method that is less confident in its predictions as data is made more dissimilar from the distribution that the model is trained on. Some metrics the paper uses for capturing this are: - Brier Score (The difference between predicted score and ground truth 0/1 label, averaged over all examples) - Negative Log Likelihood - Expected Calibration Error (Within a given bucket, this is calculated as the difference between accuracy to ground truth labels, and the average predicted score in that bucket, capturing that you'd ideally want to have a lower predicted score in cases where you have low accuracy, and vice versa) - Entropy - For labels that are fully out of distribution, and don't map to any of the model's categories, you can't directly calculate ground truth accuracy, but you can ideally ask for a model that has high entropy (close to uniform) probabilities over the classes it knows about when the image is drawn from an entirely different class The authors test over image datasets small (MNIST) and large (ImageNet and CIFAR10), as well as a categorical ad-click-prediction dataset. They came up with some interesting findings. https://i.imgur.com/EVnjS1R.png 1. More fully principled Bayesian estimation of posteriors over parameters, in the form of Stochastic Variational Inference, works well on MNIST, but quite poorly on either categorical data or higher dimensional image datasets https://i.imgur.com/3emTYNP.png 2. Temperature scaling, which basically performs a second supervised calibration using a hold-out set to push your probabilities towards true probabilities, performs well in-distribution but collapses fairly quickly off-distribution (which sort of makes sense given that it too is just another supervised method that can do poorly when off-distribution) 3. In general, ensemble methods, where you train different models on different subsets of the data and take their variance as uncertainty, perform the best across the bigger image models as well as the ad click model, likely because SVI (along with many other Bayesian methods) is too computationally intensive to get to work well on higher-dimensional data 4. Overall, none of the methods worked particularly well, and even the best-performing ones were often confidently wrong off-distribution I think it's fair to say that we're far from where we wish we were when it comes to models that "know when they don't know," and this paper does a good job of highlighting that in specific fashion.
1 Comments
 |
Goal-conditioned Imitation Learning
Ding, Yiming and Florensa, Carlos and Phielipp, Mariano and Abbeel, Pieter
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ding, Yiming and Florensa, Carlos and Phielipp, Mariano and Abbeel, Pieter
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper combines imitation learning algorithm GAIL with recent advances in goal-conditioned reinforcement learning, to create a combined approach that can make efficient use of demonstrations, but can also learn information about a reward that can allow the agent to outperform the demonstrator. Goal-conditioned learning is a form of reward-driven reinforcement learning where the reward is a defined to be 1 when an agent reaches a particular state, and 0 otherwise. This can be a particularly useful form of learning for navigation tasks, where, instead of only training your agent to reach a single hardcoded goal (as you would with a reward function) you teach it to reach arbitrary goals when information about the goal is passed in as input. A typical difficulty with this kind of learning is that its reward is sparse: for any given goal, if an agent never reaches it, it won't ever get reward signal it can use to learn to find it again. A clever solution to this, proposed by earlier method HER (Hindsight Experience Replay), is to perform rollouts of the agent trajectory, and then train your model to reach all the states it actually reached along that trajectory. Said another way, even if your agent did a random, useless thing with respect to one goal, if you retroactively decided that the goal was where it ended up, then it'd be able to receive reward signal after all. In a learning scenario with a fixed reward, this trick wouldn't make any sense, since you don't want to train your model to only go wherever it happened to initially end up. But because the policy here is goal-conditioned, we're not giving our policy wrong information about how to go to the place we want, we're incentivizing it to remember ways it got to where it ended up, in the hopes that it can learn generalizable things about how to reach new places. The other technique being combined in this paper is imitation learning, or learning from demonstrations. Demonstrations can be highly useful for showing the agent how to get to regions of state space it might not find on its own. The authors of this paper advocate creating a goal-conditioned version of one particular imitation learning algorithm (Generative Adversarial Imitation Learning, or GAIL), and combining that with an off-policy version of Hindsight Experience Replay. In their model, a discriminator tries to tell the behavior of the demonstrator from that of the agent, given some input goal, and uses that as loss, combined with the loss of a more normal Q learning loss with a reward set to 1 when a goal is achieved. Importantly, they amplify both of these methods using the relabeling trick mentioned before: for both the demonstrators and the actual agent trajectories, they take tuples of (state, next state, goal) and replace the intended goal with another state reached later in the trajectory. For the Q learner, this performs its normal role as a way to get reward in otherwise sparse settings, and for the imitation learner, it is a form of data amplification, where a single trajectory + goal can be turned into multiple trajectories "successfully" reaching all of the intermediate points along the observed trajectory. The authors show that their method learns more quickly (as a result of the demonstrations), but also is able to outperform demonstrators, which it wouldn't generally be able to do without an independent, non-demonstrator reward signal |
Online Meta-Learning
Finn, Chelsea and Rajeswaran, Aravind and Kakade, Sham M. and Levine, Sergey
International Conference on Machine Learning - 2019 via Local Bibsonomy
Keywords: dblp
Finn, Chelsea and Rajeswaran, Aravind and Kakade, Sham M. and Levine, Sergey
International Conference on Machine Learning - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
## Introduction Two distinct research paradigms have studied how prior tasks or experiences can be used by an agent to inform future learning. * Meta Learning: past experience is used to acquire a prior over model parameters or a learning procedure, and typically studies a setting where a set of meta-training tasks are made available together upfront * Online learning : a sequential setting where tasks are revealed one after another, but aims to attain zero-shot generalization without any task-specific adaptation. We argue that neither setting is ideal for studying continual lifelong learning. Meta-learning deals with learning to learn, but neglects the sequential and non-stationary aspects of the problem. Online learning offers an appealing theoretical framework, but does not generally consider how past experience can accelerate adaptation to a new task. ## Online Learning Online learning focuses on regret minimization. Most standard notion of regret is to compare to the cumulative loss of the best fixed model in hindsight: https://i.imgur.com/pbZG4kK.png One way minimize regret is with Follow the Leader (FTL): https://i.imgur.com/NCs73vG.png ## Online Meta-learning Setting: let $U_t$ be the update procedure for task $t$ e.g. in MAML: https://i.imgur.com/Q4I4HkD.png The overall protocol for the setting is as follows: 1. At round t, the agent chooses a model defined by $w_t$ 2. The world simultaneously chooses task defined by $f_t$ 3. The agent obtains access to the update procedure $U_t$, and uses it to update parameters as $\tilde w_t = U_t(w_t)$ 4. The agent incurs loss $f_t(\tilde w_t )$. Advance to round t + 1. the goal for the agent is to minimize regrets over rounds. Achieving sublinear regrets means you're improving and converging to upper bound (joint training on all tasks) ## Algorithm and Analysis: Follow the meta-leader (FTML): https://i.imgur.com/qWb9g8Q.png FTML’s regret is sublinear (under some assumption) |
FreeLB: Enhanced Adversarial Training for Language Understanding
Zhu, Chen and Cheng, Yu and Gan, Zhe and Sun, Siqi and Goldstein, Tom and Liu, Jingjing
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Zhu, Chen and Cheng, Yu and Gan, Zhe and Sun, Siqi and Goldstein, Tom and Liu, Jingjing
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Adversarial examples and defenses to prevent them are often presented as a case of inherent model fragility, where the model is making a clear and identifiable mistake, by misclassifying a label humans would classify correctly. But, another frame on the adversarial examples research is that they're a way of imposing a certain kind of prior requirement on our models: that they be sensitive to certain scales of perturbation to their inputs. One reason to want to do this is because you believe the model might reasonably need to interact with such perturbed inputs in future. But, another is that smoothness of model outputs, in the sense of an output that doesn't change sharply in the immediate vicinity of an example, can be a useful inductive bias that improves generalization. In images, this is often not the case, as training on adversarial examples empirically worsens performance on normal examples. In text, however, it seems like you can get more benefit out of training on adversarial examples, and this paper proposes a specific way of doing that. An interesting up-front distinction is the one between generating adversarial examples in embeddings vs raw text. Raw text is generally harder: it's unclear how to permute sentences in ways that leave them grammatically and meaningfully unchanged, and thus mean that the same label is the "correct" one as before, without human input. So the paper instead works in embedding space: adding a delta vectors of adversarial noise to the learned word embeddings used in a text model. One salient downside of generating adversarial examples to train on is that doing so is generally costly: it requires calculating the gradients with respect to the input to calculate the direction of the delta vector, which requires another backwards pass through the network, in addition to the ones needed to calculate the parameter gradients to update those. It happens to be the case that once you've calculated gradients w.r.t inputs, doing so for parameters is basically done for you for free, so one possible solution to this problem is to do a step of parameter gradient calculation/model training every time you take a step of perturbation generation. However, if you're generating your adversarial examples via multi-step Projected Gradient Descent, doing a step of model training at each of the K steps in multi-step PGD means that by the time you finish all K steps and are ready to train on the example, your perturbation vector is out of sync with with your model parameters, and so isn't optimally adversarial. To fix this, the authors propose actually training on the adversarial example generated by each step in the multi-step generation process, not just the example produced at the end. So, instead of training your model on perturbations of a given size, you train them on every perturbation up to and including that size. This also solves the problem of your perturbation being out of sync with your parameters, since you "apply" your perturbation in training at the same step where you calculate it. The authors sole purpose in this was to make models that generalize better, and they show reasonably convincing evidence that this method works slightly better than competing alternatives on language modeling tasks. More saliently, in my view, they come up with a straightforward and clever solution to a problem, which could potentially be used in other domains. |
Ease-of-Teaching and Language Structure from Emergent Communication
Li, Fushan and Bowling, Michael
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Li, Fushan and Bowling, Michael
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
An interesting category of machine learning papers - to which this paper belongs - are papers which use learning systems as a way to explore the incentive structures of problems that are difficult to intuitively reason about the equilibrium properties of. In this paper, the authors are trying to better understand how different dynamics of a cooperative communication game between agents, where the speaking agent is trying to describe an object such that the listening agent picks the one the speaker is being shown, influence the communication protocol (or, to slightly anthropomorphize, the language) that the agents end up using. In particular, the authors experiment with what happens when the listening agent is frequently replaced during training with a untrained listener who has no prior experience with the agent. The idea of this experiment is that if the speaker is in a scenario where listeners need to frequently "re-learn" the mapping between communication symbols and objects, this will provide an incentive for that mapping to be easier to quickly learn. https://i.imgur.com/8csqWsY.png The metric of ease of learning that the paper focuses on is "topographic similarity", which is a measure of how compositional the communication protocol is. The objects they're working with have two properties, and the agents use a pair of two discrete symbols (two letters) to communicate about them. A perfectly compositional language would use one of the symbols to represent each of the properties. To mathematically measure this property, the authors calculate (cosine) similarity between the two objects property vectors, and the (edit) distance between the two objects descriptions under the emergent language, and calculate the correlation between these quantities. In this experimental setup, if a language is perfectly compositional, the correlation will be perfect, because every time a property is the same, the same symbol will be used, so two objects that share that property will always share that symbol in their linguistic representation. https://i.imgur.com/t5VxEoX.png The premise and the experimental setup of this paper are interesting, but I found the experimental results difficult to gain intuition and confidence from. The authors do show that, in a regime where listeners are reset, topographic similarity rises from a beginning-of-training value of .54 to an end of training value of .59, whereas in the baseline, no-reset regime, the value drops to .51. So there definitely is some amount of support for their claim that listener resets lead to higher compositionality. But given that their central quality is just a correlation between similarities, it's hard to gain intuition for whether the difference is a meaningful. It doesn't naively seem particularly dramatic, and it's hard to tell otherwise without more references for how topographic similarity would change under a wider range of different training scenarios. |
Plan Arithmetic: Compositional Plan Vectors for Multi-Task Control
Devin, Coline and Geng, Daniel and Abbeel, Pieter and Darrell, Trevor and Levine, Sergey
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Devin, Coline and Geng, Daniel and Abbeel, Pieter and Darrell, Trevor and Levine, Sergey
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
If you've been at all aware of machine learning in the past five years, you've almost certainly seen the canonical word2vec example demonstrating additive properties of word embeddings: "king - man + woman = queen". This paper has a goal of designing embeddings for agent plans or trajectories that follow similar principles, such that a task composed of multiple subtasks can be represented by adding the vectors corresponding to the subtasks. For example, if a task involved getting an ax and then going to a tree, you'd want to be able to generate an embedding that corresponded to a policy to execute that task by summing the embeddings for "go to ax" and "go to tree". https://i.imgur.com/AHlCt76.png The authors don't assume that they know the discrete boundaries between subtasks in multiple-task trajectories, and instead use a relatively simple and clever training structure in order to induce the behavior described above. They construct some network g(x) that takes in information describing a trajectory (in this case, start and end state, but presumably could be more specific transitions), and produces an embedding. Then, they train a model on an imitation learning problem, where, given one demonstration of performing a particular task (typically generated by the authors to be composed of multiple subtasks), the agent needs to predict what action will be taken next in a second trajectory of the same composite task. At each point in the sequence of predicting the next action, the agent calculates the embedding of the full reference trajectory, and the embedding of the actions they have so far performed in the current stage in the predicted trajectory, and calculates the difference between these two values. This embedding difference is used to condition the policy function that predicts next action. At each point, you enforce this constraint, that the embedding of what is remaining to be done in the trajectory be close to the embedding of (full trajectory) - (what has so far been completed), by making the policy that corresponds with that embedding map to the remaining part of the trajectory. In addition to this core loss, they also have a few regularization losses, including: 1. A loss that goes through different temporal subdivisions of reference, and pushes the summed embedding of the two parts to be close to the embedding of the whole 2. A loss that simply pushes the embeddings of the two paired trajectories performing the same task closer together The authors test mostly on relatively simple tasks - picking up and moving sequences of objects with a robotic arm, moving around and picking up objects in a simplified Minecraft world - but do find that their central partial-conditioning-based loss gives them better performance on demonstration tasks that are made up of many subtasks. Overall, this is an interesting and clever paper: it definitely targeted additive composition much more directly, rather than situations like the original word2vec where additivity came as a side effect of other properties, but it's still an idea that I could imagine having interesting properties, and one I'd be interested to see applied to a wider variety of tasks. |
RTFM: Generalising to Novel Environment Dynamics via Reading
Zhong, Victor and Rocktäschel, Tim and Grefenstette, Edward
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Zhong, Victor and Rocktäschel, Tim and Grefenstette, Edward
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Reinforcement learning is notoriously sample-inefficient, and one reason why is that agents learn about the world entirely through experience, and it takes lots of experience to learn useful things. One solution you might imagine to this problem is the ones humans by and large use in encountering new environments: instead of learning everything through first-person exploration, acquiring lots of your knowledge by hearing or reading condensed descriptions of the world that can help you take more sensible actions within it. This paper and others like it have the goal of learning RL agents that can take in information about the world in the form of text, and use that information to solve a task. This paper is not the first to propose a solution in this general domain, but it claims to be unique by dint of having both the dynamics of the environment and the goal of the agent change on a per-environment basis, and be described in text. The precise details of the architecture used are very much the result of particular engineering done to solve this problem, and as such, it's a bit hard to abstract away generalizable principles that this paper showed, other than the proof of concept fact that tasks of the form they describe - where an agent has to learn which objects can kill which enemies, and pursue the goal of killing certain ones - can be solved. Arguably the most central design principle of the paper is aggressive and repeated use of different forms of conditioning architectures, to fully mix the information contained in the textual and visual data streams. This was done in two main ways: - Multiple different attention summaries were created, using the document embedding as input, but with queries conditioned on different things (the task, the inventory, a summarized form of the visual features). This is a natural but clever extension of the fact that attention is an easy way to generate conditional aggregated versions of some input https://i.imgur.com/xIsRu2M.png - The architecture uses FiLM (Featurewise Linear Modulation), which is essentially a many-generations-generalized version of conditional batch normalization in which the gamma and lambda used to globally shift and scale a feature vector are learned, taking some other data as input. The canonical version of this would be taking in text input, summarizing it into a vector, and then using that vector as input in a MLP that generates gamma and lambda parameters for all of the convolutional layers in a vision system. The interesting innovation of this paper is essentially to argue that this conditioning operation is quite neutral, and that there's no essential way in which the vision input is the "true" data, and the text simply the auxiliary conditioning data: it's more accurate to say that each form of data should conditioning the process of the other one. And so they use Bidirectional FiLM, which does just that, conditioning vision features on text summaries, but also conditioning text features on vision summaries. https://i.imgur.com/qFaH1k3.png - The model overall is composed of multiple layers that perform both this mixing FiLM operation, and also visually-conditioned attention. The authors did show, not super surprisingly, that these additional forms of conditioning added performance value to the model relative to the cases where they were ablated |
Deep High-Resolution Representation Learning for Human Pose Estimation
Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong
Conference and Computer Vision and Pattern Recognition - 2019 via Local Bibsonomy
Keywords: dblp
Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong
Conference and Computer Vision and Pattern Recognition - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper is a top-down (i.e. requires person detection separately) pose estimation method with a focus on improving high-resolution representations (features) to make keypoint detection easier. During the training stage, this method utilizes annotated bounding boxes of person class to extract ground truth images and keypoints. The data augmentations include random rotation, random scale, flipping, and [half body augmentations](http://presentations.cocodataset.org/ECCV18/COCO18-Keypoints-Megvii.pdf) (feeding upper or lower part of the body separately). Heatmap learning is performed in a typical for this task approach of applying L2 loss between predicted keypoint locations and ground truth locations (generated by applying 2D Gaussian with std = 1). During the inference stage, pre-trained object detector is used to provide bounding boxes. The final heatmap is obtained by averaging heatmaps obtained from the original and flipped images. The pixel location of the keypoint is determined by $argmax$ heatmap value with a quarter offset in the direction to the second-highest heatmap value. While the pipeline described in this paper is a common practice for pose estimation methods, this method can achieve better results by proposing a network design to extract better representations. This is done through having several parallel sub-networks of different resolutions (next one is half the size of the previous one) while repeatedly fusing branches between each other: https://raw.githubusercontent.com/leoxiaobin/deep-high-resolution-net.pytorch/master/figures/hrnet.png The fusion process varies depending on the scale of the sub-network and its location in relation to others: https://i.imgur.com/mGDn7pT.png |

Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
Freeman, C. Daniel and Metz, Luke and Ha, David
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Freeman, C. Daniel and Metz, Luke and Ha, David
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Reinforcement Learning is often broadly separated into two categories of approaches: model-free and model-based. In the former category, networks simply take observations and input and produce predicted best-actions (or predicted values of available actions) as output. In order to perform well, the model obviously needs to gain an understanding of how its actions influence the world, but it doesn't explicitly make predictions about what the state of the world will be after an action is taken. In model-based approaches, the agent explicitly builds a dynamics model, or a model in which it takes in (past state, action) and predicts next state. In theory, learning such a model can lead to both interpretability (because you can "see" what the model thinks the world is like) and robustness to different reward functions (because you're learning about the world in a way not explicitly tied up with the reward). This paper proposes an interesting melding of these two paradigms, where an agent learns a model of the world as part of an end-to-end policy learning. This works through something the authors call "observational dropout": the internal model predicts the next state of the world given the prior one and the action, and then with some probability, the state of the world that both the policy and the next iteration of the dynamics model sees is replaced with the model's prediction. This incentivizes the network to learn an effective dynamics model, because the farther the predictions of the model are from the true state of the world, the worse the performance of the learned policy will be on the iterations where the only observation it can see is the predicted one. So, this architecture is model-free in the sense that the gradient used to train the system is based on applying policy gradients to the reward, but model-based in the sense that it does have an internal world representation. https://i.imgur.com/H0TNfTh.png The authors find that, at a simple task, Swing Up Cartpole, very low probabilities of seeing the true world (and thus very high probabilities of the policy only seeing the dynamics model output) lead to world models good enough that a policy trained only on trajectories sampled from that model can perform relatively well. This suggests that at higher probabilities of the true world, there was less value in the dynamics model being accurate, and consequently less training signal for it. (Of course, policies that often could only see the predicted world performed worse during their original training iteration compared to policies that could see the real world more frequently). On a more complex task of CarRacing, the authors looked at how well a policy trained using the representations of the world model as input could perform, to examine whether it was learning useful things about the world. https://i.imgur.com/v9etll0.png They found an interesting trade-off, where at high probabilities (like before) the dynamics model had little incentive to be good, but at low probabilities it didn't have enough contact with the real dynamics of the world to learn a sensible policy. |
Are Sixteen Heads Really Better than One?
Michel, Paul and Levy, Omer and Neubig, Graham
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Michel, Paul and Levy, Omer and Neubig, Graham
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In the last two years, the Transformer architecture has taken over the worlds of language modeling and machine translation. The central idea of Transformers is to use self-attention to aggregate information from variable-length sequences, a task for which Recurrent Neural Networks had previously been the most common choice. Beyond that central structural change, one more nuanced change was from having a single attention mechanism on a given layer (with a single set of query, key, and value weights) to having multiple attention heads, each with their own set of weights. The change was framed as being conceptually analogous to the value of having multiple feature dimensions, each of which focuses on a different aspect of input; these multiple heads could now specialize and perform different weighted sums over input based on their specialized function. This paper performs an experimental probe into the value of the various attention heads at test time, and tries a number of different pruning tests across both machine translation and language modeling architectures to see their impact on performance. In their first ablation experiment, they test the effect of removing (that is, zero-masking the contribution of) a single head from a single attention layer, and find that in almost all cases (88 out of 96) there's no statistically significant drop in performance. Pushing beyond this, they ask what happens if, in a given layer, they remove all heads but the one that was seen to be most important in the single head tests (the head that, if masked, caused the largest performance drop). This definitely leads to more performance degradation than the removal of single heads, but the degradation is less than might be intuitively expected, and is often also not statistically significant. https://i.imgur.com/Qqh9fFG.png This also shows an interesting distribution over where performance drops: in machine translation, it seems like decoder-decoder attention is the least sensitive to heads being pruned, and encoder-decoder attention is the most sensitive, with a very dramatic performance dropoff observed if particularly the last layer of encoder-decoder attention is stripped to a single head. This is interesting to me insofar as it shows the intuitive roots of attention in these architectures; attention was originally used in encoder-decoder parts of models to solve problems of pulling out information in a source sentence at the time it's needed in the target sentence, and this result suggests that a lot of the value of multiple heads in translation came from making that mechanism more expressive. Finally, the authors performed an iterative pruning test, where they ordered all the heads in the network according to their single-head importance, and pruned starting with the least important. Similar to the results above, they find that drops in performance at high rates of pruning happen eventually to all parts of the model, but that encoder-decoder attention suffers more quickly and more dramatically if heads are removed. https://i.imgur.com/oS5H1BU.png Overall, this is a clean and straightforward empirical paper that asks a fairly narrow question and generates some interesting findings through that question. These results seem reminiscent to me of the Lottery Ticket Hypothesis line of work, where it seems that having a network with a lot of weights is useful for training insofar as it gives you more chances at an initialization that allows for learning, but that at test time, only a small percentage of the weights have ultimately become important, and the rest can be pruned. In order to make the comparison more robust, I'd be interested to see work that does more specific testing of the number of heads required for good performance during training and also during testing, divided out by different areas of the network. (Also, possibly this work exists and I haven't found it!) |
Wasserstein Dependency Measure for Representation Learning
Ozair, Sherjil and Lynch, Corey and Bengio, Yoshua and van den Oord, Aäron and Levine, Sergey and Sermanet, Pierre
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ozair, Sherjil and Lynch, Corey and Bengio, Yoshua and van den Oord, Aäron and Levine, Sergey and Sermanet, Pierre
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Self-Supervised Learning is a broad category of approaches whose goal is to learn useful representations by asking networks to perform constructed tasks that only use the content of a dataset itself, and not external labels. The idea with these tasks is to design tasks such that solving them requires the network to have learned useful Some examples of this approach include predicting the rotation of rotated images, reconstructing color from greyscale, and, the topic of this paper, maximizing mutual information between different areas of the image. The hope behind this last approach is that if two areas of an image are generated by the same set of underlying factors (in the case of a human face: they're parts of the same person's face), then a representation that correctly captures those factors for one area will give you a lot of information about the representation of the other area. Historically, this conceptual desire for representations that are mutually informative has been captured by mutual information. If we define the representation distribution over the data of area 1 as p(x) and area 2 as q(x), the mutual information is the KL divergence between the joint distribution of these two distributions and the product of their marginals. This is an old statistical intuition: the closer the joint is to the product of marginals, the closer the variables are to independent; the farther away, the closer they are to informationally identical. https://i.imgur.com/2SzD5d5.png This paper argues that the presence of the KL divergence in this mutual information formulation impedes the ability of networks to learn useful representations. This argument is theoretically based on a result from a recent paper (which for the moment I'll just take as foundation, without reading it myself) that empirical lower-bound measurements of mutual information, of the kind used in these settings, are upper bounded by log(n) where n is datapoints. Our hope in maximizing a lower bound to any quantity is that the bound is fairly tight, since that means that optimizing a network to push upward a lower bound actually has the effect of pushing the actual value up as well. If the lower bound we can estimate is constrained to be far below the actual lower bound in the data, then pushing it upward doesn't actually require the value to move upward. The authors identify this as a particular problem in areas where the underlying mutual information of the data is high, such as in videos where one frame is very predictive of the next, since in those cases the constraint imposed by the dataset size will be small relative to the actual possible maximum mutual information you could push your network to achieve. https://i.imgur.com/wm39mQ8.png Taking a leaf out of the GAN literature, the authors suggest keeping replacing the KL divergence component of mutual information and replacing it with the Wasserstein Distance; otherwise known as the "earth-mover distance", the Wasserstein distance measures the cost of the least costly way to move probability mass from one distribution to another, assuming you're moving that mass along some metric space. A nice property of the Wasserstein distance, in both GANs and in this application) is that they don't saturate quite as quickly: the value of a KL divergence can shoot up if the distributions are even somewhat different, making it unable to differentiate between distributions that are somewhat and very far away, whereas a Wasserstein distance continues to have more meaningful signal in that regime. In the context of the swap for mutual information, the authors come up with the "Wasserstein Dependency Measure", which is just the Wasserstein Distance between the joint distributions and the product of the marginals. https://i.imgur.com/3s2QRRz.png In practice, they use the dual formulation of the Wasserstein distance, which amounts to applying a (neural network) function f(x) to values from both distributions, optimizing f(x) so that the values are far apart, and using that distance as your training signal. Crucially, this function has to be relatively smooth in order for the dual formulation to work: in particular it has to have a small Lipschitz value (meaning its derivatives are bounded by some value). Intuitively, this has the effect of restricting the capacity of the network, which is hoped to incentivize it to use its limited capacity to represent true factors of variation, which are assumed to be the most compact way to represent the data. Empirically, the authors found that their proposed Wasserstein Dependency Measure (with a slight variation applied to reduce variance) does have the predicted property of performing better for situations where the native mutual information between two areas is high. I found the theoretical points of this paper interesting, and liked the generalization of the idea of Wasserstein distances from GANs to a new area. That said, I wish I had a better mechanical sense for how it ground out in actual neural network losses: this is partially just my own lack of familiarity with how e.g. mutual information losses are actually formulated as network objectives, but I would have appreciated an appendix that did a bit more of that mapping between mathematical intuition and practical network reality. |
Explanations can be manipulated and geometry is to blame
Dombrowski, Ann-Kathrin and Alber, Maximilian and Anders, Christopher J. and Ackermann, Marcel and Müller, Klaus-Robert and Kessel, Pan
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Dombrowski, Ann-Kathrin and Alber, Maximilian and Anders, Christopher J. and Ackermann, Marcel and Müller, Klaus-Robert and Kessel, Pan
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In response to increasing calls for ways to explain and interpret the predictions of neural networks, one major genre of explanation has been the construction of salience maps for image-based tasks. These maps assign a relevance or saliency score to every pixel in the image, according to various criteria by which the value of a pixel can be said to have influenced the final prediction of the network. This paper is an interesting blend of ideas from the saliency mapping literature with ones from adversarial examples: it essentially shows that you can create adversarial examples whose goal isn't to change the output of a classifier, but instead to keep the output of the classifier fixed, but radically change the explanation (their term for the previously-described pixel saliency map that results from various explanation-finding methods) to resemble some desired target explanation. This is basically a targeted adversarial example, but targeting a different property of the network (the calculated explanation) while keeping an additional one fixed (keeping the output of the original network close to the original output, as well as keeping the input image itself in a norm ball around the original image. This is done in a pretty standard way: by just defining a loss function incentivizing closeness to the original output and also closeness of the explanation to the desired target, and performing gradient descent to modify pixels until this loss was low. https://i.imgur.com/N9uReoJ.png The authors do a decent job of showing such targeted perturbations are possible: by my assessment of their results their strongest successes at inducing an actual targeted explanation are with Layerwise Relevance Propogation and Pattern Attribution (two of the 6 tested explanation methods). With the other methods, I definitely buy that they're able to induce an explanation that's very unlike the true/original explanation, but it's not as clear they can reach an arbitrary target. This is a bit of squinting, but it seems like they have more success in influencing propogation methods (where the effect size of the output is propogated backwards through the network, accounting for ReLus) than they do with gradient ones (where you're simply looking at the gradient of the output class w.r.t each pixel. In the theory section of the paper, the authors do a bit of differential geometry that I'll be up front and say I did not have the niche knowledge to follow, but which essentially argues that the manipulability of an explanation has to do with the curvature of the output manifold for a constant output. That is to say: how much can you induce a large change in the gradient of the output, while moving a small distance along the manifold of a constant output value. They then go on to argue that ReLU activations, because they are by definition discontinuous, induce sharp changes in gradient for points nearby one another, and this increase the ability for networks to be manipulated. They propose a softplus activation instead, where instead of a sharp discontinuity, the ReLU shape becomes more curved, and show relatively convincingly that at low values of Beta (more curved) you can mostly eliminate the ability of a perturbation to induce an adversarially targeted explanation. https://i.imgur.com/Fwu3PXi.png For all that I didn't have a completely solid grasp of some of the theory sections here, I think this is a neat proof of concept paper in showing that neural networks can be small-perturbation fragile on a lot of different axes: we've known this for a while in the area of adversarial examples, but this is a neat generalization of that fact to a new area. |
Saccader: Improving Accuracy of Hard Attention Models for Vision
Elsayed, Gamaleldin F. and Kornblith, Simon and Le, Quoc V.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Elsayed, Gamaleldin F. and Kornblith, Simon and Le, Quoc V.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
If your goal is to interpret the predictions of neural networks on images, there are a few different ways you can focus your attention. One approach is to try to understand and attach conceptual tags to learnt features, to form a vocabulary with which models can be understood. However, techniques in this family have to content with a number of challenges, from the difficulty in attaching clear concepts to the sheer number of neurons to interpret. An alternate approach, and the one pursued by this paper, is to frame interpretability as a matter of introspecting on *where in an image* the model is pulling information from to make its decision. This is the question for which hard attention provides an answer: identify where in an image a model is making a decision by learning a meta-model that selects small patches of an image, and then makes a classification decision by applying a network to only those patches which were selected. By definition, if only a discrete set of patches were used for prediction, those were the ones that could be driving the model's decision. This central fact of the model only choosing a discrete set of patches is a key complexity, since the choice to use a patch or not is a binary, discontinuous action, and not something through which one can back-propogate gradients. Saccader, the approach put forward by this paper, proposes an architecture which extracts features from locations within an image, and uses those spatially located features to inform a stochastic policy that selects each patch with some probability. Because reinforcement learning by construction is structured to allow discrete actions, the system as a whole can be trained via policy gradient methods. https://i.imgur.com/SPK0SLI.png Diving into a bit more detail: while I don't have a deep familiarity with prior work in this area, my impression is that the notion of using policy gradient to learn a hard attention policy isn't a novel contribution of this work, but rather than its novelty comes from clever engineering done to make that policy easier to learn. The authors cite the problem of sparse reward in learning the policy, which I presume to mean that if you start in more traditional RL fashion by just sampling random patches, most patches will be unclear or useless in providing classification signal, so it will be hard to train well. The Saccader architecture works by extracting localized features in an architecture inspired by the 2019 BagNet paper, which essentially applies very tall and narrow convolutional stacks to spatially small areas of the image. This makes it the case that feature vectors for different overlapping patches can be computed efficiently: instead of rerunning the network again for each patch, it just combined the features from the "tops" of all of the small column networks inside the patch, and used that aggregation as a patch-level feature. These features from the "representation network" were then used in an "attention network," which uses larger receptive field convolutions to create patch-level features that integrated the context of things around them. Once these two sets of features were created, they were fed into the "Saccader cell", which uses them to calculate a distribution over patches which the policy then samples over. The Saccader cell is a simplified memory cell, which sets a value to 1 when a patch has been sampled, and applies a very strong penalization on that patch being sampled on future "glimpses" from the policy (in general, classification is performed by making a number of draws and averaging the logits produced for each patch). https://i.imgur.com/5pSL0oc.png I found this paper fairly conceptually clever - I hadn't thought much about using a reinforcement learning setup for classification before - though a bit difficult to follow in its terminology and notation. It's able to perform relatively well on ImageNet, though I'm not steeped enough in that as a benchmark to have an intuitive sense for the paper's claim that their accuracy is meaningfully in the same ballpark as full-image models. One interesting point the paper made was that their system, while limited to small receptive fields for the patch features, can use an entirely different model for mapping patches to logits once the patches are selected, and so can benefit from more powerful generic classification models being tacked onto the end. |
Meta-Learning with Implicit Gradients
Aravind Rajeswaran and Chelsea Finn and Sham Kakade and Sergey Levine
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, math.OC, stat.ML
First published: 2019/09/10 (4 years ago)
Abstract: A core capability of intelligent systems is the ability to quickly learn new tasks by drawing on prior experience. Gradient (or optimization) based meta-learning has recently emerged as an effective approach for few-shot learning. In this formulation, meta-parameters are learned in the outer loop, while task-specific models are learned in the inner-loop, by using only a small amount of data from the current task. A key challenge in scaling these approaches is the need to differentiate through the inner loop learning process, which can impose considerable computational and memory burdens. By drawing upon implicit differentiation, we develop the implicit MAML algorithm, which depends only on the solution to the inner level optimization and not the path taken by the inner loop optimizer. This effectively decouples the meta-gradient computation from the choice of inner loop optimizer. As a result, our approach is agnostic to the choice of inner loop optimizer and can gracefully handle many gradient steps without vanishing gradients or memory constraints. Theoretically, we prove that implicit MAML can compute accurate meta-gradients with a memory footprint that is, up to small constant factors, no more than that which is required to compute a single inner loop gradient and at no overall increase in the total computational cost. Experimentally, we show that these benefits of implicit MAML translate into empirical gains on few-shot image recognition benchmarks.
more
less
Aravind Rajeswaran and Chelsea Finn and Sham Kakade and Sergey Levine
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, math.OC, stat.ML
First published: 2019/09/10 (4 years ago)
Abstract: A core capability of intelligent systems is the ability to quickly learn new tasks by drawing on prior experience. Gradient (or optimization) based meta-learning has recently emerged as an effective approach for few-shot learning. In this formulation, meta-parameters are learned in the outer loop, while task-specific models are learned in the inner-loop, by using only a small amount of data from the current task. A key challenge in scaling these approaches is the need to differentiate through the inner loop learning process, which can impose considerable computational and memory burdens. By drawing upon implicit differentiation, we develop the implicit MAML algorithm, which depends only on the solution to the inner level optimization and not the path taken by the inner loop optimizer. This effectively decouples the meta-gradient computation from the choice of inner loop optimizer. As a result, our approach is agnostic to the choice of inner loop optimizer and can gracefully handle many gradient steps without vanishing gradients or memory constraints. Theoretically, we prove that implicit MAML can compute accurate meta-gradients with a memory footprint that is, up to small constant factors, no more than that which is required to compute a single inner loop gradient and at no overall increase in the total computational cost. Experimentally, we show that these benefits of implicit MAML translate into empirical gains on few-shot image recognition benchmarks.
|
[link]
This paper builds upon the previous work in gradient-based meta-learning methods.
The objective of meta-learning is to find meta-parameters ($\theta$) which can be "adapted" to yield "task-specific" ($\phi$) parameters.
Thus, $\theta$ and $\phi$ lie in the same hyperspace.
A meta-learning problem deals with several tasks, where each task is specified by its respective training and test datasets.
At the inference time of gradient-based meta-learning methods, before the start of each task, one needs to perform some gradient-descent (GD) steps initialized from the meta-parameters to obtain these task-specific parameters.
The objective of meta-learning is to find $\theta$, such that GD on each task's training data yields parameters that generalize well on its test data.
Thus, the objective function of meta-learning is the average loss on the training dataset of each task ($\mathcal{L}_{i}(\phi)$), where the parameters of that task ($\phi$) are obtained by performing GD initialized from the meta-parameters ($\theta$).
\begin{equation}
F(\theta) = \frac{1}{M}\sum_{i=1}^{M} \mathcal{L}_i(\phi)
\end{equation}
In order to backpropagate the gradients for this task-specific loss function back to the meta-parameters, one needs to backpropagate through task-specific loss function ($\mathcal{L}_{i}$) and the GD steps (or any other optimization algorithm that was used), which were performed to yield $\phi$.
As GD is a series of steps, a whole sequence of changes done on $\theta$ need to be considered for backpropagation.
Thus, the past approaches have focused on RNN + BPTT or Truncated BPTT.
However, the author shows that with the use of the proximal term in the task-specific optimization (also called inner optimization), one can obtain the gradients without having to consider the entire trajectory of the parameters.
The authors call these implicit gradients.
The idea is to constrain the $\phi$ to lie closer to $\theta$ with the help of proximal term which is similar to L2-regularization penalty term.
Due to this constraint, one obtains an implicit equation of $\phi$ in terms of $\theta$ as
\begin{equation}
\phi = \theta - \frac{1}{\lambda}\nabla\mathcal{L}_i(\phi)
\end{equation}
This is then differentiated to obtain the implicit gradients as
\begin{equation}
\frac{d\phi}{d\theta} = \big( \mathbf{I} + \frac{1}{\lambda}\nabla^{2} \mathcal{L}_i(\phi) \big)^{-1}
\end{equation}
and the contribution of gradients from $\mathcal{L}_i$ is thus,
\begin{equation}
\big( \mathbf{I} + \frac{1}{\lambda}\nabla^{2} \mathcal{L}_i(\phi) \big)^{-1} \nabla \mathcal{L}_i(\phi)
\end{equation}
The hessian in the above gradients are memory expensive computations, which become infeasible in deep neural networks.
Thus, the authors approximate the above term by minimizing the quadratic formulation using conjugate gradient method which only requires Hessian-vector products (cheaply available via reverse backpropagation).
\begin{equation}
\min_{\mathbf{w}} \mathbf{w}^\intercal \big( I + \frac{1}{\lambda}\nabla^{2} \mathcal{L}_i(\phi) \big) \mathbf{w} - \mathbf{w}^\intercal \nabla \mathcal{L}_i(\phi)
\end{equation}
Thus, the paper introduces computationally cheap and constant memory gradient computation for meta-learning.
|

Temporal Cycle-Consistency Learning
Dwibedi, Debidatta and Aytar, Yusuf and Tompson, Jonathan and Sermanet, Pierre and Zisserman, Andrew
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Dwibedi, Debidatta and Aytar, Yusuf and Tompson, Jonathan and Sermanet, Pierre and Zisserman, Andrew
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
# Overview This paper presents a novel way to align frames in videos of similar actions temporally in a self-supervised setting. To do so, they leverage the concept of cycle-consistency. They introduce two formulations of cycle-consistency which are differentiable and solvable using standard gradient descent approaches. They name their method Temporal Cycle Consistency (TCC). They introduce a dataset that they use to evaluate their approach and show that their learned embeddings allow for few shot classification of actions from videos. Figure 1 shows the basic idea of what the paper aims to achieve. Given two video sequences, they wish to map the frames that are closest to each other in both sequences. The beauty here is that this "closeness" measure is defined by nearest neighbors in an embedding space, so the network has to figure out for itself what being close to another frame means. The cycle-consistency is what makes the network converge towards meaningful "closeness".  # Cycle Consistency Intuitively, the concept of cycle-consistency can be thought of like this: suppose you have an application that allows you to take the photo of a user X and increase their apparent age via some transformation F and decrease their age via some transformation G. The process is cycle-consistent if you can age your image, then using the aged image, "de-age" it and obtain something close to the original image you took; i.e. F(G(X)) ~= X. In this paper, cycle-consistency is defined in the context of nearest-neighbors in the embedding space. Suppose you have two video sequences, U and V. Take a frame embedding from U, u_i, and find its nearest neighbor in V's embedding space, v_j. Now take the frame embedding v_j and find its closest frame embedding in U, u_k, using a nearest-neighbors approach. If k=i, the frames are cycle consistent. Otherwise, they are not. The authors seek to maximize cycle consistency across frames. # Differentiable Cycle Consistency The authors present two differentiable methods for cycle-consistency; cycle-back classification and cycle-back regression. In order to make their cycle-consistency formulation differentiable, the authors use the concept of soft nearest neighbor: 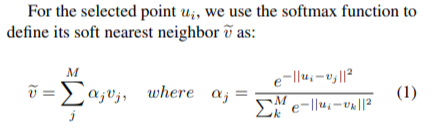 ## cycle-back classification Once the soft nearest neighbor v~ is computed, the euclidean distance between v~ and all u_k is computed for a total of N frames (assume N frames in U) in a logit vector x_k and softmaxed to a prediction ŷ = softmax(x): 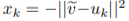. 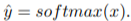 Note the clever use of the negative, which will ensure the softmax selects for the highest distance. The ground truth label is a one-hot vector of size 1xN where position i is set to 1 and all others are set to 0. Cross-entropy is then used to compute the loss. ## cycle-back regression The concept is very similar to cycle-back classification up to the soft nearest neighbor calculation. However the similarity metric of v~ back to u_k is not computed using euclidean distance but instead soft nearest neighbor again: 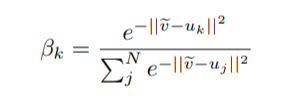 The idea is that they want to penalize the network less for "close enough" guesses. This is done by imposing a gaussian prior on beta centered around the actual closest neighbor i. 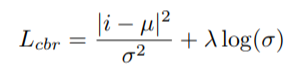 The following figure summarizes the pipeline: 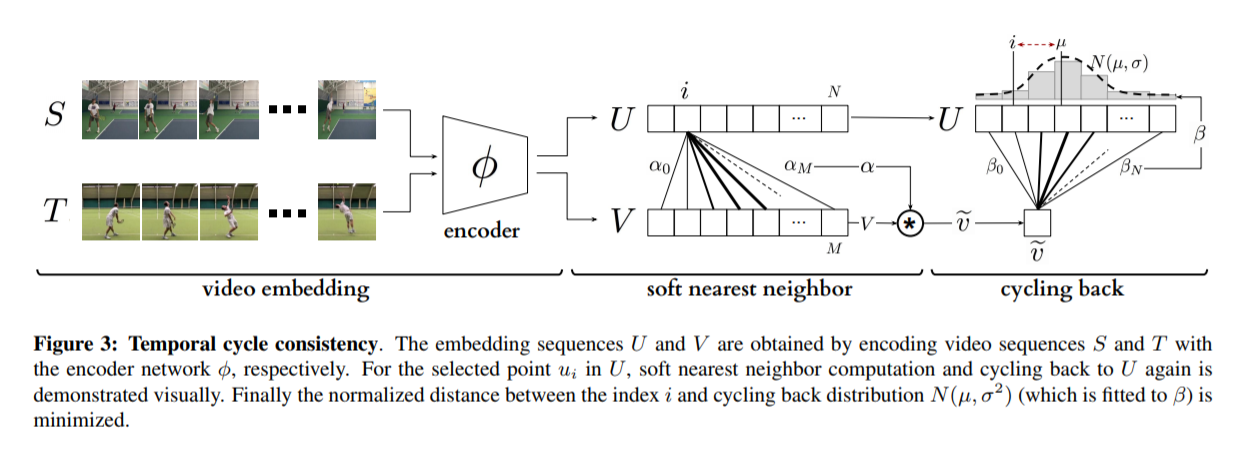 # Datasets All training is done in a self-supervised fashion. To evaluate their methods, they annotate the Pouring dataset, which they introduce and the Penn Action dataset. To annotate the datasets, they limit labels to specific events and phases between phases  # Model The network consists of two parts: an encoder network and an embedder network. ## Encoder They experiment with two encoders: * ResNet-50 pretrained on imagenet. They use conv_4 layer's output which is 14x14x1024 as the encoder scheme. * A Vgg-like model from scratch whose encoder output is 14x14x512. ## Embedder They then fuse the k following frame encodings along the time dimension, and feed it to an embedder network which uses 3D Convolutions and 3D pooling to reduce it to a 1x128 feature vector. They find that k=2 works pretty well.
1 Comments
 |

Benchmarking Model-Based Reinforcement Learning
Wang, Tingwu and Bao, Xuchan and Clavera, Ignasi and Hoang, Jerrick and Wen, Yeming and Langlois, Eric and Zhang, Shunshi and Zhang, Guodong and Abbeel, Pieter and Ba, Jimmy
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Wang, Tingwu and Bao, Xuchan and Clavera, Ignasi and Hoang, Jerrick and Wen, Yeming and Langlois, Eric and Zhang, Shunshi and Zhang, Guodong and Abbeel, Pieter and Ba, Jimmy
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This is not a detailed summary, just general notes:
Authors make a excellent and extensive comparison of Model Free, Model based methods in 18 environments. In general, the authors compare 3 classes of Model Based Reinforcement Learning (MBRL) algorithms using as metric for comparison the total return in the environment after 200K steps (reporting the mean and std by taking windows of 5000 steps throughout the whole training - and averaging across 4 seeds for each algorithm). They compare MBRL classes:
- **Dyna style:** using a policy to gather data, training a transition function model on this data(i.e. dynamics function / "world model"), and using data predicted by the model (i.e. "imaginary" data) to train the policy)
- **Policy Search with Backpropagation through Time (BPTT):** starting at some state $s_0$ the policy rolls out an episode using the model. Then given the trajectory and its sum of rewards (or any other objective function to maximize) one can differentiate this expression with respect to the policies parameters $\theta$
to obtain the gradient. The training process iterates between collecting data using the current policy and improving the policy via computing the BPTT gradient ... Some version include dynamic programming approaches where the ground -truth dynamics need to be known
- **Model Predictive Control (MPC) / Shooting methods:** There is in general no explicit policy to choose actions, rather the actions sequence is chosen by: starting with a set of candidates of actions sequences $a_{t:t+\tau}$ , propagating this actions sequences in the dynamics model, and then choosing the action sequence which achieved the highest return through out the propagated episode. Then, the agent only applies the first action from the optimal sequence and re-plans at every time-step.
They also compare this to Model Free (MF) methods such as SAC and TD3.
**Brief conclusions which I noticed from MB and MF comparisons:** (note the $>$
indicates better than )
- **MF:** SAC & TD3 $>$ PPO & TRPO
- **Performance:** MPC (shooting, robust performance except for complex env.) $>$ Dyna (bad for long H) $>$ BPTT (SVG very good for complex env.)
- **State and Action Noise:** MPC (shooting, re-planning compensates for noise) $>$ Dyna (lots of Model predictive errors … although meta learning actually benefits from noisy do to lack of exploration)
- **MB dynamics error accumulation:** MB performance plateaus, more data $\neq$ better performance $\rightarrow$ 1. prediction error accumulates through time 2. As we the policy and model improvement are closely link, we can (early) fall into local minima
- **Early Termination (ET):** including ET always negatively affects MB methods. Different ways of incorporating ET into planning horizon (see appendix G for details) work better for some environment but worst for more complex envs. - so, tbh theres no conclusion to be made about early termination schemes (same as for there entire paper :D, but it's not the authors fault, is just the (sad) direction in which most RL / DL research is moving in)
**Some stuff which seems counterintuitive:**
- Why can’t we see a significant sample efficiency of MB w.r.t to MF ?
- Why does PILCO suck at almost everything ? original authors/ implementation seems to excel at several tasks
- When using ensembles (e.g. PETS), why is predicting the next state as the Expectation over the ensemble (PE-E: $\boldsymbol{s}_{t+1}=\mathbb{E}\left[\widetilde{f}_{\boldsymbol{\theta}}\left(\boldsymbol{s}_{t}, \boldsymbol{a}_{t}\right)\right]$) better or at least highly comparable to propagating a particle by leveraging the ensemble of models (PE-TS: given $P$ initial states $\boldsymbol{s}_{t=0}^{p}=\boldsymbol{s}_{0} \forall \boldsymbol{p}$, propagate each state / particle $p$ using *one* model $b(p)$ from the entire ensemble ($B$), such that $\boldsymbol{s}_{t+1}^{p} \sim \tilde{f}_{\boldsymbol{\theta}_{b(p)}}\left(\boldsymbol{s}_{t}^{\boldsymbol{p}}, \boldsymbol{a}_{t}\right)$ ), which should in theory better capture uncertainty / multimodality of the State space ??
|

Online Continual Learning with Maximally Interfered Retrieval
Rahaf Aljundi and Lucas Caccia and Eugene Belilovsky and Massimo Caccia and Laurent Charlin and Tinne Tuytelaars
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/08/11 (4 years ago)
Abstract: Continual learning, the setting where a learning agent is faced with a never ending stream of data, continues to be a great challenge for modern machine learning systems. In particular the online or "single-pass through the data" setting has gained attention recently as a natural setting that is difficult to tackle. Methods based on replay, either generative or from a stored memory, have been shown to be effective approaches for continual learning, matching or exceeding the state of the art in a number of standard benchmarks. These approaches typically rely on randomly selecting samples from the replay memory or from a generative model, which is suboptimal. In this work we consider a controlled sampling of memories for replay. We retrieve the samples which are most interfered, i.e. whose prediction will be most negatively impacted by the foreseen parameters update. We show a formulation for this sampling criterion in both the generative replay and the experience replay setting, producing consistent gains in performance and greatly reduced forgetting.
more
less
Rahaf Aljundi and Lucas Caccia and Eugene Belilovsky and Massimo Caccia and Laurent Charlin and Tinne Tuytelaars
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/08/11 (4 years ago)
Abstract: Continual learning, the setting where a learning agent is faced with a never ending stream of data, continues to be a great challenge for modern machine learning systems. In particular the online or "single-pass through the data" setting has gained attention recently as a natural setting that is difficult to tackle. Methods based on replay, either generative or from a stored memory, have been shown to be effective approaches for continual learning, matching or exceeding the state of the art in a number of standard benchmarks. These approaches typically rely on randomly selecting samples from the replay memory or from a generative model, which is suboptimal. In this work we consider a controlled sampling of memories for replay. We retrieve the samples which are most interfered, i.e. whose prediction will be most negatively impacted by the foreseen parameters update. We show a formulation for this sampling criterion in both the generative replay and the experience replay setting, producing consistent gains in performance and greatly reduced forgetting.
|
[link]
Disclaimer: I am an author
# Intro
Experience replay (ER) and generative replay (GEN) are two effective continual learning strategies. In the former, samples from a stored memory are replayed to the continual learner to reduce forgetting. In the latter, old data is compressed with a generative model and generated data is replayed to the continual learner. Both of these strategies assume a random sampling of the memories. But learning a new task doesn't cause **equal** interference (forgetting) on the previous tasks!
In this work, we propose a controlled sampling of the replays. Specifically, we retrieve the samples which are most interfered, i.e. whose prediction will be most negatively impacted by the foreseen parameters update. The method is called Maximally Interfered Retrieval (MIR).
## Cartoon for explanation
https://i.imgur.com/5F3jT36.png
Learning about dogs and horses might cause more interference on lions and zebras than on cars and oranges. Thus, replaying lions and zebras would be a more efficient strategy.
# Method
1) incoming data: $(X_t,Y_t)$
2) foreseen parameter update: $\theta^v= \theta-\alpha\nabla\mathcal{L}(f_\theta(X_t),Y_t)$
### applied to ER (ER-MIR)
3) Search for the top-$k$ values $x$ in the stored memories using the criterion $$s_{MI}(x) = \mathcal{L}(f_{\theta^v}(x),y) -\mathcal{L}(f_{\theta}(x),y)$$
### or applied to GEN (GEN-MIR)
3)
$$
\underset{Z}{\max} \, \mathcal{L}\big(f_{\theta^v}(g_\gamma(Z)),Y^*\big) -\mathcal{L}\big(f_{\theta}(g_\gamma(Z)),Y^*\big)
$$
$$
\text{s.t.} \quad ||z_i-z_j||_2^2 > \epsilon \forall z_i,z_j \in Z \,\text{with} \, z_i\neq z_j
$$
i.e. search in the latent space of a generative model $g_\gamma$ for samples that are the most forgotten given the foreseen update.
4) Then add theses memories to incoming data $X_t$ and train $f_\theta$
# Results
### qualitative
https://i.imgur.com/ZRNTWXe.png
Whilst learning 8s and 9s (first row), GEN-MIR mainly retrieves 3s and 4s (bottom two rows) which are similar to 8s and 9s respectively.
### quantitative
GEN-MIR was tested on MNIST SPLIT and Permuted MNIST, outperforming the baselines in both cases.
ER-MIR was tested on MNIST SPLIT, Permuted MNIST and Split CIFAR-10, outperforming the baselines in all cases.
# Other stuff
### (for avid readers)
We propose a hybrid method (AE-MIR) in which the generative model is replaced with an autoencoder to facilitate the compression of harder dataset like e.g. CIFAR-10.
|
Explainable AI for Trees: From Local Explanations to Global Understanding
Lundberg, Scott M. and Erion, Gabriel and Chen, Hugh and DeGrave, Alex and Prutkin, Jordan M. and Nair, Bala and Katz, Ronit and Himmelfarb, Jonathan and Bansal, Nisha and Lee, Su-In
- 2019 via Local Bibsonomy
Keywords: interpretable
Lundberg, Scott M. and Erion, Gabriel and Chen, Hugh and DeGrave, Alex and Prutkin, Jordan M. and Nair, Bala and Katz, Ronit and Himmelfarb, Jonathan and Bansal, Nisha and Lee, Su-In
- 2019 via Local Bibsonomy
Keywords: interpretable
|
[link]
Tree-based ML models are becoming increasingly popular, but in the explanation space for these type of models is woefully lacking explanations on a local level. Local level explanations can give a clearer picture on specific use-cases and help pin point exact areas where the ML model maybe lacking in accuracy. **Idea**: We need a local explanation system for trees, that is not based on simple decision path, but rather weighs each feature in comparison to every other feature to gain better insight on the model's inner workings. **Solution**: This paper outlines a new methodology using SHAP relative values, to weigh pairs of features to get a better local explanation of a tree-based model. The paper also outlines how we can garner global level explanations from several local explanations, using the relative score for a large sample space. The paper also walks us through existing methodologies for local explanation, and why these are biased toward tree depth as opposed to actual feature importance. The proposed explanation model titled TreeExplainer exposes methods to compute optimal local explanation, garner global understanding from local explanations, and capture feature interaction within a tree based model. This method assigns Shapley interaction values to pairs of features essentially ranking the features so as to understand which features have a higher impact on overall outcomes, and analyze feature interaction. |

Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet
Brendel, Wieland and Bethge, Matthias
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Brendel, Wieland and Bethge, Matthias
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Brendel and Bethge show empirically that state-of-the-art deep neural networks on ImageNet rely to a large extent on local features, without any notion of interaction between them. To this end, they propose a bag-of-local-features model by applying a ResNet-like architecture on small patches of ImageNet images. The predictions of these local features are then averaged and a linear classifier is trained on top. Due to the locality, this model allows to inspect which areas in an image contribute to the model’s decision, as shown in Figure 1. Furthermore, these local features are sufficient for good performance on ImageNet. Finally, they show, on scrambled ImageNet images, that regular deep neural networks also rely heavily on local features, without any notion of spatial interaction between them. https://i.imgur.com/8NO1w0d.png Figure 1: Illustration of the heap maps obtained using BagNets, the bag-of-local-features model proposed in the paper. Here, different sizes for the local patches are used. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Towards Stable and Efficient Training of Verifiably Robust Neural Networks
Zhang, Huan and Chen, Hongge and Xiao, Chaowei and Li, Bo and Boning, Duane S. and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Zhang, Huan and Chen, Hongge and Xiao, Chaowei and Li, Bo and Boning, Duane S. and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Zhang et al. combine interval bound propagation and CROWN, both approaches to obtain bounds on a network’s output, to efficiently train robust networks. Both interval bound propagation (IBP) and CROWN allow to bound a network’s output for a specific set of allowed perturbations around clean input examples. These bounds can be used for adversarial training. The motivation to combine BROWN and IBP stems from the fact that training using IBP bounds usually results in instabilities, while training with CROWN bounds usually leads to over-regularization. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Generalization in Deep Networks: The Role of Distance from Initialization
Nagarajan, Vaishnavh and Kolter, J. Zico
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Nagarajan, Vaishnavh and Kolter, J. Zico
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Nagarajan and Kolter show that neural networks are implicitly regularized by stochastic gradient descent to have small distance from their initialization. This implicit regularization may explain the good generalization performance of over-parameterized neural networks; specifically, more complex models usually generalize better, which contradicts the general trade-off between expressivity and generalization in machine learning. On MNIST, the authors show that the distance of the network’s parameters to the original initialization (as measured using the $L_2$ norm on the flattened parameters) reduces with increasing width, and increases with increasing sample size. Additionally, the distance increases significantly when fitting corrupted labels, which may indicate that memorization requires to travel a larger distance in parameter space. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Batch Normalization is a Cause of Adversarial Vulnerability
Galloway, Angus and Golubeva, Anna and Tanay, Thomas and Moussa, Medhat and Taylor, Graham W.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Galloway, Angus and Golubeva, Anna and Tanay, Thomas and Moussa, Medhat and Taylor, Graham W.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Galloway et al. argue that batch normalization reduces robustness against noise and adversarial examples. On various vision datasets, including SVHN and ImageNet, with popular self-trained and pre-trained models they empirically demonstrate that networks with batch normalization show reduced accuracy on noise and adversarial examples. As noise, they consider Gaussian additive noise as well as different noise types included in the Cifar-C dataset. Similarly, for adversarial examples, they consider $L_\infty$ and $L_2$ PGD and BIM attacks; I refer to the paper for details and hyper parameters. On noise, all networks perform worse with batch normalization, even though batch normalization increases clean accuracy slightly. Against PGD attacks, the provided experiments also suggest that batch normalization reduces robustness; however, the attacks only include 20 iterations and do not manage to reduce the adversarial accuracy to near zero, as is commonly reported. Thus, it is questionable whether batch normalization makes indeed a significant difference regarding adversarial robustness. Finally, the authors argue that replacing batch normalization by weight decay can recover some of the advantage in terms of accuracy and robustness. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
How Can We Be So Dense? The Benefits of Using Highly Sparse Representations
Ahmad, Subutai and Scheinkman, Luiz
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Ahmad, Subutai and Scheinkman, Luiz
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Ahmad and Scheinkman propose a simple sparse layer in order to improve robustness against random noise. Specifically, considering a general linear network layer, i.e.
$\hat{y}^l = W^l y^{l-1} + b^l$ and $y^l = f(\hat{y}^l$
where $f$ is an activation function, the weights are first initialized using a sparse distribution; then, the activation function (commonly ReLU) is replaced by a top-$k$ ReLU version where only the top-$k$ activations are propagated. In experiments, this is shown to improve robustness against random noise on MNIST.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
1 Comments
|
Adversarial Examples Are Not Bugs, They Are Features
Ilyas, Andrew and Santurkar, Shibani and Tsipras, Dimitris and Engstrom, Logan and Tran, Brandon and Madry, Aleksander
- 2019 via Local Bibsonomy
Keywords: adversarial
Ilyas, Andrew and Santurkar, Shibani and Tsipras, Dimitris and Engstrom, Logan and Tran, Brandon and Madry, Aleksander
- 2019 via Local Bibsonomy
Keywords: adversarial
|
[link]
Ilyas et al. present a follow-up work to their paper on the trade-off between accuracy and robustness. Specifically, given a feature $f(x)$ computed from input $x$, the feature is considered predictive if
$\mathbb{E}_{(x,y) \sim \mathcal{D}}[y f(x)] \geq \rho$;
similarly, a predictive feature is robust if
$\mathbb{E}_{(x,y) \sim \mathcal{D}}\left[\inf_{\delta \in \Delta(x)} yf(x + \delta)\right] \geq \gamma$.
This means, a feature is considered robust if the worst-case correlation with the label exceeds some threshold $\gamma$; here the worst-case is considered within a pre-defined set of allowed perturbations $\Delta(x)$ relative to the input $x$. Obviously, there also exist predictive features, which are however not robust according to the above definition. In the paper, Ilyas et al. present two simple algorithms for obtaining adapted datasets which contain only robust or only non-robust features. The main idea of these algorithms is that an adversarially trained model only utilizes robust features, while a standard model utilizes both robust and non-robust features. Based on these datasets, they show that non-robust, predictive features are sufficient to obtain high accuracy; similarly training a normal model on a robust dataset also leads to reasonable accuracy but also increases robustness. Experiments were done on Cifar10. These observations are supported by a theoretical toy dataset consisting of two overlapping Gaussians; I refer to the paper for details.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Bit-Flip Attack: Crushing Neural Network withProgressive Bit Search
Rakin, Adnan Siraj and He, Zhezhi and Fan, Deliang
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Rakin, Adnan Siraj and He, Zhezhi and Fan, Deliang
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Rakin et al. introduce the bit-flip attack aimed to degrade a network’s performance by flipping a few weight bits. On Cifar10 and ImageNet, common architectures such as ResNets or AlexNet are quantized into 8 bits per weight value (or fewer). Then, on a subset of the validation set, gradients with respect to the training loss are computed and in each layer, bits are selected based on their gradient value. Afterwards, the layer which incurs the maximum increase in training loss is selected. This way, a network’s performance can be degraded to chance level with as few as 17 flipped bits (on ImageNet, using AlexNet). Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Benchmarking Deep Learning Hardware and Frameworks: Qualitative Metrics
Wei Dai and Daniel Berleant
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.DC, cs.LG, cs.PF
First published: 2019/07/05 (4 years ago)
Abstract: Previous survey papers offer knowledge of deep learning hardware devices and software frameworks. This paper introduces benchmarking principles, surveys machine learning devices including GPUs, FPGAs, and ASICs, and reviews deep learning software frameworks. It also reviews these technologies with respect to benchmarking from the angles of our 7-metric approach to frameworks and 12-metric approach to hardware platforms. After reading the paper, the audience will understand seven benchmarking principles, generally know that differential characteristics of mainstream AI devices, qualitatively compare deep learning hardware through our 12-metric approach for benchmarking hardware, and read benchmarking results of 16 deep learning frameworks via our 7-metric set for benchmarking frameworks.
more
less
Wei Dai and Daniel Berleant
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.DC, cs.LG, cs.PF
First published: 2019/07/05 (4 years ago)
Abstract: Previous survey papers offer knowledge of deep learning hardware devices and software frameworks. This paper introduces benchmarking principles, surveys machine learning devices including GPUs, FPGAs, and ASICs, and reviews deep learning software frameworks. It also reviews these technologies with respect to benchmarking from the angles of our 7-metric approach to frameworks and 12-metric approach to hardware platforms. After reading the paper, the audience will understand seven benchmarking principles, generally know that differential characteristics of mainstream AI devices, qualitatively compare deep learning hardware through our 12-metric approach for benchmarking hardware, and read benchmarking results of 16 deep learning frameworks via our 7-metric set for benchmarking frameworks.
|
[link]
Benchmarking Deep Learning Hardware and Frameworks: Qualitative Metrics Previous papers on benchmarking deep neural networks offer knowledge of deep learning hardware devices and software frameworks. This paper introduces benchmarking principles, surveys machine learning devices including GPUs, FPGAs, and ASICs, and reviews deep learning software frameworks. It also qualitatively compares these technologies with respect to benchmarking from the angles of our 7-metric approach to deep learning frameworks and 12-metric approach to machine learning hardware platforms. After reading the paper, the audience will understand seven benchmarking principles, generally know that differential characteristics of mainstream artificial intelligence devices, qualitatively compare deep learning hardware through the 12-metric approach for benchmarking neural network hardware, and read benchmarking results of 16 deep learning frameworks via our 7-metric set for benchmarking frameworks. |

The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.NE
First published: 2018/03/09 (6 years ago)
Abstract: Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without compromising accuracy. However, contemporary experience is that the sparse architectures produced by pruning are difficult to train from the start, which would similarly improve training performance. We find that a standard pruning technique naturally uncovers subnetworks whose initializations made them capable of training effectively. Based on these results, we articulate the "lottery ticket hypothesis:" dense, randomly-initialized, feed-forward networks contain subnetworks ("winning tickets") that - when trained in isolation - reach test accuracy comparable to the original network in a similar number of iterations. The winning tickets we find have won the initialization lottery: their connections have initial weights that make training particularly effective. We present an algorithm to identify winning tickets and a series of experiments that support the lottery ticket hypothesis and the importance of these fortuitous initializations. We consistently find winning tickets that are less than 10-20% of the size of several fully-connected and convolutional feed-forward architectures for MNIST and CIFAR10. Above this size, the winning tickets that we find learn faster than the original network and reach higher test accuracy.
more
less
Jonathan Frankle and Michael Carbin
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.NE
First published: 2018/03/09 (6 years ago)
Abstract: Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without compromising accuracy. However, contemporary experience is that the sparse architectures produced by pruning are difficult to train from the start, which would similarly improve training performance. We find that a standard pruning technique naturally uncovers subnetworks whose initializations made them capable of training effectively. Based on these results, we articulate the "lottery ticket hypothesis:" dense, randomly-initialized, feed-forward networks contain subnetworks ("winning tickets") that - when trained in isolation - reach test accuracy comparable to the original network in a similar number of iterations. The winning tickets we find have won the initialization lottery: their connections have initial weights that make training particularly effective. We present an algorithm to identify winning tickets and a series of experiments that support the lottery ticket hypothesis and the importance of these fortuitous initializations. We consistently find winning tickets that are less than 10-20% of the size of several fully-connected and convolutional feed-forward architectures for MNIST and CIFAR10. Above this size, the winning tickets that we find learn faster than the original network and reach higher test accuracy.
|
[link]
Frankle and Carbin discover so-called winning tickets, subset of weights of a neural network that are sufficient to obtain state-of-the-art accuracy. The lottery hypothesis states that dense networks contain subnetworks – the winning tickets – that can reach the same accuracy when trained in isolation, from scratch. The key insight is that these subnetworks seem to have received optimal initialization. Then, given a complex trained network for, e.g., Cifar, weights are pruned based on their absolute value – i.e., weights with small absolute value are pruned first. The remaining network is trained from scratch using the original initialization and reaches competitive performance using less than 10% of the original weights. As soon as the subnetwork is re-initialized, these results cannot be reproduced though. This suggests that these subnetworks obtained some sort of “optimal” initialization for learning. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Certified Adversarial Robustness via Randomized Smoothing
Jeremy M Cohen and Elan Rosenfeld and J. Zico Kolter
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/02/08 (5 years ago)
Abstract: We show how to turn any classifier that classifies well under Gaussian noise into a new classifier that is certifiably robust to adversarial perturbations under the $\ell_2$ norm. This "randomized smoothing" technique has been proposed recently in the literature, but existing guarantees are loose. We prove a tight robustness guarantee in $\ell_2$ norm for smoothing with Gaussian noise. We use randomized smoothing to obtain an ImageNet classifier with e.g. a certified top-1 accuracy of 49% under adversarial perturbations with $\ell_2$ norm less than 0.5 (=127/255). No certified defense has been shown feasible on ImageNet except for smoothing. On smaller-scale datasets where competing approaches to certified $\ell_2$ robustness are viable, smoothing delivers higher certified accuracies. Our strong empirical results suggest that randomized smoothing is a promising direction for future research into adversarially robust classification. Code and models are available at http://github.com/locuslab/smoothing.
more
less
Jeremy M Cohen and Elan Rosenfeld and J. Zico Kolter
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/02/08 (5 years ago)
Abstract: We show how to turn any classifier that classifies well under Gaussian noise into a new classifier that is certifiably robust to adversarial perturbations under the $\ell_2$ norm. This "randomized smoothing" technique has been proposed recently in the literature, but existing guarantees are loose. We prove a tight robustness guarantee in $\ell_2$ norm for smoothing with Gaussian noise. We use randomized smoothing to obtain an ImageNet classifier with e.g. a certified top-1 accuracy of 49% under adversarial perturbations with $\ell_2$ norm less than 0.5 (=127/255). No certified defense has been shown feasible on ImageNet except for smoothing. On smaller-scale datasets where competing approaches to certified $\ell_2$ robustness are viable, smoothing delivers higher certified accuracies. Our strong empirical results suggest that randomized smoothing is a promising direction for future research into adversarially robust classification. Code and models are available at http://github.com/locuslab/smoothing.
|
[link]
Cohen et al. study robustness bounds of randomized smoothing, a region-based classification scheme where the prediction is averaged over Gaussian samples around the test input. Specifically, given a test input, the predicted class is the class whose decision region has the largest overlap with a normal distribution of pre-defined variance. The intuition of this approach is that, for small perturbations, the decision regions of classes can’t vary too much. In practice, randomized smoothing is applied using samples. In the paper, Cohen et al. show that this approach conveys robustness against radii R depending on the confidence difference between the actual class and the “runner-up” class. In practice, the radii also depend on the number of samples used. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
The Limitations of Adversarial Training and the Blind-Spot Attack
Zhang, Huan and Chen, Hongge and Song, Zhao and Boning, Duane S. and Dhillon, Inderjit S. and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Zhang, Huan and Chen, Hongge and Song, Zhao and Boning, Duane S. and Dhillon, Inderjit S. and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Zhang et al. search for “blind spots” in the data distribution and show that blind spot test examples can be used to find adversarial examples easily. On MNIST, the data distribution is approximated using kernel density estimation were the distance metric is computed in dimensionality-reduced feature space (of an adversarially trained model). For dimensionality reduction, t-SNE is used. Blind spots are found by slightly shifting pixels or changing the gray value of the background. Based on these blind spots, adversarial examples can easily be found for MNIST and Fashion-MNIST. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Towards Interpretable Deep Neural Networks by Leveraging Adversarial Examples
Dong, Yinpeng and Bao, Fan and Su, Hang and Zhu, Jun
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Dong, Yinpeng and Bao, Fan and Su, Hang and Zhu, Jun
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Dong et al. study interpretability in the context of adversarial examples and propose a variant of adversarial training to improve interpretability. First the authors argue that neurons do not preserve their interpretability on adversarial examples; e.g., neurons corresponding to high-level concepts such as “bird” or “dog” do not fire consistently on adversarial examples. This result is also validated experimentally, by considering deep representations at different layers. To improve interpretability, the authors propose adversarial training with an additional regularizer enforcing similar features on true and adversarial training examples. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Initialization - when your network performs the way I want
Grosse, Kathrin and Trost, Thomas Alexander and Mosbach, Marius and Backes, Michael and Klakow, Dietrich
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Grosse, Kathrin and Trost, Thomas Alexander and Mosbach, Marius and Backes, Michael and Klakow, Dietrich
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Grosse et al. propose an adversarial attack on a deep neural network’s weight initialization in order to damage accuracy or convergence. An attacker with access to the used deep learning library is assumed. The attack has no knowledge about the training data or the addressed task; however, the attacker has knowledge (through the library’s API) about the network architecture and its initialization. The goal of the attacker is to permutate the initialized weights, without being detected, in order to hinder training. In particular, as illustrated in Figure 1 for two fully connected layers described by
$y(x) = \text{ReLU}(B \text{ReLU}(Ax + a) + b)$,
the attack tries to force a large part of neurons to have zero activation from the very beginning. This attack assumes non-negative input, e.g., images in $[0,1]$ as well as ReLU activations in order to zero-out the selected neurons. In Figure 1, this is achieved by permutating the weights in order to concentrate its negative values in a specific part of the weight matrix. Consecutive application of both weight matrices results in most activations to be zero. This will hinder training significantly as no gradients are available, while keeping the statistics of the weights (e.g., mean and variance) unchanged. A similar strategy can be applied to consecutive convolutional layers, as discussed in detail in the paper. Additionally, by slightly shifting the weights in each weight matrix allows to control the rough number of neurons that receives zero activations; this is intended to have control over the “degree” of damage, i.e. whether the network should diverge or just achieve lower accuracy. In experiments, the authors show that the proposed attacks on weight initialization allow to force training to diverge or reach lower accuracy. However, in the majority of cases, training diverges, which makes the attack less stealthy, i.e., easier to detect by the attacked user.
https://i.imgur.com/wqwhYFL.png
https://i.imgur.com/2zZMOYW.png
Figure 1: Illustration of the idea of the proposd attacks on two fully connected layers as described in the text. The color coding illustrates large, usually positive, weight values in black and small, often negative, weight values in light gray.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Robustness of Generalized Learning Vector Quantization Models against Adversarial Attacks
Sascha Saralajew and Lars Holdijk and Maike Rees and Thomas Villmann
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, stat.ML
First published: 2019/02/01 (5 years ago)
Abstract: Adversarial attacks and the development of (deep) neural networks robust against them are currently two widely researched topics. The robustness of Learning Vector Quantization (LVQ) models against adversarial attacks has however not yet been studied to the same extent. We therefore present an extensive evaluation of three LVQ models: Generalized LVQ, Generalized Matrix LVQ and Generalized Tangent LVQ. The evaluation suggests that both Generalized LVQ and Generalized Tangent LVQ have a high base robustness, on par with the current state-of-the-art in robust neural network methods. In contrast to this, Generalized Matrix LVQ shows a high susceptibility to adversarial attacks, scoring consistently behind all other models. Additionally, our numerical evaluation indicates that increasing the number of prototypes per class improves the robustness of the models.
more
less
Sascha Saralajew and Lars Holdijk and Maike Rees and Thomas Villmann
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, stat.ML
First published: 2019/02/01 (5 years ago)
Abstract: Adversarial attacks and the development of (deep) neural networks robust against them are currently two widely researched topics. The robustness of Learning Vector Quantization (LVQ) models against adversarial attacks has however not yet been studied to the same extent. We therefore present an extensive evaluation of three LVQ models: Generalized LVQ, Generalized Matrix LVQ and Generalized Tangent LVQ. The evaluation suggests that both Generalized LVQ and Generalized Tangent LVQ have a high base robustness, on par with the current state-of-the-art in robust neural network methods. In contrast to this, Generalized Matrix LVQ shows a high susceptibility to adversarial attacks, scoring consistently behind all other models. Additionally, our numerical evaluation indicates that increasing the number of prototypes per class improves the robustness of the models.
|
[link]
Saralajew et al. evaluate learning vector quantization (LVQ) approaches regarding their robustness against adversarial examples. In particular, they consider generalized LVQ where examples are classified based on their distance to the closest prototype of the same class and the closest prototype of another class. The prototypes are learned during training; I refer to the paper for details. Robustness is compared to adversarial training and evaluated against several attacks, including FGSM, DeepFool and Boundary – both white-box and black-box attacks. Regarding $L_\infty$, LVQ usually demonstrates poorer performance than adversarial training. Still, robustness seems to be higher than normally trained deep neural networks. One of the main explanations of the authors is that LVQ follows a max-margin approach; this max-margin idea seems to favor robust models. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Large-Batch Training for LSTM and Beyond
You, Yang and Hseu, Jonathan and Ying, Chris and Demmel, James and Keutzer, Kurt and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
You, Yang and Hseu, Jonathan and Ying, Chris and Demmel, James and Keutzer, Kurt and Hsieh, Cho-Jui
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Often the best learning rate for a DNN is sensitive to batch size and hence need significant tuning while scaling batch sizes to large scale training. Theory suggests that when you scale the batch size by a factor of $k$ (in the case of multi-GPU training), the learning rate should be scaled by $\sqrt{k}$ to keep the variance of the gradient estimator constant (remember the variance of an estimator is inversely proportional to the sample size?). But in practice, often linear learning rate scaling works better (i.e. scale learning rate by $k$), with a gradual warmup scheme.
This paper proposes a slight modification to the existing learning rate scheduling scheme called LEGW (Linear Epoch Gradual Warmup) which helps us in bridging the gap between theory and practice of large batch training.
The authors notice that in order to make square root scaling work well in practice, one should also scale the warmup period (in terms of epochs) by a factor of $k$. In other words, if you consider learning rate as a function of time period in terms of epochs, scale the periodicity of the function by $k$, while scaling the amplitude of the function by $\sqrt{k}$, when the batch size is scaled by $k$. The authors consider various learning rate scheduling schemes like exponential decay, polynomial decay and multi-step LR decay and find that square root scaling with LEGW scheme often leads to little to no loss in performance while scaling the batch sizes. In fact, one can use SGD with LEGW with no tuning and make it work as good as Adam.
Thus with this approach, one can tune the learning rate for a small batch size and extrapolate it to larger batch sizes while making use of parallel hardwares.
|

A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms
Yoshua Bengio and Tristan Deleu and Nasim Rahaman and Rosemary Ke and Sébastien Lachapelle and Olexa Bilaniuk and Anirudh Goyal and Christopher Pal
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/01/30 (5 years ago)
Abstract: We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.
more
less
Yoshua Bengio and Tristan Deleu and Nasim Rahaman and Rosemary Ke and Sébastien Lachapelle and Olexa Bilaniuk and Anirudh Goyal and Christopher Pal
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/01/30 (5 years ago)
Abstract: We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.
|
[link]
How can we learn causal relationships that explain data? We can learn from non-stationary distributions. If we experiment with different factorizations of relationships between variables we can observe which ones provide better sample complexity when adapting to distributional shift and therefore are likely to be causal. If we consider the variables A and B we can factor them in two ways: $P(A,B) = P(A)P(B|A)$ representing a causal graph like $A\rightarrow B$ $P(A,B) = P(A|B)P(B)$ representing a causal graph like $A \leftarrow B$ The idea is if we train a model with one of these structures; when adapting to a new shifted distribution of data it will take longer to adapt if the model does not have the correct inductive bias. For example let's say that the true relationship is $A$=Raining causes $B$=Open Umbrella (and not vice-versa). Changing the marginal probability of Raining (say because the weather changed) does not change the mechanism that relates $A$ and $B$ (captured by $P(B|A)$), but will have an impact on the marginal $P(B)$. So after this distributional shift the function that modeled $P(B|A)$ will not need to change because the relationship is the same. Only the function that modeled $P(A)$ will need to change. Under the incorrect factorization $P(B)P(A|B)$, adaptation to the change will be slow because both $P(B)$ and $P(A|B)$ need to be modified to account for the change in $P(A)$ (due to Bayes rule). Here a difference in sample complexity can be observed when modeling the joint of the shifted distribution. $B\rightarrow A$ takes longer to adapt: https://i.imgur.com/B9FEmA7.png Here the idea is that sample complexity when adapting to a new distribution of data is a heuristic to inform us which causal graph inductive bias is correct. Experimentally this works and they also observe that when models have more capacity it seems that the difference between the models grows. This summary was written with the help of Yoshua Bengio. |

Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Yunpeng Chen and Haoqi Fan and Bing Xu and Zhicheng Yan and Yannis Kalantidis and Marcus Rohrbach and Shuicheng Yan and Jiashi Feng
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV
First published: 2019/04/10 (5 years ago)
Abstract: In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
more
less
Yunpeng Chen and Haoqi Fan and Bing Xu and Zhicheng Yan and Yannis Kalantidis and Marcus Rohrbach and Shuicheng Yan and Jiashi Feng
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV
First published: 2019/04/10 (5 years ago)
Abstract: In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
|
[link]
Natural images can be decomposed in frequencies, higher frequencies contain small changes and details, while lower frequencies contain the global structure. We can see an example in this image:  Each filter of a convolutional layer focuses on different frequencies of the image. This paper proposes a way to group them explicitly into high and low frequency filters. To do that, the low frequency group is reduced spatially by 2 in all dimensions (which they define as an octave), before applying the convolution. The spatial reduction, which is a pooling operation, makes sense as it is a low pass filter, small details are discarded but the global structure is kept. More concretely, the layer takes as input two groups of feature maps, one with a higher resolution than the other. The output is also two groups of feature maps, separated as high/low frequencies. Information is exchanged between the two groups by pooling or upsampling as needed, and as is shown on this image:  The proportion of high and low frequency feature maps is controlled through a single parameter, and through testing the authors found that having around 25% of low frequency features gives the best performance. One important fact about this layer is that it can simply be used as replacement for a standard convolutional layer, and thus does not require other changes to the architecture. They test on various ResNets, DenseNets and MobileNets. In terms of tasks, they get performance near state-of-the-art on [ImageNet top-1](https://paperswithcode.com/sota/image-classification-on-imagenet) and top-5. So why use this octave convolution? Because it reduces the amount of memory and computation required by the network. # Comments - I would have liked to see more groups of varying frequencies. Since an octave is a spatial reduction of 2^n, the authors could do the same with n > 1. I expect this will be addressed in future work. - While the results are not quite SOTA, octave convolutions seem compatible with EfficientNet, and I expect this would improve the performance of both. - Since each octave convolution layer outputs a multi-scale representation of the input, doesn't that mean that pooling becomes less necessary in a network? If so, octave convolutions would give better performances on a new architecture optimized for them. Code: [Official](https://github.com/facebookresearch/OctConv), [all implementations](https://paperswithcode.com/paper/drop-an-octave-reducing-spatial-redundancy-in) |

Hierarchical Autoregressive Image Models with Auxiliary Decoders
Fauw, Jeffrey De and Dieleman, Sander and Simonyan, Karen
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Fauw, Jeffrey De and Dieleman, Sander and Simonyan, Karen
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Current work in image generation (and generative models more broadly) can be split into two broad categories: implicit models, and likelihood-based models. Implicit models is a categorically that predominantly creates GANs, and which learns how to put pixels in the right places without actually learning a joint probability model over pixels. This is a detriment for applications where you do actually want to be able to calculate probabilities for particular images, in addition to simply sampling new images from your model. Within the class of explicit probability models, the auto-encoder and the autoregressive model are the two most central and well-established. An auto-encoder works by compressing information about an image into a central lower-dimensional “bottleneck” code, and then trying to reconstruct the original image using the information contained in the code. This structure works well for capturing global structure, but is generally weaker at local structure, because by convention images are generated through stacked convolutional layers, where each pixel in the image is sampled separately, albeit conditioned on the same latent state (the value of the layer below). This is in contrast to an auto-regressive decoder, where you apply some ordering to the pixels, and then sample them in sequence: starting the prior over the first pixel, and then the second conditional on the first, and so on. In this setup, instead of simply expecting your neighboring pixels to coordinate with you because you share latent state, the model actually has visibility into the particular pixel sampled at the prior step, and has the ability to condition on that. This leads to higher-precision generation of local pixel structure with these models . If you want a model that can get the best of all of these worlds - high-local precision, good global structure, and the ability to calculate probabilities - a sensible approach might be to combine the two: to learn a global-compressed code using an autoencoder, and then, conditioning on that autoencoder code as well as the last sampled values, generate pixels using an autoregressive decoder. However, in practice, this has proved tricky. At a high level, this is because the two systems are hard to balance with one another, and different kinds of imbalance lead to different failure modes. If you try to constrain the expression power of your global code too much, your model will just give up on having global information, and just condition pixels on surrounding (past-sampled) pixels. But, by contrast, if you don’t limit the capacity of the code, then the model puts even very local information into the code and ignores the autoregressive part of the model, which brings it away from playing our desired role as global specifier of content. This paper suggests a new combination approach, whereby we jointly train an encoder and autoregressive decoder, but instead of training the encoder on the training signal produced by that decoder, we train it on the training signal we would have gotten from decoding the code into pixels using a simpler decoder, like a feedforward network. The autoregressive network trains on the codes from the encoder as the encoder trains, but it doesn’t actually pass any signal back to it. Basically, we’re training our global code to believe it’s working with a less competent decoder, and then substituting our autoregressive decoder in during testing. https://i.imgur.com/d2vF2IQ.png Some additional technical notes: - Instead of using a more traditional continuous-valued bottleneck code, this paper uses the VQ-VAE tactic of discretizing code values, to be able to more easily control code capacity. This essentially amounts to generating code vectors as normal, clustering them, passing their cluster medians forward, and then ignoring the fact that none of this is differentiable and passing back gradients with respect to the median - For their auxiliary decoders, the authors use both a simple feedforward network, and also a more complicated network, where the model needs to guess a pixel, using only the pixel values outside of a window of size of that pixel. The goal of the latter variant is to experiment with a decoder that can’t use local information, and could only use global |
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena Voita and David Talbot and Fedor Moiseev and Rico Sennrich and Ivan Titov
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CL
First published: 2019/05/23 (4 years ago)
Abstract: Multi-head self-attention is a key component of the Transformer, a state-of-the-art architecture for neural machine translation. In this work we evaluate the contribution made by individual attention heads in the encoder to the overall performance of the model and analyze the roles played by them. We find that the most important and confident heads play consistent and often linguistically-interpretable roles. When pruning heads using a method based on stochastic gates and a differentiable relaxation of the L0 penalty, we observe that specialized heads are last to be pruned. Our novel pruning method removes the vast majority of heads without seriously affecting performance. For example, on the English-Russian WMT dataset, pruning 38 out of 48 encoder heads results in a drop of only 0.15 BLEU.
more
less
Elena Voita and David Talbot and Fedor Moiseev and Rico Sennrich and Ivan Titov
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CL
First published: 2019/05/23 (4 years ago)
Abstract: Multi-head self-attention is a key component of the Transformer, a state-of-the-art architecture for neural machine translation. In this work we evaluate the contribution made by individual attention heads in the encoder to the overall performance of the model and analyze the roles played by them. We find that the most important and confident heads play consistent and often linguistically-interpretable roles. When pruning heads using a method based on stochastic gates and a differentiable relaxation of the L0 penalty, we observe that specialized heads are last to be pruned. Our novel pruning method removes the vast majority of heads without seriously affecting performance. For example, on the English-Russian WMT dataset, pruning 38 out of 48 encoder heads results in a drop of only 0.15 BLEU.
|
[link]
In the two years since it’s been introduced, the Transformer architecture, which uses multi-headed self-attention in lieu of recurrent models to consolidate information about input and output sequences, has more or less taken the world of language processing and understanding by storm. It has become the default choice for language for problems like translation and questioning answering, and was the foundation of OpenAI’s massive language-model-trained GPT. In this context, I really appreciate this paper’s work to try to build our collective intuitions about the structure, specifically by trying to understand how the multiple heads that make up the aforementioned multi-head attention divide up importance and specialize function. As a quick orientation, attention works by projecting each value in the sequence into query, key, and value vectors. Then, each element in the sequence creates its next-layer value by calculating a function of query and key (typically dot product) and putting that in a softmax against the query results with every other element. This weighting distribution is then used as the weights of a weighted average, combining the values together. By default this is a single operation, with a single set of projection matrices, but in the Transformer approach, they use multi-headed attention, which simply means that they learn independent parameters for multiple independent attention “filters”, each of which can then notionally specialize to pull in and prioritize a certain kind of information. https://i.imgur.com/yuC91Ja.png The high level theses of this paper are: - Among attention heads, there’s a core of the most crucial and important ones, and then a long tail of heads that can be pruned (or, have their weight in the concatenation of all attention heads brought to nearly zero) and have a small effect on performance - It’s possible and useful to divide up the heads according to the kinds of other tokens that it is most consistently pulling information from. The authors identify three: positional, syntactic, and rare. Positional heads consistently (>90% of the time) put their maximum attention weight on the same position relative to the query word. Syntactic heads are those that recurringly in the same grammatical relation to the query, the subject to its verb, or the adjective to its noun, for example. Rare words is not a frequently used head pattern, but it is a very valuable head within the first layer, and will consistently put its highest weight on the lowest-frequency word in a given sentence. An interesting side note here is that the authors tried at multiple stages in pruning to retrain a network using only the connections between unpruned heads, and restarting from scratch. However, in a effect reminiscent of the Lottery Ticket Thesis, retraining from scratch cannot get quite the same performance. |
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Egor Zakharov and Aliaksandra Shysheya and Egor Burkov and Victor Lempitsky
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV, cs.GR, cs.LG
First published: 2019/05/20 (4 years ago)
Abstract: Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability. It performs lengthy meta-learning on a large dataset of videos, and after that is able to frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators. Crucially, the system is able to initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach is able to learn highly realistic and personalized talking head models of new people and even portrait paintings.
more
less
Egor Zakharov and Aliaksandra Shysheya and Egor Burkov and Victor Lempitsky
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV, cs.GR, cs.LG
First published: 2019/05/20 (4 years ago)
Abstract: Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability. It performs lengthy meta-learning on a large dataset of videos, and after that is able to frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators. Crucially, the system is able to initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach is able to learn highly realistic and personalized talking head models of new people and even portrait paintings.
|
[link]
https://i.imgur.com/JJFljWo.png This paper follows in a recent tradition of results out of Samsung: in the wake of StyleGAN’s very impressive generated images, it uses a lot of similar architectural elements, combined with meta-learning and a new discriminator framework, to generate convincing “talking head” animations based on a small number of frames of a person’s face. Previously, models that generated artificial face videos could only do so by training by a large number of frames of each individual speaker that they wanted to simulate. This system instead is able to generate video in a few-shot way: where they only need one or two frames of a new speaker to do convincing generation. The structure of talking head video generation as a problem relies on the idea of “landmarks,” explicit parametrization of where the nose, the eyes, the lips, the head, are oriented in a given shot. The model is trained to be able to generate frames of a specified person (based on an input frame), and in a specific pose (based on an input landmark set). While the visual quality of the simulated video generated here is quite stunning, the most centrally impressive fact about this paper is that generation was only conditioned on a few frames of each target person. This is accomplished through a combination of meta-learning (as an overall training procedure/regime) and adaptive instance normalization, a way of dynamically parametrizing models that was earlier used in a StyleGAN paper (also out of the Samsung lab). Meta-learning works by doing simulated few-shot training iterations, where a model is trained for a small number of steps on a given “task” (where here a task is a given target face), and then optimized on the meta-level to be able to get good test set error rates across many such target faces. https://i.imgur.com/RIkO1am.png The mechanics of how this meta-learning approach actually work are quite interesting: largely a new application of existing techniques, but with some extensions and innovations worked in. - A convolutional model produces an embedding given an input image and a pose. An average embedding is calculated by averaging over different frames, with the hopes of capturing information about the video, in a pose-independent way. This embedding, along with a goal set of landmarks (i.e. the desired facial expression of your simulation) is used to parametrize the generator, which is then asked to determine whether the generated image looks like it came from the sequence belonging to the target face, and looks like it corresponds to the target pose - Adaptive instance normalization works by having certain parameters of the network (typically, per the name, post-normalization rescaling values) that are dependent on the properties of some input data instance. This works by training a network to produce an embedding vector of the image, and then multiplying that embedding by per-layer, per-filter projection matrices to obtain new parameters. This is in particular a reasonable thing to do in the context of conditional GANs, where you want to have parameters of your generator be conditioned on the content of the image you’re trying to simulate - This model structure gives you a natural way to do few-shot generation: you can train your embedding network, your generator, and your projection matrices over a large dataset, where they’ve hopefully learned how to compress information from any given target image, and generate convincing frames based on it, so that you can just pass in your new target image, have it transformed into an embedding, and have it contain information the rest of the network can work with - This model uses a relatively new (~mid 2018) formulation of a conditional GAN, called the projection discriminator. I don’t have time to fully explain this here, but at a high level, it frames the problem of a discriminator determining whether a generated image corresponds to a given conditioning class by projecting both the class and the image into vectors, and calculating a similarity-esque dot product. - During few-shot application of this model, it can get impressively good performance without even training on the new target face at all, simply by projecting the target face into an embedding, and updating the target-specific network parameters that way. However, they do get better performance if they fine-tune to a specific person, which they do by treating the embedding-projection parameters as an initialization, and then taking a few steps of gradient descent from there |
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CL
First published: 2019/05/19 (4 years ago)
Abstract: Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.
more
less
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CL
First published: 2019/05/19 (4 years ago)
Abstract: Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.
|
[link]
[Machine learning is a nuanced, complicated, intellectually serious topic...but sometimes it’s refreshing to let ourselves be a bit less serious, especially when it’s accompanied by clear, cogent writing on a topic. This particular is a particularly delightful example of good-natured silliness - from the dataset name HellaSwag to figures containing cartoons of BERT and ELMO representing language models - combined with interesting science.] https://i.imgur.com/CoSeh51.png This paper tackles the problem of natural language comprehension, which asks: okay, our models can generate plausible looking text, but do they actually exhibit what we would consider true understanding of language? One natural structure of task for this is to take questions or “contexts”, and, given a set of possible endings or completion, pick the correct one. Positive examples are relatively easy to come by: adjacent video captions and question/answer pairs from WikiHow are two datasets used in this paper. However, it’s more difficult to come up with *negative* examples. Even though our incorrect endings won’t be a meaningful continuation of the sentence, we want them to be “close enough” that we can feel comfortable attributing a model’s ability to pick the correct answer as evidence of some meaningful kind of comprehension. As an obvious failure mode, if the alternative multiple choice options were all the same word repeated ten times, that would be recognizable as being not real language, and it would be easy for a model to select the answer with the distributional statistics of real language, but it wouldn’t prove much. Typically failure modes aren’t this egregious, but the overall intuition still holds, and will inform the rest of the paper: your ability to test comprehension on a given dataset is a function of how contextually-relevant and realistic your negative examples are. Previous work (by many of the same authors as are on this paper), proposed a technique called Adversarial Filtering to try to solve this problem. In Adversarial Filtering, a generative language model is used to generate possible many endings conditioned on the input context, to be used as negative examples. Then, a discriminator is trained to predict the correct ending given the context. The generated samples that the discriminator had the highest confidence classifying as negative are deemed to be not challenging enough comparisons, and they’re thrown out and replaced with others from our pool of initially-generated samples. Eventually, once we’ve iterated through this process, we have a dataset with hopefully realistic negative examples. The negative examples are then given to humans to ensure none of them are conceptually meaningful actual endings to the sentence. The dataset released by the earlier paper, which used as it’s generator a relatively simple LSTM model, was called Swag. However, the authors came to notice that the performance of new language models (most centrally BERT) on this dataset might not be quite what it appears: its success rate of 86% only goes down to 76% if you don’t give the classifier access to the input context, which means it can get 76% (off of a random baseline of 25%, with 4 options) simply by evaluating which endings are coherent as standalone bits of natural language, without actually having to understand or even see the context. Also, shuffling the words in the words in the possible endings had a similarly small effect: the authors are able to get BERT to perform at 60% accuracy on the SWAG dataset with no context, and with shuffled words in the possible answers, meaning it’s purely selecting based on the distribution of words in the answer, rather than on the meaningfully-ordered sequence of words. https://i.imgur.com/f6vqJWT.png The authors overall conclusion with this is: this adversarial filtering method is only as good as the generator, and, more specifically, the training dynamic between the generator that produces candidate endings, and the discriminator that filters them. If the generator is too weak, the negative examples can be easily detected as fake by a stronger model, but if the generator is too strong, then the discriminator can’t get good enough to usefully contribute by weeding samples out. They demonstrate this by creating a new version of Swag, which they call HellaSwag (for the expected acronym-optimization reasons), with a GPT generator rather than the simpler one used before: on this new dataset, all existing models get relatively poor results (30-40% performance). However, the authors’ overall point wasn’t “we’ve solved it, this new dataset is the end of the line,” but rather a call in the future to be wary, and generally aware that with benchmarks like these, especially with generated negative examples, it’s going to be a constantly moving target as generation systems get better. |
Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
Zhou, Hattie and Lan, Janice and Liu, Rosanne and Yosinski, Jason
- 2019 via Local Bibsonomy
Keywords: pruning, nas
Zhou, Hattie and Lan, Janice and Liu, Rosanne and Yosinski, Jason
- 2019 via Local Bibsonomy
Keywords: pruning, nas
|
[link]
The Lottery Ticket Hypothesis is the idea that you can train a deep network, set all but a small percentage of its high-magnitude weights to zero, and retrain the network using the connection topology of the remaining weights, but only if you re-initialize the unpruned weights to the the values they had at the beginning of the first training. This suggests that part of the value of training such big networks is not that we need that many parameters to use their expressive capacity, but that we need many “draws” from the weight and topology distribution to find initial weight patterns that are well-disposed for learning. This paper out of Uber is a refreshingly exploratory experimental work that tries to understand the contours and contingencies of this effect. Their findings included: - The pruning criteria used in the original paper, where weights are kept according to which have highest final magnitude, works well. However, an alternate criteria, where you keep the weights that have increased the most in magnitude, works just as well and sometimes better. This makes a decent amount of sense, since it seems like we’re using magnitude as a signal of “did this weight come to play a meaningful role during training,” and so weights whose influence increased during training fall in that category, regardless of their starting point https://i.imgur.com/wTkNBod.png - The authors’ next question was: other than just re-initialize weights to their initial values, are there other things we can do that can capture all or part of the performance effect? The answer seems to be yes; they found that the most important thing seems to be keeping the sign of the weights aligned with what it was at its starting point. As long as you do that, redrawing initial weights (but giving them the right sign), or re-setting weights to a correctly signed constant value, both work nearly as well as the actual starting values https://i.imgur.com/JeujUr3.png - Turning instead to the weights on the pruning chopping block, the authors find that, instead of just zero-ing out all pruned weights, they can get even better performance if they zero the weights that moved towards zero during training, and re-initialize (but freeze) the weights that moved away from zero during training. The logic of the paper is “if the weight was trying to move to zero, bring it to zero, otherwise reinitialize it”. This performance remains high at even lower levels of training than does the initial zero-masking result - Finally, the authors found that just by performing the masking (i.e. keeping only weights with large final values), bringing those back to their values, and zeroing out the rest, *and not training at all*, they were able to get 40% test accuracy on MNIST, much better than chance. If they masked according to “large weights that kept the same sign during training,” they could get a pretty incredible 80% test accuracy on MNIST. Way below even simple trained models, but, again, this model wasn’t *trained*, and the only information about the data came in the form of a binary weight mask This paper doesn’t really try to come up with explanations that wrap all of these results up neatly with a bow, and I really respect that. I think it’s good for ML research culture for people to feel an affordance to just run a lot of targeted experiments aimed at explanation, and publish the results even if they don’t quite make sense yet. I feel like on this problem (and to some extent in machine learning generally), we’re the blind men each grabbing at one part of an elephant, trying to describe the whole. Hopefully, papers like this can bring us closer to understanding strange quirks of optimization like this one |
Meta-learners' learning dynamics are unlike learners'
Neil C. Rabinowitz
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2019/05/03 (4 years ago)
Abstract: Meta-learning is a tool that allows us to build sample-efficient learning systems. Here we show that, once meta-trained, LSTM Meta-Learners aren't just faster learners than their sample-inefficient deep learning (DL) and reinforcement learning (RL) brethren, but that they actually pursue fundamentally different learning trajectories. We study their learning dynamics on three sets of structured tasks for which the corresponding learning dynamics of DL and RL systems have been previously described: linear regression (Saxe et al., 2013), nonlinear regression (Rahaman et al., 2018; Xu et al., 2018), and contextual bandits (Schaul et al., 2019). In each case, while sample-inefficient DL and RL Learners uncover the task structure in a staggered manner, meta-trained LSTM Meta-Learners uncover almost all task structure concurrently, congruent with the patterns expected from Bayes-optimal inference algorithms. This has implications for research areas wherever the learning behaviour itself is of interest, such as safety, curriculum design, and human-in-the-loop machine learning.
more
less
Neil C. Rabinowitz
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2019/05/03 (4 years ago)
Abstract: Meta-learning is a tool that allows us to build sample-efficient learning systems. Here we show that, once meta-trained, LSTM Meta-Learners aren't just faster learners than their sample-inefficient deep learning (DL) and reinforcement learning (RL) brethren, but that they actually pursue fundamentally different learning trajectories. We study their learning dynamics on three sets of structured tasks for which the corresponding learning dynamics of DL and RL systems have been previously described: linear regression (Saxe et al., 2013), nonlinear regression (Rahaman et al., 2018; Xu et al., 2018), and contextual bandits (Schaul et al., 2019). In each case, while sample-inefficient DL and RL Learners uncover the task structure in a staggered manner, meta-trained LSTM Meta-Learners uncover almost all task structure concurrently, congruent with the patterns expected from Bayes-optimal inference algorithms. This has implications for research areas wherever the learning behaviour itself is of interest, such as safety, curriculum design, and human-in-the-loop machine learning.
|
[link]
Meta learning, or, the idea of training models on some distribution of tasks, with the hope that they can then learn more quickly on new tasks because they have “learned how to learn” similar tasks, has become a more central and popular research field in recent years. Although there is a veritable zoo of different techniques (to an amusingly literal degree; there’s an emergent fad of naming new methods after animals), the general idea is: have your inner loop consist of training a model on some task drawn from a distribution over tasks (be that maze learning with different wall configurations, letter identification from different languages, etc), and have the outer loop that updates some structural part of your model be based on improving generalization error on each task within the distribution. It’s been demonstrated that meta-learned systems can in fact learn more quickly (at least when their tasks are “in distribution” relative to the distribution they were trained on, which is an important point to be cognizant of), but this paper is less interested with how much better or faster they’re learning, and more interested in whether there are qualitative differences in the way normal learning systems and meta-trained learning systems go about learning a new task. The author (oddly for DeepMind, which typically goes in for super long author lists, there’s only the one on this paper) goes about this by studying simple learning tasks where it’s easier for us to introspect into what each model is learning over time. https://i.imgur.com/ceycq46.png In the first test, he looks at linear regression in a simple setting: where for each individual “task” data is generated according a known true weight matrix (sampled from a prior over weight matrices), with some noise added in. Given this weight matrix, he takes the singular value decomposition (think: PCA), and so ends up with a factorized representation of the weights, where higher eigenvalues on the factors, or “modes”, represent that those factors represent larger-scale patterns that explain more variance, and lower eigenvalues are smaller scale refinements on top of that. He can apply this same procedure to the weights the network has learned at any given point in training, and compare, to see how close the network is to having correctly captured each of these different modes. When normal learners (starting from a raw initialization) approach the task, they start by matching the large scale (higher eigenvalue) factors of variation, and then over the course of training improve performance on the higher-precision factors. By contrast, meta learners, in addition to learning faster, also learn large scale and small scale modes at the same rate. Similar analysis was performed and similar results found for nonlinear regression, where instead of PCA-style components, the function generating data were decomposed into different Fourier frequencies, and the normal learner learned the broad, low-frequency patterns first, where the meta learner learned them all at the same rate. The paper finds intuition for this by showing that the behavior of the meta learners matches quite well against how a Bayes-optimal learner would update on new data points, in the world where that learner had a prior over the data-generating weights that matched the true generating process. So, under this framing, the process of meta learning is roughly equivalent to your model learning a prior correspondant with the task distribution it was trained on. This is, at a high level, what I think we all sort of thought was happening with meta learning, but it’s pretty neat to see it laid out in a small enough problem where we can actually validate against an analytic model. A bit of a meta (heh) point: I wish this paper had more explanation of why the author chose to use the specific eigenvalue-focused metrics of progression on task learning that he did. They seem reasonable, but I’d have been curious to see an explication of what is captured by these, and what might be captured by alternative metrics of task progress. (A side note: the paper also contained a reinforcement learning experiment, but I both understood that one less well and also feel like it wasn’t really that analogous to the other tests) |
MixMatch: A Holistic Approach to Semi-Supervised Learning
Berthelot, David and Carlini, Nicholas and Goodfellow, Ian and Papernot, Nicolas and Oliver, Avital and Raffel, Colin
- 2019 via Local Bibsonomy
Keywords: semi-supervised-learning
Berthelot, David and Carlini, Nicholas and Goodfellow, Ian and Papernot, Nicolas and Oliver, Avital and Raffel, Colin
- 2019 via Local Bibsonomy
Keywords: semi-supervised-learning
|
[link]
As per the “holistic” in the paper title, the goal of this work is to take a suite of existing work within semi-supervised learning, and combine many of its ideas into one training pipeline that can (with really impressive empirical success) leverage the advantages of those different ideas. The core premise of supervised learning is that, given true-label training signal from a small number of labels, you can leverage large amounts of unsupervised data to improve your model. A central intuition of many of these methods is that, even if you don’t know the class of a given sample, you know it *has* a class, and you can develop a loss by pushing your model to predict the class for an example and a modified or perturbed version of that example, since, if you have a prior belief that that modification should not change your true class label, then your unlabeled data point should have the same class prediction both times. Entropy minimization is built off similar notions: although we don’t know a point’s class, we know it must have one, and so we’d like our model to make a prediction that puts more of its weight on a single class, rather than be spread out, since we know the “correct model” will be a very confident prediction of one class, though we don’t know which it is. These methods will give context and a frame of mind for understanding the techniques merged together into the MixMatch approach. At its very highest level, MixMatch’s goal is to take in a dataset of both labeled and unlabeled data, and produce a training set of inputs, predictions, and (occasionally constructed or modified labels) to calculate a model update loss from. https://i.imgur.com/6lHQqMD.png - First, for each unlabeled example in the dataset, we produce K different augmented versions of that image (by cropping it, rotating it, flipping it, etc). This is in the spirit of the consistency loss literature, where you want your model to make the same prediction across augmentations - Do the same augmentation for each labeled example, but only once per input, rather than k times - Run all of your augmented examples through your model, and take the average of their predictions. This is based on the idea that the average of the predictions will be a lower variance, more stable pseudo-target to pull each of the individual predictions towards. Also in the spirit of making something more shaped like a real label, they undertake a sharpening step, turning down the temperature of the averaged distribution. This seems like it would have the effect of more confidently pulling the original predictions towards a single “best guess” label - At this point, we have a set of augmented labeled data, with a true label, and also a set of augmented unlabeled data, with a label based off of an averaged and sharpened best guess from the model over different modifications. At this point, the pipeline uses something called “MixUp” (on which there is a previous paper, so I won’t dive into it too much here), which takes pairs of data points, calculates a convex combination of the inputs, runs it through the model, and uses as the loss-function target a convex combination of the outputs. So, in the simple binary case, if you have a positive and negatively labeled image and sample a combination parameter of 0.75, you have an image that is 0.75 positive, 0.25 negative, and the new label that you’re calculating cross entropy loss against is 0.75. - MixMatch generates pairs for its MixUp calculation by mixing (heh) labeled and unlabeled data together, and pairing each labeled and unlabeled pair with one observation from the merged set. At this point, we have combined inputs, and we have combined labels, and we can calculate loss between them With all of these methods combined, this method takes the previous benchmark of 38% error, for a CIFAR dataset with only 250 labels, and drops that to 11%, which is a pretty astonishing improvement in error rate. After performing an ablation study, they find that MixUp itself, temperature sharpening, and calculating K>1 augmentations of unlabeled data rather than K=1 are the strongest value-adds; it doesn’t appear like there’s that much difference that comes from mixing between unlabeled and labeled for the MixUp pairs. |
Multitask Soft Option Learning
Igl, Maximilian and Gambardella, Andrew and Nardelli, Nantas and Siddharth, N. and Böhmer, Wendelin and Whiteson, Shimon
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Igl, Maximilian and Gambardella, Andrew and Nardelli, Nantas and Siddharth, N. and Böhmer, Wendelin and Whiteson, Shimon
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper blends concepts from variational inference and hierarchical reinforcement learning, learning skills or “options” out of which master policies can be constructed, in a way that allows for both information transfer across tasks and specialization on any given task. The idea of hierarchical reinforcement learning is that instead of maintaining one single policy distribution (a learned mapping between world-states and actions), a learning system will maintain multiple simpler policies, and then learn a meta-policy for transitioning between these object-level policies. The hope is that this setup leads to both greater transparency and compactness (because skills are compartmentalized), and also greater ability to transfer across tasks (because if skills are granular enough, different combinations of the same skills can be used to solve quite different tasks). The differentiating proposal of this paper is that, instead of learning skills that will be fixed with respect to the master, task-specific policy, we instead learning cross-task priors over different skills, which can then be fine-tuned for a given specific task. Mathematically, this looks like a reward function that is a combination of (1) actual rewards on a trajectory, and (2) the difference in the log probability of a given trajectory under the task-specific posterior and under the prior. https://i.imgur.com/OCvmGSQ.png This framing works in two directions: it allows a general prior to be pulled towards task-specific rewards, to get more specialized value, but it also pulls the per-task skill towards the global prior. This is both a source of transfer knowledge and general regularization, and also an incentive for skills to be relatively consistent across tasks, because consistent posteriors will be more locally clustered around their prior. The paper argues that one advantage of this is a symmetry-breaking effect, avoiding a local minimum where two skills are both being used to solve subtask A, and it would be better for one of them to specialize on subtask B, but in order to do so the local effect would be worse performance of that skill on subtask A, which would be to the overall policy’s detriment because that skill was being actively used to solve that task. Under a prior-driven system, the model would have an incentive to pick one or the other of the options and use that for a given subtask, based on whichever’s prior was closest in trajectory-space. https://i.imgur.com/CeFQ9PZ.png On a mechanical level, this set of priors is divided into a few structural parts: 1) A termination distribution, which chooses whether to keep drawing actions from the skill/subpolicy you’re currently on, or trade it in for a new one. This one has a prior set at a Bernoulli distribution with some learned alpha 2) A skill transition distribution, which chooses, conditional on sampling a “terminate”, which skill to switch to next. This has a prior of a uniform distribution over skills, which incentivizes the learning system to not put all its sampling focus on one policy too early 3) A distribution of actions given a skill choice, which, as mentioned before, has both a cross-task prior and a per-task learned posterior |
Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
Shen, Yikang and Tan, Shawn and Sordoni, Alessandro and Courville, Aaron C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Shen, Yikang and Tan, Shawn and Sordoni, Alessandro and Courville, Aaron C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper came on my radar after winning Best Paper recently at ICLR, and all in all I found it a clever way of engineering a somewhat complicated inductive bias into a differentiable structure. The empirical results weren’t compelling enough to suggest that this structural shift made a regime-change difference in performing, but it does seem to have some consistently stronger ability to do syntactic evaluation across large gaps in sentences. The core premise of this paper is that, while language is to some extent sequence-like, it is in a more fundamental sense tree-like: a recursive structure of modified words, phrases, and clauses, aggregating up to a fully complete sentence. In practical terms, this cashes out to parse trees, labels akin to the sentence diagrams that you or I perhaps did once upon a time in grade school. https://i.imgur.com/GAJP7ji.png Given this, if you want to effectively model language, it might be useful to have a neural network structure explicitly designed to track where you are in the tree. To do this, the authors of this paper use a clever activation function scheme based on the intuition that you can think of jumping between levels of the tree as adding information to the stack of local context, and then removing that information from the stack when you’ve reached the end of some local phrase. In the framework of a LSTM, which has explicit gating mechanisms for both “forgetting” (removing information from cell memory) and input (adding information to the representation within cell memory) this can be understood as forcing a certain structure of input and forgetting, where you have to sequentially “close out” or add nodes as you move up or down the tree. To represent this mathematically, the authors use a new activation function they developed, termed cumulative max or cumax. In the same way that the softmax is a differentiable (i.e. “soft”) version of an argmax, the cumulative max is a softened version of a vector that has zeros up to some switch point k, and ones thereafter. If you had such a vector as your forget mask, then “closing out” a layer in your tree would be equivalent to shifting the index where you switch from 0 to 1 up by one, so that a layer that previously had a “remember” value of 1.0 now is removing its content from the stack. However, since we need to differentiate, this notional 0/1 vector is instead represented as a cumulative sum of a softmax, which can be thought of as the continuous-valued probability that you’ve reached that switch-point by any given point in the vector. Outside of the abstractions of what we’re imagining this cumax function to represent, in a practical sense, it does strictly enforce that you monotonically remember or input more as you move along the vector. This has the practical fact that the network will be biased towards remembering information at one end of the representation vector for longer, meaning it could be a useful inductive bias around storing information that has a more long-term usefulness to it. One advantage that this system has over a previous system that, for example, had each layer of the LSTM operate on a different forgetting-decay timescale, is that this is a soft approximation, so, up to the number of neurons in the representation, the model can dynamically approximate whatever number of tree nodes it likes, rather than being explicitly correspondent with the number of layers. Beyond being a mathematically clever idea, the question of whether it improves performance is a little mixed. It does consistently worse at tasks that require keeping track of short term dependency information, but seems to do better at more long-term tasks, although not in a perfectly consistent or overly dramatic way. My overall read is that this is a neat idea, and I’m interested to see if it gets built on, as well as interested to see later papers that do some introspective work to validate whether the model is actually using this inductive bias in the tree-like way that we’re hoping and imagining it will. |
S$^\mathbf{4}$L: Self-Supervised Semi-Supervised Learning
Xiaohua Zhai and Avital Oliver and Alexander Kolesnikov and Lucas Beyer
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2019/05/09 (4 years ago)
Abstract: This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
more
less
Xiaohua Zhai and Avital Oliver and Alexander Kolesnikov and Lucas Beyer
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2019/05/09 (4 years ago)
Abstract: This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
|
[link]
It’s possible I’m missing something here, but my primary response to reading this paper is just a sense of confusion: that there is an implicit presenting of an approach as novel, when there doesn’t seem to me to be a clear mechanism that is changed from prior work. The premise of this paper is that self-supervised learning techniques (a subcategory of unsupervised learning, where losses are constructed based on reconstruction or perturbation of the original image) should be made into supervised learning by learning on a loss that is a weighted combination of the self-supervised loss and the supervised loss, making the overall method a semi-supervised one. The self-supervision techniques that they identify integrating into their semi-supervised framework are: - Rotation prediction, where an image is rotated to one of four rotation angles, and then a classifier is applied to guess what angle - Exemplar representation invariance, where an imagenet is cropped, mirrored, and color-randomized in order to provide inputs, whose representations are then pushed to be closer to the representation for the unmodified image My confusion is due to the fact that the I know that I’ve read several semi-supervised learning papers that do things of this ilk (insofar as combining unsupervised and supervised losses together) and it seems strange to identify it as a novel contribution. That said, this paper does give an interesting overview of self-supervisation techniques, I found it valuable to read for that purpose. |
On the Pitfalls of Measuring Emergent Communication
Lowe, Ryan and Foerster, Jakob and Boureau, Y.-Lan and Pineau, Joelle and Dauphin, Yann
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Lowe, Ryan and Foerster, Jakob and Boureau, Y.-Lan and Pineau, Joelle and Dauphin, Yann
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Language seems obviously useful to humans in coordinating on complicated tasks, and, the logic goes, you might expect that if you gave agents in a multi-agent RL system some amount of shared interest, and the capacity to communicate, that they would use that communication channel to coordinate actions. This is particularly true in cases where some part of the environment is only visible to one of the agents. A number of papers in the field have set up such scenarios, and argued that meaningful communication strategies developed, mostly in the form of one agent sending a message to signal its planned action to the other agent before both act. This paper tries to tease apart the various quantitative metrics used to evaluate whether informative message are being sent, and tries to explain why they can diverge from each other in unintuitive ways. The experiments in the paper are done in quite simple environments, where there are simple one-shot actions and a payoff matrix, as well as an ability for the agents to send messages before acting. Some metrics identified by the paper are: - Speaker Consistency: There’s high mutual information shown between the message a speaker sends, and what action it takes. Said another way, you could use a speaker’s message to predict their action at a rate higher than random, because it contains information about the action - Heightened reward/task completion under communication: Fairly straightforward, this metric argues that informative communication happened when pairs of agents do better in the presence of communication channels than when they aren’t available - Instantaneous coordination: Measures the mutual information between the message sent by agent A and the action of agent B, in a similar way to Speaker Consistency. This work agrees that it’s important to measure the causal impact of messages on other-agent actions, but argues that instantaneous communication is flawed because the mutual information metric between messages and response actions doesn’t properly condition on the state of the game under whcih the message is being sent. Even if you successfully communicate your planned action to me, the action I actually take in response will be conditioned on my personal payoff matrix, and may average out to seeming unrelated or random if you take an expectation over every possible state the message could be recieved in. Instead, they suggest doing an explicit causal causal approach, where for each configuration of the game (different payoff matrix), they sample different messages, and calculate whether you see messages driving more consistent actions when you condition on other factors in the game. An interesting finding of this paper is that, at least in these simple environments, you’re able to find cases where there is Speaker Consistency (SC; messages that contain information about the speaker’s next action), but no substantial Causal Influence of Communication (CIC). This may seem counterintuitive, since, why would you as an agent send a message containing information about your action, if not because you’re incentivized to communicate with the other agent? It seems like the answer is that it’s possible to have this kind of shared information *on accident,* as a result of the shared infrastructure between the action network and the messaging network. Because both use a shared set of early-layer representations, you end up having one contain information about the other as an incidental fact; if the networks are fully separated with no shared weights, the Speaker Consistency values drop. An important caveat to make here is that this paper isn’t, or at least shouldn’t be, arguing that agents in multi-agent systems don’t actually learn communication. The environments used here are quite simple, and just might not plausibly be difficult enough to incentivize communication. However, it is a fair point that it’s valuable to be precise in what exactly we’re measuring, and test how that squares with what we actually care about in a system, to try to avoid cases like these where we may be liable to be led astray by our belief about how the system *should* be learning, rather than how it actually is |
The Lottery Ticket Hypothesis at Scale
Frankle, Jonathan and Dziugaite, Gintare Karolina and Roy, Daniel M. and Carbin, Michael
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Frankle, Jonathan and Dziugaite, Gintare Karolina and Roy, Daniel M. and Carbin, Michael
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
In 2018, a group including many of the authors of this updated paper argued for a theory of deep neural network optimization that they called the “Lottery Ticket Hypothesis”. It framed itself as a solution to what was otherwise a confusing seeming-contradiction: that you could prune or compress trained networks to contain a small percentage of their trained weights without loss of performance, but also that if you tried to train a comparably small network (comparable to the post-training pruned network) from initialization, you wouldn’t be able to achieve similar performance. They showed that, at least for some set of tasks, you could in fact train a smaller network to equivalent performance, but only if you kept the same connectivity patterns as in the pruned network, and if you re-initialized those neurons to the same values they were initialized at during the initial training. These lucky initialization patterns are the lottery tickets being referred to in the eponymous hypothesis: small subnetworks of well-initialized weights that are set up to be able to train well. This paper assesses whether and under what conditions the LTH holds on larger problems, and does a bit of a meta-analysis over different alternate theories in this space. One such alternate theory, from Liu et al, proposes that, in fact, there is no value in re-initializing to the specific initial values, and that you can actually get away with random initialization if you keep the connectivity patterns of the pruned weights. The “At Scale” paper compares the two methods over a wide range of pruning percentages, and convincingly shows that while random initialization with the same connectivity can perform well up to 80% of the weights being removed, after 80%, the performance of the random initialization drops, whereas the performance of the “winning ticket” approach remains comparable with full network training up to 99% of the weights being pruned. This seems to provide support for the theory that there is value in re-initializing the weights to how they were, especially when you prune to very small subnetworks. https://i.imgur.com/9O2aAIT.png The core of the current paper focuses on a difficulty in the original LTH paper: that the procedure of iterative pruning (train, then prune some weights, then train again) wasn’t able to reliably find “winning tickets” for deep networks of the type needed to solve ImageNet or CIFAR. To be precise, re-initializing pruned networks to their original values did no better than initializing them randomly in these networks. In order to actually get these winning tickets to perform well, the original authors had to do a somewhat arcane process of of starting the learning rate very small and scaling it up, called “warmup”. Neither paper gave a clear intuition as to why this would be the case, but the updated paper found that they could avoid the need for this approach if, instead of re-initializing weights to their original value, they set them to the values they were at after some small number of iterations into training. They justify this by showing that performance under this new initialization is related to something they call “stability to pruning,” which measures how close the learned weights after re-initialization are to the original learned weights in the full model training. And, while the weights of deeper networks are unstable (by this metric) when first initialized, they become stable fairly early on. I was a little confused by this framing, since it seemed fairly tautological to me, since you’re using “how stably close are the weights to the original weights” as a way to explain “when can you recover performance comparable to original performance.” This was framed as being a mechanistic explanation of why you can see a lottery ticket phenomenon to some extent, but only if you do a “late reset” to several iterations after initialization, but it didn’t feel quite mechanistically satisfying enough to me. That said, I think this is overall an intriguing idea, and I’d love to see more papers discuss it. In particular, I’d love to read more qualitative analysis about whether there are any notable patterns shared by “winning tickets”. |
Generating Long Sequences with Sparse Transformers
Child, Rewon and Gray, Scott and Radford, Alec and Sutskever, Ilya
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Child, Rewon and Gray, Scott and Radford, Alec and Sutskever, Ilya
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
The Transformer, a somewhat confusingly-named model structure that uses attention mechanisms to aggregate information for understanding or generating data, has been having a real moment in the last year or so, with GPT-2 being only the most well-publicized tip of that iceberg. It has lots of advantages: the obvious attractions of strong performance, as well as the ability to train in parallel across parts of a sequence, which RNNs can’t do because of the need to build up and maintain state. However, a problematic fact about the Transformer approach is how it scales to large sequences of input data. Because attention is based on performing pairwise queries between each point in the data sequence and each other point, to allow for aggregation of information from places throughout the sequence, it scales as O(N^2), because every new element in the sequence needs to be queried by N other ones. This makes it resource-intensive to run transformer models on large architectures. The Sparse Transformer design proposed in this OpenAI paper tries to cut down on this resource cost by loosening the requirement that, in every attention operation, each element directly pulls information from every other element. In this new system, each point doesn’t get information about each other point in a single operation, but, having two operations such limited operations being chained in a row provides that global visibility. This is done in one of two ways. (1) The first, called the “strided” version, performs two operations in a row, one masked attention that only looks at the last k timesteps (for example, the last 7), and then a second masked attention that only looks at every kth timestep. So, at the end of the second operation, each point has pulled information from points at checkpoints 7, 14, 21 steps ago, and each of these has pulled information from the window between it and its preceding checkpoint, giving visibility into a full global receptive frame in the course of two operations (2) The second, called the “fixed” version, uses a similar sort of logic, but instead of having the “window accumulation points” be defined in reference to the point doing the querying, you instead have fixed accumulation points responsible for gathering information from the windows around them. So, using the example given in the paper, if you imagine a window of size 128, and an “accumulation points per window” of 8, then the points in indices 120-128 (say) would have visibility into points 0-128. That represents the first operation, and in the second one, all other points in the sequence pull in information by querying the designated accumulation points for all the windows that aren’t masked for it. The paper argues that, between these two systems, the Strided system should work best when the data has some inherent periodicity, but I don’t know that I particularly follow that intuition. I have some sense that the important distinction here is that in the strided case you have many points of accumulation, each with not much context, whereas in the fixed case you have very few accumulation points each with a larger window, but I don’t know what performance differences exactly I’d expect these mechanical differences to predict. This whole project of reducing access to global information seems initially a little counterintuitive, since the whole point of a transformer design, in some sense, was its ability to gain global context in a single layer, as opposed to a convnet needing multiple layers to build receptive field, or a RNN needing to maintain state throughout the sequence. However, I think this paper makes the most sense as a way of interpolating the space between something like a CNN and a full attention design, for the sake of efficiency. With a CNN, you have a fixed kernel, and so as your sequence gets longer, you need to add more and more layers in order for any given point to be able to incorporate into its representation information from the complete other side of the sequence. With a RNN, as your sequence gets longers, you pay the cost of needing to backpropogate state farther. So, by contrast, even though the Sparse Transformer seems to be giving up its signal advantage, it’s instead just trading one constant number of steps to achieve global visibility (1), for another (2, in this paper, but conceptually could be more), but still in a way that’s constant with respect to the length of the data. And, in exchange for this trade, they get very sparse, very masked operations, where many of the multiplications involved in these big query calculations can be ignored, making for faster computation speeds. On the datasets tried, the Sparse Transformer increased speed, and in fact in I think all cases increased performance - not by much, the performance gain by itself isn’t that dramatic, but in the context of expecting if anything worse performance as a result of limiting model structure, it’s encouraging and interesting that it either stays about the same or possible improves. |
Unsupervised Data Augmentation
Xie, Qizhe and Dai, Zihang and Hovy, Eduard H. and Luong, Minh-Thang and Le, Quoc V.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Xie, Qizhe and Dai, Zihang and Hovy, Eduard H. and Luong, Minh-Thang and Le, Quoc V.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper focuses on taking advances from the (mostly heuristic, practical) world of data augmentation for supervised learning, and applying those to the unsupervised setting, as a way of inducing better performance in a semi-supervised environment (with many unlabeled points, and few labeled ones) Data augmentation has been a mostly behind-the-scenes implementation detail in modern deep learning: minor modifications like shifting a dataset by a few pixels, rotating it slightly, or flipping it horizontally, to generate additional pseudoexamples for the model to train on. The core idea motivating such approaches is that the tactics of data augmentation are modifications that should not change the class label in a platonic, ground truth sense, which allows us to use them as training examples of the same class label as the original image from which the perturbations were made. In addition to just giving then network generically more data, this approach communicates to the network the specific kinds of modifications that can be made to an image and have it still be of the same class. The Unsupervised Data Augmentation (UDA) tactic from this paper notices two things: (1) Within the sphere of supervised learning, there has been dataset-specific innovation in generating augmented data that will be particularly helpful to a given dataset. Inlanguage modeling, an example of this is having a sentence go into another language and back again through two well-trained translation networks, and use the resulting sentence as another example of the same class. For ImageNet, there’s an approach called AutoAugment that uses reinforcement learning on a validation set to learn a policy of image operations (rotate, shear, change color) in order to increase validation accuracy. [I am a little confused about this as an approach, since I worry about essentially overfitting to the validation set. That said, I don’t have time to delve specifically into the AutoAugment paper today, so I’ll just leave this here as a caveat] (2) Within semi-supervised learning, there’s a growing tendency to use consistency loss as a way of making use of unlabeled data. The basic idea of consistency loss is that, even if you don’t know the class of a given datapoint, if you modify it in some small way, you can be confident that the model’s prediction should be consistent between the point and its perturbation, even if you don’t have knowledge of what the actual ground truth is. Often, systems like this have been designed using simple Gaussian noise on top of original unlabeled images. The key proposal of this paper is to substitute this more simplified perturbation procedure with the augmentation approaches being iterated on in supervised learning, since the goal of both - to modify inputs so as to capture ways in which they might differ but still be notionally of the same class - is nearly identical On top of this core idea, the UDA paper also proposes an additional clever training tactic: in cases where you have many unlabeled examples and few labeled ones, you may need a large model to capture the information from the unlabeled examples, but this may result in overfitting on the labeled ones. To avoid this, they use an approach called “Training Signal Annealing,” where at each point in training they remove from the loss calculation any examples that the model is particularly confident about: where the prediction of the true class is above some threshold eta. As training goes on, the network is gradually allowed to see more of the training signals. In this kind of a framework, the model can’t overfit as easily, because once it starts getting the right answer on supervised examples, they drop out of the loss calculation. In terms of empirical results, the authors find that in UDA they’re able to improve on many semi-supervised benchmarks with quite small numbers of labeled examples. At one point, they use as a baseline a BERT model that was fine-tuned in an unsupervised way prior to its semi-supervised training, and show that their augmentation method can add value even on top of the value that the unsupervised pre-training adds. |
Counterpoint by Convolution
Huang, Cheng-Zhi Anna and Cooijmans, Tim and Roberts, Adam and Courville, Aaron C. and Eck, Douglas
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Huang, Cheng-Zhi Anna and Cooijmans, Tim and Roberts, Adam and Courville, Aaron C. and Eck, Douglas
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
The Magenta group at Google is a consistent source of really interesting problems for machine learning to solve, in the vein of creative generation of art and music, as well as mathematically creative ways to solve those problem. In this paper, they tackle a new problem with some interesting model-structural implications: generating Bach chorales composed of polyphonic multi-instrument arrangements. On one layer, this is similar to music generation problems that have been studied before, in that generating a musically coherent sequence requires learning both local and larger-scale structure between time steps in the music sequence. However, an additional element here is that there’s dependence of multiple instruments’ notes on one another at a given time step, so, in addition to generating time steps conditional on one another, you ideally want to learn how to model certain notes in a given harmony conditional on the other notes already present there. Understanding the specifics of the approach was one of those scenarios where the mathematical arguments were somewhat opaque, but the actual mechanical description of the model gave a lot of clarity. I find this frequently the case with machine learning, where there’s this strange set of dual incentives between the engineering impulse towards designing effective system, and the academic need to connect the approach to a more theoretical mathematical foundation. The approach taken here has a lot in common with the autoregressive model structures used in PixelCNN or WaveNet. These are all based, theoretically speaking, on the autoregressive property of joint probability distributions, that they can sampled from by sampling first from the prior over the first variable (or pixel, or wave value), and then the second conditional on the first, then the third conditional on the first two, and so on. In practice, autoregressive models don’t necessary condition on the *entire* previous rest of the input in generating a conditional distribution for a new point (for example, because they use a convolutional structure that doesn’t have a receptive field big enough to reach back through the entire previous sequence), but they are based on that idea. A unique aspect of this model is that, instead of defining one specific conditional dependence relationship (where pixel J is conditioned on wave values J-5 through J, or some such), they argue that they instead learn conditional relationships over any possible autoregressive ordering of both time steps and instrument IDs. This is a bit of a strange idea, that, like I mentioned, is simplified by going through the mechanics. The model works in a way strikingly similar to recent large scale language modeling: by, for each sample, masking some random subset of the tokens, and asking the model to predict the masked values given the unmasked ones. In this case, an interesting nuance is that the values to be masked are randomly sampled across both time step and instrument, such that in some cases you’ll have a prior time step but no other instruments at your time step, or other instruments at your time step but no prior time steps to work from, and so on. The model needs to flexibly use various kinds of local context to predict the notes that are masked. (As an aside, in addition to the actual values, the network is given the actual 0/1 mask, so it can better distinguish between “0, no information” and “0 because in the actual data sample there wasn’t a pitch here”.) The model refers to these unmasked points as “context points”. An interesting capacity that this gives the model, and which the authors use as their sampling technique, is to create songs that are hybrids of existing chorales by randomly keeping some chunks and dropping out others, and using the model to interpolate through the missing bits. |
Attention is not Explanation
Jain, Sarthak and Wallace, Byron C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Jain, Sarthak and Wallace, Byron C.
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
Attention mechanisms are a common subcomponent within language models, initially as a part of recurrent models, and more recently as their own form of aggregating information over sequences, independent from the recurrence structure. Attention works by taking as input some sequence of inputs, in the most typical case embedded representations of words in a sentence, and learning a distribution of weights over those representations, which allows the network to aggregate the representations, typically by taking a weighted sum. One effect of using an attention mechanism is that, for each instance being predicted, the network produces this weight distribution over inputs, which intuitively feels like it’s the network demonstrating which input words were most important in constructing its decision. As a result, uses of attention have often been accompanied by examples that show attention distributions for examples, implicitly using them as a form of interpretability or model explanation. This paper has the goal of understanding whether attention distributions can be seen as a valid form of feature importance, and takes the position that they shouldn’t be. At a high level, I think the paper makes some valid criticisms, but ultimately I didn’t find the evidence it presented quite as strong as I would have liked. The paper performs two primary analyses of the attention distributions produced by a trained LSTM model: (1) It calculates the level of correlation between the importance that would be implied by attention weights and the importance as calculated using more canonical gradient-based methods (generally things in the shape of “which words contributed the most towards the prediction being what it was). It finds correlation values that range across random seeds, but are generally centered around 0.5. The paper frames this as a negative result, implying that, in the case where attention was a valid form of importance, the correlation with existing metrics would be higher. I definitely follow the intuition that you would expect there be a significant and positive correlation between methods in this class, but it’s unclear to me what a priori reasoning chooses to draw the threshold on “significant” in a way that makes 0.5 fall below it. It just feels like one of those cases where I could imagine someone showing the same plots and coming to a different interpretation, and it’s not clear to me what criteria support one threshold of magnitude vs another (2) It measures how much it can permute the weights of an attention distribution, and have the prediction made by the network not change in a meaningful way. It does this both by random tests, and also by measuring the maximum adversarial perturbation: the farthest-away distribution (in terms of Jenson-Shannon distance) that still produces a prediction within some epsilon of the original prediction. There are a few concerns I have about this as an analysis. First off, it makes a bit of an assumption that attention can only be a valid form of explanation if it’s a causal mechanism within the model. You could imagine that attention distributions still give you information about the internal state of the model, even if they are just reporting that state rather than directly influencing it. Secondly, it seems possible to me that you could get a relatively high Jenson-Shannon distance from an initial distribution just by permuting the indexes of the low-value weights, and shifting distributional weight between them in a way that doesn’t fundamentally change what the network is primarily attending to. Even if this is not the case in this paper, I’d love to see an example or some kind of quantitative measure showing that the J-S Shannon distances they demonstrate require a substantive change in weight priorities, rather than a trivial one. Another general critique is that the experiments in this paper only focused on attention within a LSTM structure, where the embedding associated with each word isn’t really strictly an embedding of that specific word, but also contains a lot of information about things before and after, because of the nature of a BiLSTM. So, there is some specificity in the embedding corresponding to just that word, but a lot less than in a pure attention model, like some being used in NLP these days, where you’re learning an attention distribution over the raw, non-LSTM-ed representations. In this case, it makes sense that attention would be blurry, and not map exactly to our notions of which words are more important, since the word level representations are themselves already aggregations. I think it’s totally fair to only focus on the LSTM case, but would prefer the paper scoped its claims in better accordance with its empirical results. I feel a bit bad: overall, I really approve of papers like this being done to put a critical empirical frame on ML’s tendency to get conceptually ahead of itself. And, I do think that the evidentiary standard for “prove that X metric isn’t a form of interpretability” shouldn’t be that high, becuase on priors, I would expect most things not to be. I think that they may well be right in their assessment, I would just like a more surefooteded set of analyses and interpretation behind it. |
Model-Based Reinforcement Learning for Atari
Lukasz Kaiser and Mohammad Babaeizadeh and Piotr Milos and Blazej Osinski and Roy H Campbell and Konrad Czechowski and Dumitru Erhan and Chelsea Finn and Piotr Kozakowski and Sergey Levine and Ryan Sepassi and George Tucker and Henryk Michalewski
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/03/01 (5 years ago)
Abstract: Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.
more
less
Lukasz Kaiser and Mohammad Babaeizadeh and Piotr Milos and Blazej Osinski and Roy H Campbell and Konrad Czechowski and Dumitru Erhan and Chelsea Finn and Piotr Kozakowski and Sergey Levine and Ryan Sepassi and George Tucker and Henryk Michalewski
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/03/01 (5 years ago)
Abstract: Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.
|
[link]
This paper shows exciting results on using Model-based RL for Atari.
Model-based RL has shown impressive improvements in sample efficiency on Mujoco tasks ([Chua et. al, 2018](https://arxiv.org/abs/1805.12114)), so its nice to see that the sample efficiency improvements carry over to Pixel-based envs like Atari too.
Specifically, the authors show that their model-based method can do well on several Atari games after training on only 100K env steps (400K frames with FrameSkip 4) which roughly corresponds to 2 hours of game play. They compare to SOTA model-free variants (Rainbow, PPO) after similar number of frames and show that the model-based version achieves much better scores.
The overall training procedure has a very Dyna like flavor. The algorithm, termed SimPLe follows an iterative scheme of:
* Collect experience from the real environment using a policy (initialized to random).
* Use this experience to train the world model (a next-step frame prediction model, and a reward prediction model). This amounts to supervised learning on `{(s, a) -> s’}` and `{(s, a) -> r}` pairs.
* Generate rollouts using the world model, and learn a policy with these rollouts using PPO.
https://i.imgur.com/SZLmdME.png
**Countering distributional shift:**
A key issue when training models is compounding errors when doing multi-step rollouts. This is similar to the problem of making predictions with RNNs trained via teacher-forcing, and hence it's natural to leverage existing techniques from that literature.
This paper uses one such technique: scheduled sampling, that is during training randomly replace some frames of the input by the prediction from the previous step. This seems like a natural way to make the model robust to slight distributional changes.
**Commentary / possible future work:**
* The paper evaluated only on 26 out of 60 Atari games in ALE. I would have really liked if the authors showed performance numbers on all the games even if they weren’t good.
* Related: I suspect the method would not work well when the initial diversity of frames given by the random policy is not sufficient (ex. Sparse reward games like Montezuma’s revenge/Pitfall). Using sample efficient exploration algorithms to augment model learning would be really interesting.
* The trained world-model is able to rollout only for 50 time-steps (compounding errors don't allow for longer rollouts), it might be worthwhile to explore models that can do long-horizon predictions [(TD-VAE?)](https://openreview.net/forum?id=S1x4ghC9tQ).
* Apart from sample-efficiency gains, one reason I am excited about models is their potential ability to generalize to different tasks in the same environment. Benchmarking their generalization capability should thus be an exciting next step.
Finally, props to authors for open-sourcing the code: [tensor2tensor/tensor2tensor/rl at master · tensorflow/tensor2tensor · GitHub](https://github.com/tensorflow/tensor2tensor/tree/master/tensor2tensor/rl) and providing detailed instructions to run.
|

Centroid Networks for Few-Shot Clustering and Unsupervised Few-Shot Classification
Gabriel Huang and Hugo Larochelle and Simon Lacoste-Julien
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/02/22 (5 years ago)
Abstract: Traditional clustering algorithms such as K-means rely heavily on the nature of the chosen metric or data representation. To get meaningful clusters, these representations need to be tailored to the downstream task (e.g. cluster photos by object category, cluster faces by identity). Therefore, we frame clustering as a meta-learning task, few-shot clustering, which allows us to specify how to cluster the data at the meta-training level, despite the clustering algorithm itself being unsupervised. We propose Centroid Networks, a simple and efficient few-shot clustering method based on learning representations which are tailored both to the task to solve and to its internal clustering module. We also introduce unsupervised few-shot classification, which is conceptually similar to few-shot clustering, but is strictly harder than supervised* few-shot classification and therefore allows direct comparison with existing supervised few-shot classification methods. On Omniglot and miniImageNet, our method achieves accuracy competitive with popular supervised few-shot classification algorithms, despite using *no labels* from the support set. We also show performance competitive with state-of-the-art learning-to-cluster methods.
more
less
Gabriel Huang and Hugo Larochelle and Simon Lacoste-Julien
arXiv e-Print archive - 2019 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2019/02/22 (5 years ago)
Abstract: Traditional clustering algorithms such as K-means rely heavily on the nature of the chosen metric or data representation. To get meaningful clusters, these representations need to be tailored to the downstream task (e.g. cluster photos by object category, cluster faces by identity). Therefore, we frame clustering as a meta-learning task, few-shot clustering, which allows us to specify how to cluster the data at the meta-training level, despite the clustering algorithm itself being unsupervised. We propose Centroid Networks, a simple and efficient few-shot clustering method based on learning representations which are tailored both to the task to solve and to its internal clustering module. We also introduce unsupervised few-shot classification, which is conceptually similar to few-shot clustering, but is strictly harder than supervised* few-shot classification and therefore allows direct comparison with existing supervised few-shot classification methods. On Omniglot and miniImageNet, our method achieves accuracy competitive with popular supervised few-shot classification algorithms, despite using *no labels* from the support set. We also show performance competitive with state-of-the-art learning-to-cluster methods.
|
[link]
Disclaimer: I am the first author. # Executive summary - The authors propose a new method, [*Centroid Networks*](https://arxiv.org/pdf/1902.08605.pdf), for learning to cluster. - Given example clusterings of data, the goal is to learn how to cluster new data following the same criterion. - Centroid Networks basically consist of running K-means on Prototypical Network features, plus many tricks. - They evaluate Centroid Networks on Omniglot and miniImageNet (supervised few-shot classification benchmarks). - Centroid Networks can compete with Prototypical Networks (state of the art in supervised few-shot classification) despite using no supervision at evaluation time (the labels of the support set are completely ignored). ## Pros * **Simple training** (non end-to-end, very similar to prototypical networks, with additional tricks). * **Very fast clustering** (nearly same running time as prototypical networks). * The authors claim that the Sinkhorn K-means formulation is empirically very stable : any initialization is fine as long as symmetries are broken (in practice, they initialize all centroids at 0 and add a small gaussian noise to centroids at each step). ## Cons * Clusters **need to be balanced** now. Removing the balanced constraint is future work. # Setting - They frame learning to cluster as a meta-learning problem, **few-shot clustering**. - The goal is to cluster K*M images into K clusters of M images. - Classes vary across tasks, but class semantics are the same (Omniglot: cluster by character, miniImageNet: cluster by object category). - They also define a second task **unsupervised few-shot classification** solely for comparing with supervised few-shot classification methods. # Method Conceptually, Centroid Networks consist of training *Prototypical Networks* (meta-training), then running *K-means* on top of protonet representations at clustering time (meta-evaluation). However, the authors propose several tricks that significantly improve upon that baseline: - **Center loss**: when pretraining, this extra regularization term penalizes the intra-class variance. - **Sinkhorn assignments**: when pretraining, replace the softmax predictions p(y|x) with a formulation based on optimal transport (Sinkhorn distances). - **Sinkhorn K-means**: at clustering time, run the Sinkhorn K-means algorithm on the learned representation # Results on Few-Shot Classification Benchmarks: - The task is **unsupervised few-shot classification**: cluster a *unlabeled* support set, then predict which clusters new images should be classified into. - Target metric is **unsupervised accuracy**. - *Unsupervised* few-shot classification is harder than *supervised* few-shot classification because *no labels* are given in the support set. - Compare with reference oracle Prototypical networks, which can access labeled support set. - Centroid Networks are almost as good as Protonets on Omniglot (99.1% vs. reference 99.7%) - Centroid Networks are comparable to Protonets on miniImageNet (53.1% vs. reference 66.9%). - The proposed "tricks" are useful because Centroid Networks beats K-Means (Protonet feature) baseline. https://i.imgur.com/acQpQeq.png https://i.imgur.com/FlHf9Ko.png # Results on Learning to Cluster Benchmarks: - The task is **few-shot clustering**. After training on 30 alphabets of Omniglot, the task is to cluster 20 new alphabets (20-47 characters, with 20 instances/character). - Target metric is **clustering accuracy**. - Centroid Networks beat all flavors of Constrained Clustering Networks (86.6% vs. 83.3%) - Centroid Networks are about 100 times than CCN faster but less flexible (fixed cluster sizes). https://i.imgur.com/PvH5V1W.png # Code The code is available at https://github.com/gabrielhuang/centroid-networks |

BioBERT: a pre-trained biomedical language representation model for biomedical text mining
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
|
[link]
The paper discusses the idea of using BERT pre-trained network in bio-medical domain NLP tasks. It lays a path for future applications of Bert in different business verticals. Sharing some points from the review article I wrote on BioBERT on medium (https://medium.com/@raghudeep/biobert-insights-b4c66fde8fa7). The major contribution is a pre-trained bio-medical language representation model for various bio-medical text mining tasks. Tasks such as NER from Bio-medical data, relation extraction, question & answer in the biomedical field. For pretraining the model, authors have used a combination of general & medical corpora, which has shown interesting results. They have compared the results of all their combinations. |
